 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing VAEs and Normalizing Flows for One-shot Text-To-Speech Synthesis of Expressive Speech
Paper and Code
Nov 28, 2019
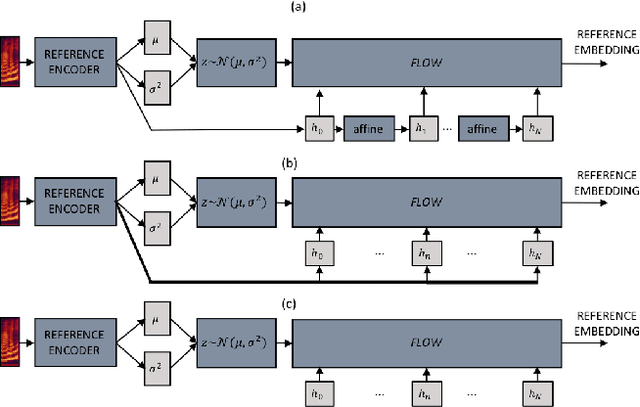


We propose a Text-to-Speech method to create an unseen expressive style using one utterance of expressive speech of around one second. Specifically, we enhance the disentanglement capabilities of a state-of-the-art sequence-to-sequence based system with a Variational AutoEncoder (VAE) and a Householder Flow. The proposed system provides a 22% KL-divergence reduction while jointly improving perceptual metrics over state-of-the-art. At synthesis time we use one example of expressive style as a reference input to the encoder for generating any text in the desired style. Perceptual MUSHRA evaluations show that we can create a voice with a 9% relative naturalness improvement over standard Neural Text-to-Speech, while also improving the perceived emotional intensity (59 compared to the 55 of neutral speech).