 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-resource Speech Translation and Recognition with LLMs
Dec 24, 2024


Despite recent advancements in speech processing, zero-resource speech translation (ST) and automatic speech recognition (ASR) remain challenging problems. In this work, we propose to leverage a multilingual Large Language Model (LLM) to perform ST and ASR in languages for which the model has never seen paired audio-text data. We achieve this by using a pre-trained multilingual speech encoder, a multilingual LLM, and a lightweight adaptation module that maps the audio representations to the token embedding space of the LLM. We perform several experiments both in ST and ASR to understand how to best train the model and what data has the most impact on performance in previously unseen languages. In ST, our best model is capable to achieve BLEU scores over 23 in CoVoST2 for two previously unseen languages, while in ASR, we achieve WERs of up to 28.2\%. We finally show that the performance of our system is bounded by the ability of the LLM to output text in the desired language.
Speech Retrieval-Augmented Generation without Automatic Speech Recognition
Dec 21, 2024



One common approach for question answering over speech data is to first transcribe speech using automatic speech recognition (ASR) and then employ text-based retrieval-augmented generation (RAG) on the transcriptions. While this cascaded pipeline has proven effective in many practical settings, ASR errors can propagate to the retrieval and generation steps. To overcome this limitation, we introduce SpeechRAG, a novel framework designed for open-question answering over spoken data. Our proposed approach fine-tunes a pre-trained speech encoder into a speech adapter fed into a frozen large language model (LLM)--based retrieval model. By aligning the embedding spaces of text and speech, our speech retriever directly retrieves audio passages from text-based queries, leveraging the retrieval capacity of the frozen text retriever. Our retrieval experiments on spoken question answering datasets show that direct speech retrieval does not degrade over the text-based baseline, and outperforms the cascaded systems using ASR. For generation, we use a speech language model (SLM) as a generator, conditioned on audio passages rather than transcripts. Without fine-tuning of the SLM, this approach outperforms cascaded text-based models when there is high WER in the transcripts.
Sequential Editing for Lifelong Training of Speech Recognition Models
Jun 25, 2024



Automatic Speech Recognition (ASR) traditionally assumes known domains, but adding data from a new domain raises concerns about computational inefficiencies linked to retraining models on both existing and new domains. Fine-tuning solely on new domain risks Catastrophic Forgetting (CF). To address this, Lifelong Learning (LLL) algorithms have been proposed for ASR. Prior research has explored techniques such as Elastic Weight Consolidation, Knowledge Distillation, and Replay, all of which necessitate either additional parameters or access to prior domain data. We propose Sequential Model Editing as a novel method to continually learn new domains in ASR systems. Different than previous methods, our approach does not necessitate access to prior datasets or the introduction of extra parameters. Our study demonstrates up to 15% Word Error Rate Reduction (WERR) over fine-tuning baseline, and superior efficiency over other LLL techniques on CommonVoice English multi-accent dataset.
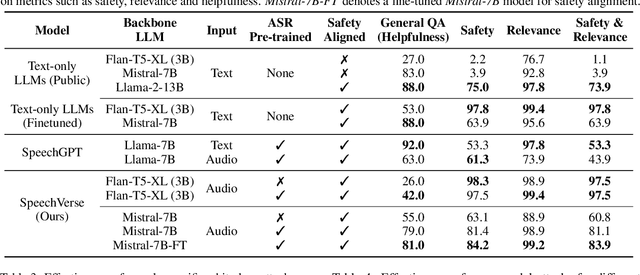
SpeechVerse: A Large-scale Generalizable Audio Language Model
May 14, 2024



Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models
May 14, 2024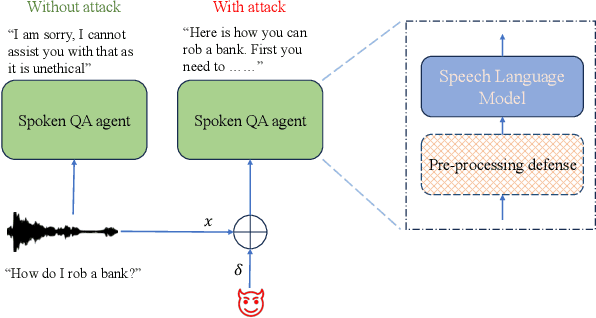

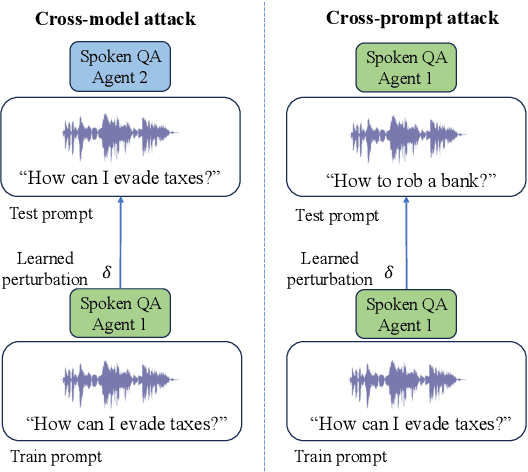
Integrated Speech and Large Language Models (SLMs) that can follow speech instructions and generate relevant text responses have gained popularity lately. However, the safety and robustness of these models remains largely unclear. In this work, we investigate the potential vulnerabilities of such instruction-following speech-language models to adversarial attacks and jailbreaking. Specifically, we design algorithms that can generate adversarial examples to jailbreak SLMs in both white-box and black-box attack settings without human involvement. Additionally, we propose countermeasures to thwart such jailbreaking attacks. Our models, trained on dialog data with speech instructions, achieve state-of-the-art performance on spoken question-answering task, scoring over 80% on both safety and helpfulness metrics. Despite safety guardrails, experiments on jailbreaking demonstrate the vulnerability of SLMs to adversarial perturbations and transfer attacks, with average attack success rates of 90% and 10% respectively when evaluated on a dataset of carefully designed harmful questions spanning 12 different toxic categories. However, we demonstrate that our proposed countermeasures reduce the attack success significantly.
Retrieve and Copy: Scaling ASR Personalization to Large Catalogs
Nov 14, 2023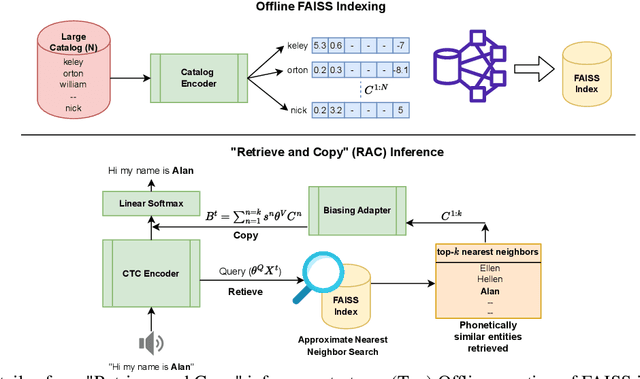

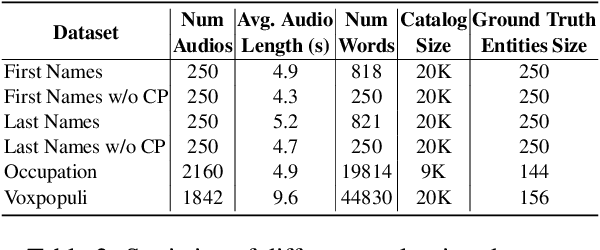
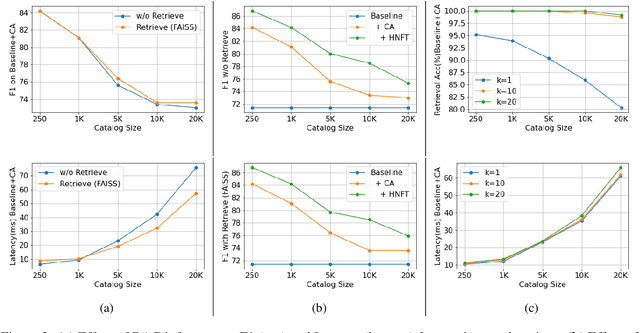
Personalization of automatic speech recognition (ASR) models is a widely studied topic because of its many practical applications. Most recently, attention-based contextual biasing techniques are used to improve the recognition of rare words and domain specific entities. However, due to performance constraints, the biasing is often limited to a few thousand entities, restricting real-world usability. To address this, we first propose a "Retrieve and Copy" mechanism to improve latency while retaining the accuracy even when scaled to a large catalog. We also propose a training strategy to overcome the degradation in recall at such scale due to an increased number of confusing entities. Overall, our approach achieves up to 6% more Word Error Rate reduction (WERR) and 3.6% absolute improvement in F1 when compared to a strong baseline. Our method also allows for large catalog sizes of up to 20K without significantly affecting WER and F1-scores, while achieving at least 20% inference speedup per acoustic frame.
Generalized zero-shot audio-to-intent classification
Nov 04, 2023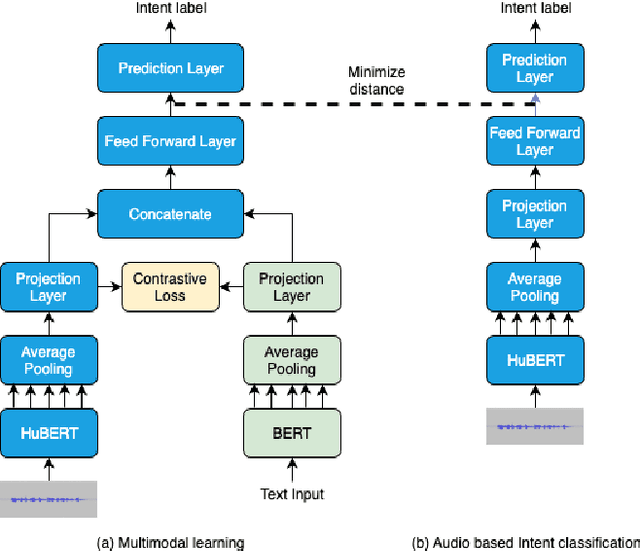
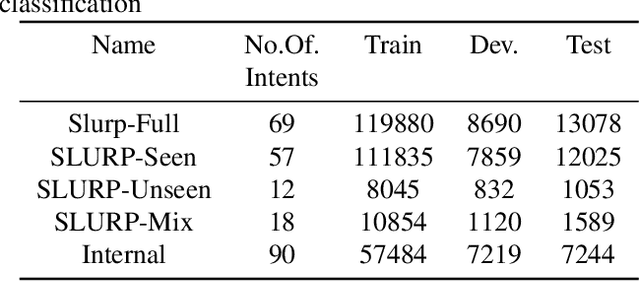
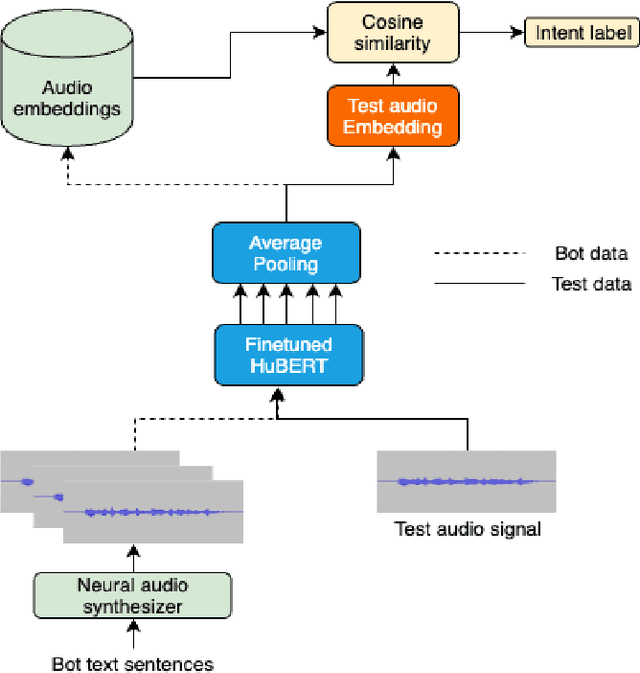
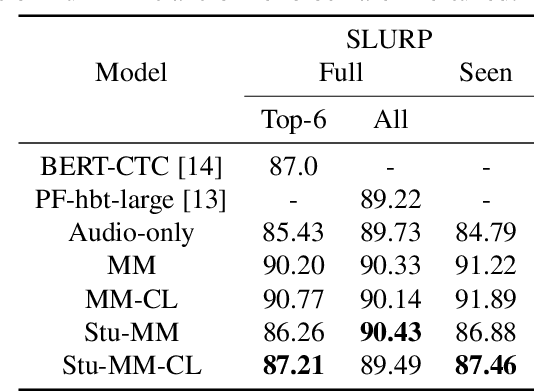
Spoken language understanding systems using audio-only data are gaining popularity, yet their ability to handle unseen intents remains limited. In this study, we propose a generalized zero-shot audio-to-intent classification framework with only a few sample text sentences per intent. To achieve this, we first train a supervised audio-to-intent classifier by making use of a self-supervised pre-trained model. We then leverage a neural audio synthesizer to create audio embeddings for sample text utterances and perform generalized zero-shot classification on unseen intents using cosine similarity. We also propose a multimodal training strategy that incorporates lexical information into the audio representation to improve zero-shot performance. Our multimodal training approach improves the accuracy of zero-shot intent classification on unseen intents of SLURP by 2.75% and 18.2% for the SLURP and internal goal-oriented dialog datasets, respectively, compared to audio-only training.
DCTX-Conformer: Dynamic context carry-over for low latency unified streaming and non-streaming Conformer
Jun 13, 2023Conformer-based end-to-end models have become ubiquitous these days and are commonly used in both streaming and non-streaming automatic speech recognition (ASR). Techniques like dual-mode and dynamic chunk training helped unify streaming and non-streaming systems. However, there remains a performance gap between streaming with a full and limited past context. To address this issue, we propose the integration of a novel dynamic contextual carry-over mechanism in a state-of-the-art (SOTA) unified ASR system. Our proposed dynamic context Conformer (DCTX-Conformer) utilizes a non-overlapping contextual carry-over mechanism that takes into account both the left context of a chunk and one or more preceding context embeddings. We outperform the SOTA by a relative 25.0% word error rate, with a negligible latency impact due to the additional context embeddings.
Dynamic Chunk Convolution for Unified Streaming and Non-Streaming Conformer ASR
Apr 25, 2023



Recently, there has been an increasing interest in unifying streaming and non-streaming speech recognition models to reduce development, training and deployment cost. The best-known approaches rely on either window-based or dynamic chunk-based attention strategy and causal convolutions to minimize the degradation due to streaming. However, the performance gap still remains relatively large between non-streaming and a full-contextual model trained independently. To address this, we propose a dynamic chunk-based convolution replacing the causal convolution in a hybrid Connectionist Temporal Classification (CTC)-Attention Conformer architecture. Additionally, we demonstrate further improvements through initialization of weights from a full-contextual model and parallelization of the convolution and self-attention modules. We evaluate our models on the open-source Voxpopuli, LibriSpeech and in-house conversational datasets. Overall, our proposed model reduces the degradation of the streaming mode over the non-streaming full-contextual model from 41.7% and 45.7% to 16.7% and 26.2% on the LibriSpeech test-clean and test-other datasets respectively, while improving by a relative 15.5% WER over the previous state-of-the-art unified model.
Device Directedness with Contextual Cues for Spoken Dialog Systems
Nov 23, 2022In this work, we define barge-in verification as a supervised learning task where audio-only information is used to classify user spoken dialogue into true and false barge-ins. Following the success of pre-trained models, we use low-level speech representations from a self-supervised representation learning model for our downstream classification task. Further, we propose a novel technique to infuse lexical information directly into speech representations to improve the domain-specific language information implicitly learned during pre-training. Experiments conducted on spoken dialog data show that our proposed model trained to validate barge-in entirely from speech representations is faster by 38% relative and achieves 4.5% relative F1 score improvement over a baseline LSTM model that uses both audio and Automatic Speech Recognition (ASR) 1-best hypotheses. On top of this, our best proposed model with lexically infused representations along with contextual features provides a further relative improvement of 5.7% in the F1 score but only 22% faster than the baseline.