 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask The Bias: Improving Domain-Adaptive Generalization of CTC-based ASR with Internal Language Model Estimation
May 05, 2023
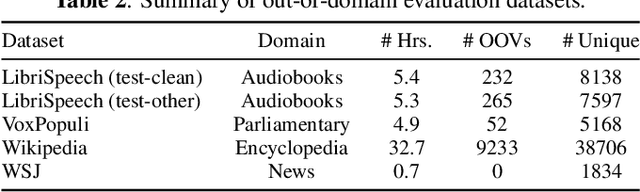
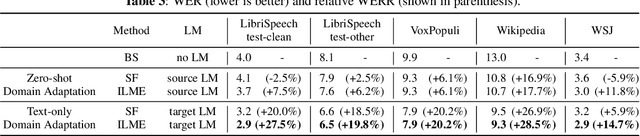
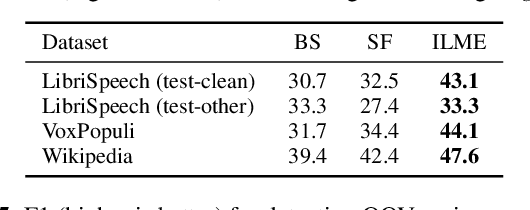
End-to-end ASR models trained on large amount of data tend to be implicitly biased towards language semantics of the training data. Internal language model estimation (ILME) has been proposed to mitigate this bias for autoregressive models such as attention-based encoder-decoder and RNN-T. Typically, ILME is performed by modularizing the acoustic and language components of the model architecture, and eliminating the acoustic input to perform log-linear interpolation with the text-only posterior. However, for CTC-based ASR, it is not as straightforward to decouple the model into such acoustic and language components, as CTC log-posteriors are computed in a non-autoregressive manner. In this work, we propose a novel ILME technique for CTC-based ASR models. Our method iteratively masks the audio timesteps to estimate a pseudo log-likelihood of the internal LM by accumulating log-posteriors for only the masked timesteps. Extensive evaluation across multiple out-of-domain datasets reveals that the proposed approach improves WER by up to 9.8% and OOV F1-score by up to 24.6% relative to Shallow Fusion, when only text data from target domain is available. In the case of zero-shot domain adaptation, with no access to any target domain data, we demonstrate that removing the source domain bias with ILME can still outperform Shallow Fusion to improve WER by up to 9.3% relative.
Dynamic Chunk Convolution for Unified Streaming and Non-Streaming Conformer ASR
Apr 25, 2023



Recently, there has been an increasing interest in unifying streaming and non-streaming speech recognition models to reduce development, training and deployment cost. The best-known approaches rely on either window-based or dynamic chunk-based attention strategy and causal convolutions to minimize the degradation due to streaming. However, the performance gap still remains relatively large between non-streaming and a full-contextual model trained independently. To address this, we propose a dynamic chunk-based convolution replacing the causal convolution in a hybrid Connectionist Temporal Classification (CTC)-Attention Conformer architecture. Additionally, we demonstrate further improvements through initialization of weights from a full-contextual model and parallelization of the convolution and self-attention modules. We evaluate our models on the open-source Voxpopuli, LibriSpeech and in-house conversational datasets. Overall, our proposed model reduces the degradation of the streaming mode over the non-streaming full-contextual model from 41.7% and 45.7% to 16.7% and 26.2% on the LibriSpeech test-clean and test-other datasets respectively, while improving by a relative 15.5% WER over the previous state-of-the-art unified model.
Personalization of CTC Speech Recognition Models
Oct 18, 2022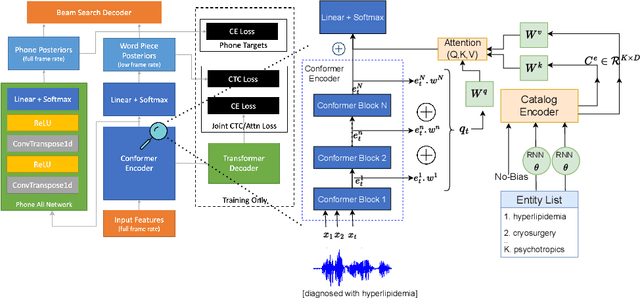
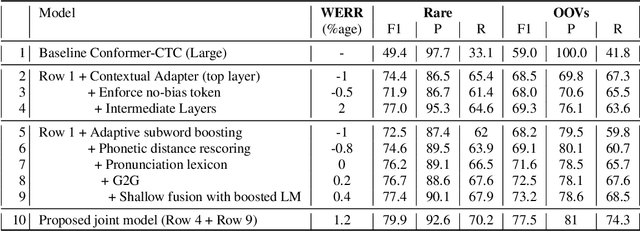
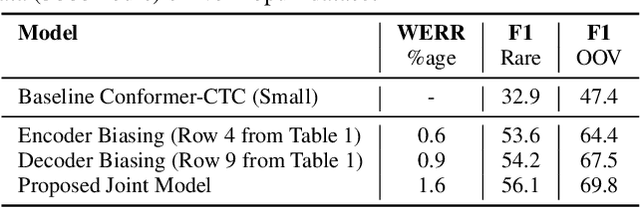
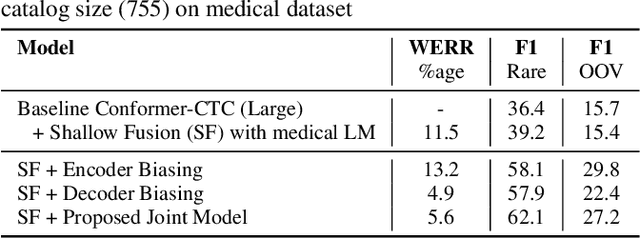
End-to-end speech recognition models trained using joint Connectionist Temporal Classification (CTC)-Attention loss have gained popularity recently. In these models, a non-autoregressive CTC decoder is often used at inference time due to its speed and simplicity. However, such models are hard to personalize because of their conditional independence assumption that prevents output tokens from previous time steps to influence future predictions. To tackle this, we propose a novel two-way approach that first biases the encoder with attention over a predefined list of rare long-tail and out-of-vocabulary (OOV) words and then uses dynamic boosting and phone alignment network during decoding to further bias the subword predictions. We evaluate our approach on open-source VoxPopuli and in-house medical datasets to showcase a 60% improvement in F1 score on domain-specific rare words over a strong CTC baseline.