 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalization of CTC Speech Recognition Models
Paper and Code
Oct 18, 2022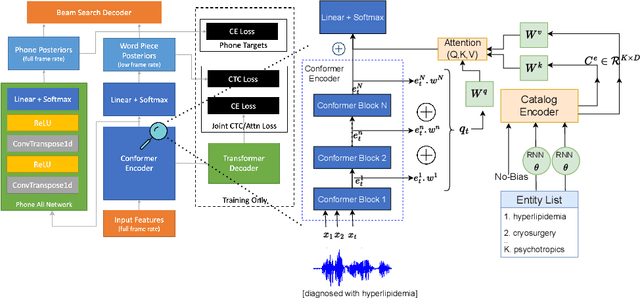
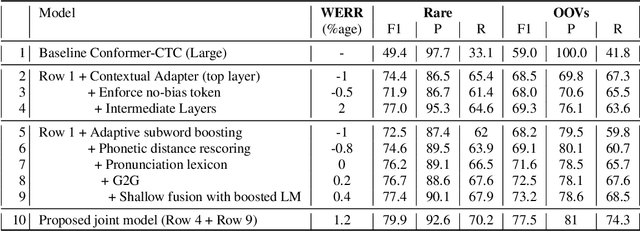
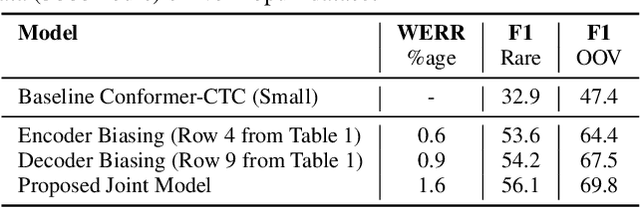
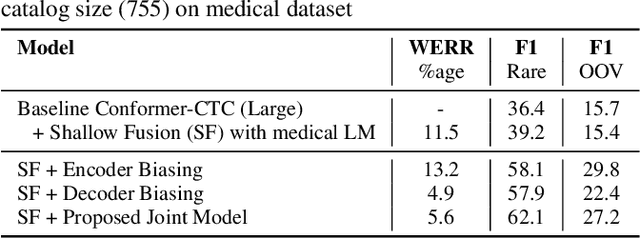
End-to-end speech recognition models trained using joint Connectionist Temporal Classification (CTC)-Attention loss have gained popularity recently. In these models, a non-autoregressive CTC decoder is often used at inference time due to its speed and simplicity. However, such models are hard to personalize because of their conditional independence assumption that prevents output tokens from previous time steps to influence future predictions. To tackle this, we propose a novel two-way approach that first biases the encoder with attention over a predefined list of rare long-tail and out-of-vocabulary (OOV) words and then uses dynamic boosting and phone alignment network during decoding to further bias the subword predictions. We evaluate our approach on open-source VoxPopuli and in-house medical datasets to showcase a 60% improvement in F1 score on domain-specific rare words over a strong CTC baseline.