 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWanda++: Pruning Large Language Models via Regional Gradients
Mar 06, 2025Large Language Models (LLMs) pruning seeks to remove unimportant weights for inference speedup with minimal performance impact. However, existing methods often suffer from performance loss without full-model sparsity-aware fine-tuning. This paper presents Wanda++, a novel pruning framework that outperforms the state-of-the-art methods by utilizing decoder-block-level \textbf{regional} gradients. Specifically, Wanda++ improves the pruning score with regional gradients for the first time and proposes an efficient regional optimization method to minimize pruning-induced output discrepancies between the dense and sparse decoder output. Notably, Wanda++ improves perplexity by up to 32\% over Wanda in the language modeling task and generalizes effectively to downstream tasks. Further experiments indicate our proposed method is orthogonal to sparsity-aware fine-tuning, where Wanda++ can be combined with LoRA fine-tuning to achieve a similar perplexity improvement as the Wanda method. The proposed method is lightweight, pruning a 7B LLaMA model in under 10 minutes on a single NVIDIA H100 GPU.
Zero-resource Speech Translation and Recognition with LLMs
Dec 24, 2024


Despite recent advancements in speech processing, zero-resource speech translation (ST) and automatic speech recognition (ASR) remain challenging problems. In this work, we propose to leverage a multilingual Large Language Model (LLM) to perform ST and ASR in languages for which the model has never seen paired audio-text data. We achieve this by using a pre-trained multilingual speech encoder, a multilingual LLM, and a lightweight adaptation module that maps the audio representations to the token embedding space of the LLM. We perform several experiments both in ST and ASR to understand how to best train the model and what data has the most impact on performance in previously unseen languages. In ST, our best model is capable to achieve BLEU scores over 23 in CoVoST2 for two previously unseen languages, while in ASR, we achieve WERs of up to 28.2\%. We finally show that the performance of our system is bounded by the ability of the LLM to output text in the desired language.
Adaptive Video Understanding Agent: Enhancing efficiency with dynamic frame sampling and feedback-driven reasoning
Oct 26, 2024Understanding long-form video content presents significant challenges due to its temporal complexity and the substantial computational resources required. In this work, we propose an agent-based approach to enhance both the efficiency and effectiveness of long-form video understanding by utilizing large language models (LLMs) and their tool-harnessing ability. A key aspect of our method is query-adaptive frame sampling, which leverages the reasoning capabilities of LLMs to process only the most relevant frames in real-time, and addresses an important limitation of existing methods which typically involve sampling redundant or irrelevant frames. To enhance the reasoning abilities of our video-understanding agent, we leverage the self-reflective capabilities of LLMs to provide verbal reinforcement to the agent, which leads to improved performance while minimizing the number of frames accessed. We evaluate our method across several video understanding benchmarks and demonstrate that not only it enhances state-of-the-art performance but also improves efficiency by reducing the number of frames sampled.
SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models
May 14, 2024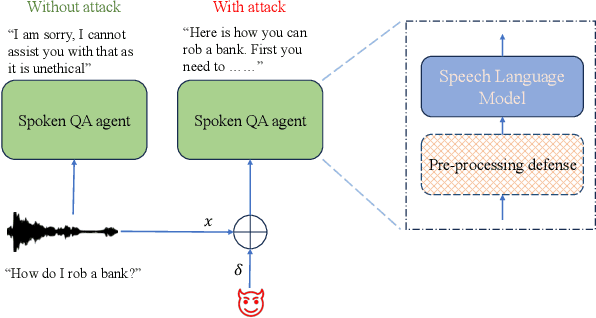

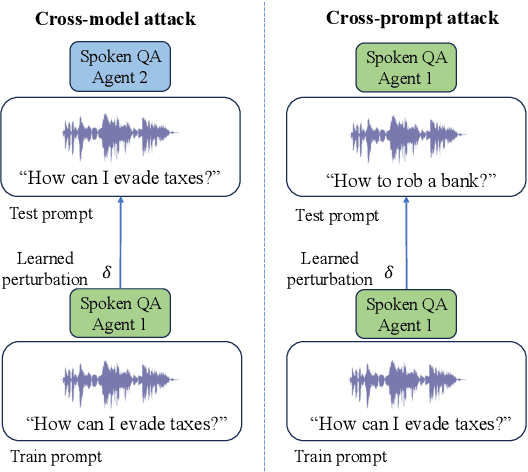
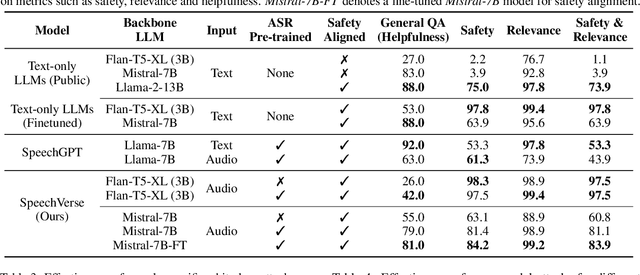
Integrated Speech and Large Language Models (SLMs) that can follow speech instructions and generate relevant text responses have gained popularity lately. However, the safety and robustness of these models remains largely unclear. In this work, we investigate the potential vulnerabilities of such instruction-following speech-language models to adversarial attacks and jailbreaking. Specifically, we design algorithms that can generate adversarial examples to jailbreak SLMs in both white-box and black-box attack settings without human involvement. Additionally, we propose countermeasures to thwart such jailbreaking attacks. Our models, trained on dialog data with speech instructions, achieve state-of-the-art performance on spoken question-answering task, scoring over 80% on both safety and helpfulness metrics. Despite safety guardrails, experiments on jailbreaking demonstrate the vulnerability of SLMs to adversarial perturbations and transfer attacks, with average attack success rates of 90% and 10% respectively when evaluated on a dataset of carefully designed harmful questions spanning 12 different toxic categories. However, we demonstrate that our proposed countermeasures reduce the attack success significantly.
DCTX-Conformer: Dynamic context carry-over for low latency unified streaming and non-streaming Conformer
Jun 13, 2023Conformer-based end-to-end models have become ubiquitous these days and are commonly used in both streaming and non-streaming automatic speech recognition (ASR). Techniques like dual-mode and dynamic chunk training helped unify streaming and non-streaming systems. However, there remains a performance gap between streaming with a full and limited past context. To address this issue, we propose the integration of a novel dynamic contextual carry-over mechanism in a state-of-the-art (SOTA) unified ASR system. Our proposed dynamic context Conformer (DCTX-Conformer) utilizes a non-overlapping contextual carry-over mechanism that takes into account both the left context of a chunk and one or more preceding context embeddings. We outperform the SOTA by a relative 25.0% word error rate, with a negligible latency impact due to the additional context embeddings.
Dynamic Chunk Convolution for Unified Streaming and Non-Streaming Conformer ASR
Apr 25, 2023



Recently, there has been an increasing interest in unifying streaming and non-streaming speech recognition models to reduce development, training and deployment cost. The best-known approaches rely on either window-based or dynamic chunk-based attention strategy and causal convolutions to minimize the degradation due to streaming. However, the performance gap still remains relatively large between non-streaming and a full-contextual model trained independently. To address this, we propose a dynamic chunk-based convolution replacing the causal convolution in a hybrid Connectionist Temporal Classification (CTC)-Attention Conformer architecture. Additionally, we demonstrate further improvements through initialization of weights from a full-contextual model and parallelization of the convolution and self-attention modules. We evaluate our models on the open-source Voxpopuli, LibriSpeech and in-house conversational datasets. Overall, our proposed model reduces the degradation of the streaming mode over the non-streaming full-contextual model from 41.7% and 45.7% to 16.7% and 26.2% on the LibriSpeech test-clean and test-other datasets respectively, while improving by a relative 15.5% WER over the previous state-of-the-art unified model.
Low-data? No problem: low-resource, language-agnostic conversational text-to-speech via F0-conditioned data augmentation
Jul 29, 2022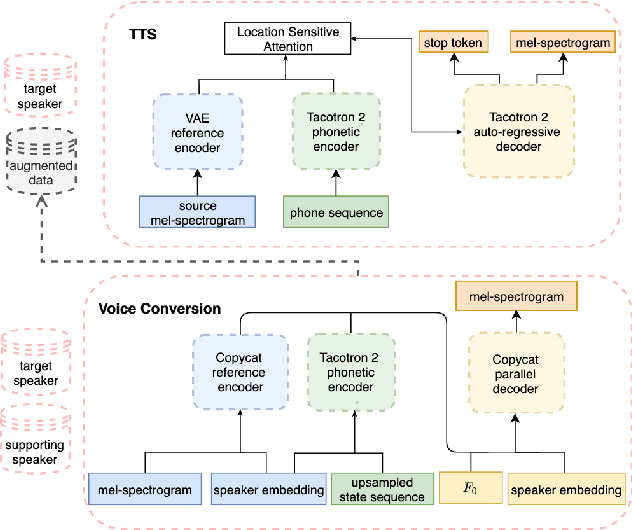

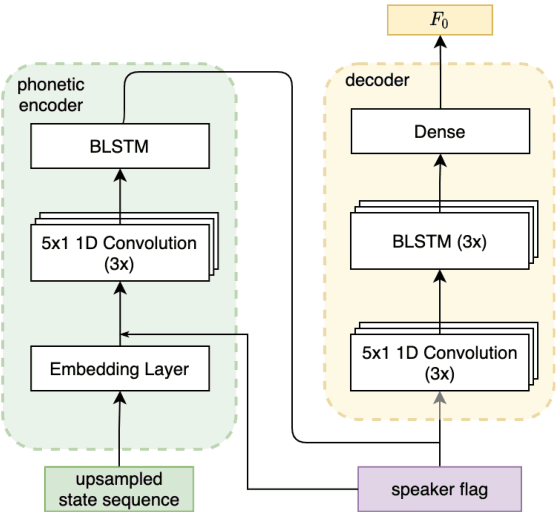
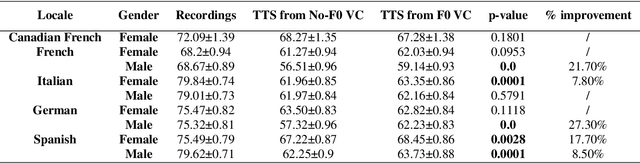
The availability of data in expressive styles across languages is limited, and recording sessions are costly and time consuming. To overcome these issues, we demonstrate how to build low-resource, neural text-to-speech (TTS) voices with only 1 hour of conversational speech, when no other conversational data are available in the same language. Assuming the availability of non-expressive speech data in that language, we propose a 3-step technology: 1) we train an F0-conditioned voice conversion (VC) model as data augmentation technique; 2) we train an F0 predictor to control the conversational flavour of the voice-converted synthetic data; 3) we train a TTS system that consumes the augmented data. We prove that our technology enables F0 controllability, is scalable across speakers and languages and is competitive in terms of naturalness over a state-of-the-art baseline model, another augmented method which does not make use of F0 information.
Voice Filter: Few-shot text-to-speech speaker adaptation using voice conversion as a post-processing module
Feb 16, 2022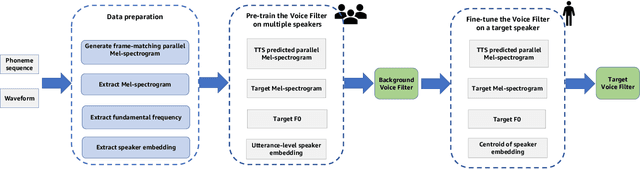

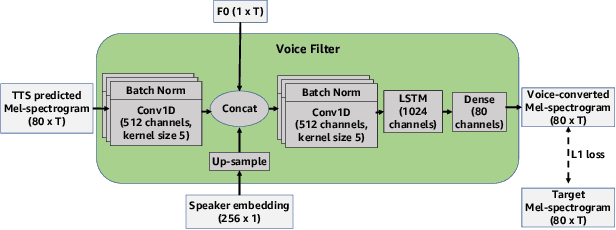

State-of-the-art text-to-speech (TTS) systems require several hours of recorded speech data to generate high-quality synthetic speech. When using reduced amounts of training data, standard TTS models suffer from speech quality and intelligibility degradations, making training low-resource TTS systems problematic. In this paper, we propose a novel extremely low-resource TTS method called Voice Filter that uses as little as one minute of speech from a target speaker. It uses voice conversion (VC) as a post-processing module appended to a pre-existing high-quality TTS system and marks a conceptual shift in the existing TTS paradigm, framing the few-shot TTS problem as a VC task. Furthermore, we propose to use a duration-controllable TTS system to create a parallel speech corpus to facilitate the VC task. Results show that the Voice Filter outperforms state-of-the-art few-shot speech synthesis techniques in terms of objective and subjective metrics on one minute of speech on a diverse set of voices, while being competitive against a TTS model built on 30 times more data.
Cross-speaker style transfer for text-to-speech using data augmentation
Feb 10, 2022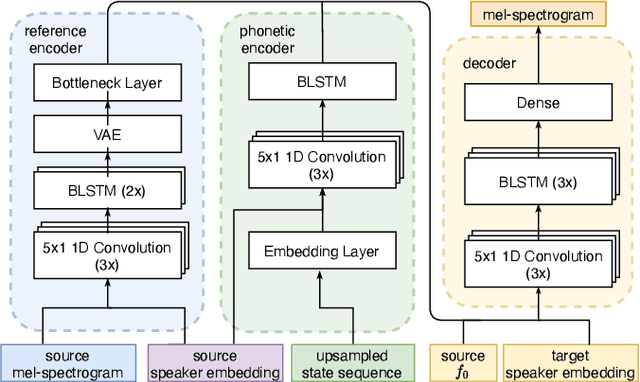
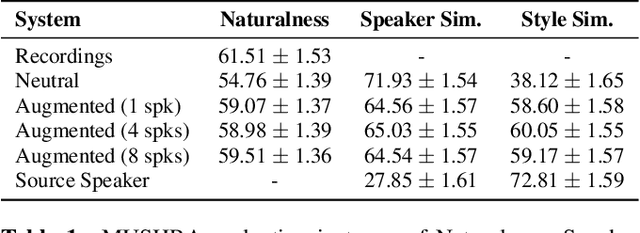
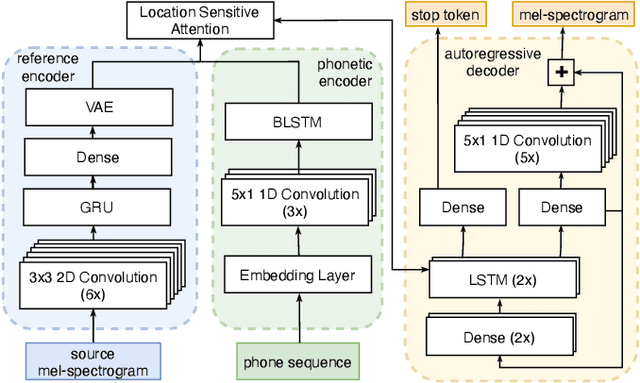
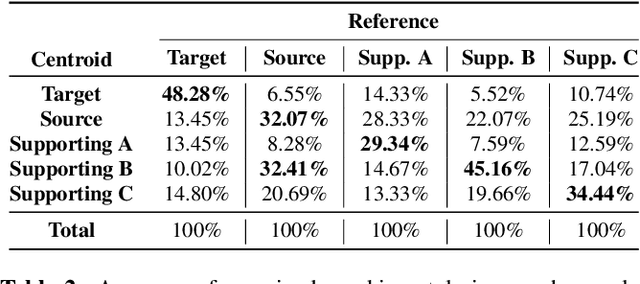
We address the problem of cross-speaker style transfer for text-to-speech (TTS) using data augmentation via voice conversion. We assume to have a corpus of neutral non-expressive data from a target speaker and supporting conversational expressive data from different speakers. Our goal is to build a TTS system that is expressive, while retaining the target speaker's identity. The proposed approach relies on voice conversion to first generate high-quality data from the set of supporting expressive speakers. The voice converted data is then pooled with natural data from the target speaker and used to train a single-speaker multi-style TTS system. We provide evidence that this approach is efficient, flexible, and scalable. The method is evaluated using one or more supporting speakers, as well as a variable amount of supporting data. We further provide evidence that this approach allows some controllability of speaking style, when using multiple supporting speakers. We conclude by scaling our proposed technology to a set of 14 speakers across 7 languages. Results indicate that our technology consistently improves synthetic samples in terms of style similarity, while retaining the target speaker's identity.
Non-Autoregressive TTS with Explicit Duration Modelling for Low-Resource Highly Expressive Speech
Jun 25, 2021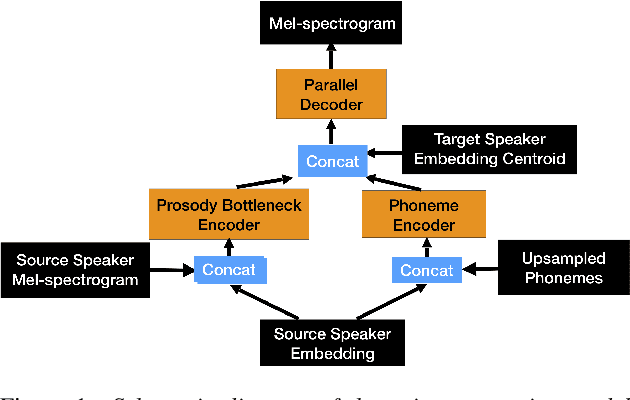
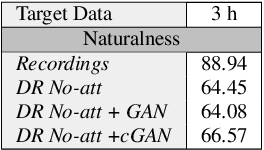

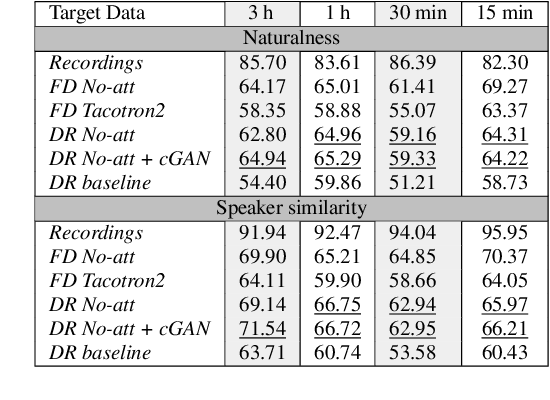
Whilst recent neural text-to-speech (TTS) approaches produce high-quality speech, they typically require a large amount of recordings from the target speaker. In previous work, a 3-step method was proposed to generate high-quality TTS while greatly reducing the amount of data required for training. However, we have observed a ceiling effect in the level of naturalness achievable for highly expressive voices when using this approach. In this paper, we present a method for building highly expressive TTS voices with as little as 15 minutes of speech data from the target speaker. Compared to the current state-of-the-art approach, our proposed improvements close the gap to recordings by 23.3% for naturalness of speech and by 16.3% for speaker similarity. Further, we match the naturalness and speaker similarity of a Tacotron2-based full-data (~10 hours) model using only 15 minutes of target speaker data, whereas with 30 minutes or more, we significantly outperform it. The following improvements are proposed: 1) changing from an autoregressive, attention-based TTS model to a non-autoregressive model replacing attention with an external duration model and 2) an additional Conditional Generative Adversarial Network (cGAN) based fine-tuning step.