 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpZO: Hybrid Sharpness-Aware Vision Language Model Prompt Tuning via Forward-Only Passes
Jun 26, 2025Fine-tuning vision language models (VLMs) has achieved remarkable performance across various downstream tasks; yet, it requires access to model gradients through backpropagation (BP), making them unsuitable for memory-constrained, inference-only edge devices. To address this limitation, previous work has explored various BP-free fine-tuning methods. However, these approaches often rely on high-variance evolutionary strategies (ES) or zeroth-order (ZO) optimization, and often fail to achieve satisfactory performance. In this paper, we propose a hybrid Sharpness-aware Zeroth-order optimization (SharpZO) approach, specifically designed to enhance the performance of ZO VLM fine-tuning via a sharpness-aware warm-up training. SharpZO features a two-stage optimization process: a sharpness-aware ES stage that globally explores and smooths the loss landscape to construct a strong initialization, followed by a fine-grained local search via sparse ZO optimization. The entire optimization relies solely on forward passes. Detailed theoretical analysis and extensive experiments on CLIP models demonstrate that SharpZO significantly improves accuracy and convergence speed, achieving up to 7% average gain over state-of-the-art forward-only methods.
Saten: Sparse Augmented Tensor Networks for Post-Training Compression of Large Language Models
May 20, 2025The efficient implementation of large language models (LLMs) is crucial for deployment on resource-constrained devices. Low-rank tensor compression techniques, such as tensor-train (TT) networks, have been widely studied for over-parameterized neural networks. However, their applications to compress pre-trained large language models (LLMs) for downstream tasks (post-training) remains challenging due to the high-rank nature of pre-trained LLMs and the lack of access to pretraining data. In this study, we investigate low-rank tensorized LLMs during fine-tuning and propose sparse augmented tensor networks (Saten) to enhance their performance. The proposed Saten framework enables full model compression. Experimental results demonstrate that Saten enhances both accuracy and compression efficiency in tensorized language models, achieving state-of-the-art performance.
SIFT-50M: A Large-Scale Multilingual Dataset for Speech Instruction Fine-Tuning
Apr 12, 2025We introduce SIFT (Speech Instruction Fine-Tuning), a 50M-example dataset designed for instruction fine-tuning and pre-training of speech-text large language models (LLMs). SIFT-50M is built from publicly available speech corpora, which collectively contain 14K hours of speech, and leverages LLMs along with off-the-shelf expert models. The dataset spans five languages, encompassing a diverse range of speech understanding as well as controllable speech generation instructions. Using SIFT-50M, we train SIFT-LLM, which outperforms existing speech-text LLMs on instruction-following benchmarks while achieving competitive performance on foundational speech tasks. To support further research, we also introduce EvalSIFT, a benchmark dataset specifically designed to evaluate the instruction-following capabilities of speech-text LLMs.
Wanda++: Pruning Large Language Models via Regional Gradients
Mar 06, 2025Large Language Models (LLMs) pruning seeks to remove unimportant weights for inference speedup with minimal performance impact. However, existing methods often suffer from performance loss without full-model sparsity-aware fine-tuning. This paper presents Wanda++, a novel pruning framework that outperforms the state-of-the-art methods by utilizing decoder-block-level \textbf{regional} gradients. Specifically, Wanda++ improves the pruning score with regional gradients for the first time and proposes an efficient regional optimization method to minimize pruning-induced output discrepancies between the dense and sparse decoder output. Notably, Wanda++ improves perplexity by up to 32\% over Wanda in the language modeling task and generalizes effectively to downstream tasks. Further experiments indicate our proposed method is orthogonal to sparsity-aware fine-tuning, where Wanda++ can be combined with LoRA fine-tuning to achieve a similar perplexity improvement as the Wanda method. The proposed method is lightweight, pruning a 7B LLaMA model in under 10 minutes on a single NVIDIA H100 GPU.
Accelerator-Aware Training for Transducer-Based Speech Recognition
May 12, 2023



Machine learning model weights and activations are represented in full-precision during training. This leads to performance degradation in runtime when deployed on neural network accelerator (NNA) chips, which leverage highly parallelized fixed-point arithmetic to improve runtime memory and latency. In this work, we replicate the NNA operators during the training phase, accounting for the degradation due to low-precision inference on the NNA in back-propagation. Our proposed method efficiently emulates NNA operations, thus foregoing the need to transfer quantization error-prone data to the Central Processing Unit (CPU), ultimately reducing the user perceived latency (UPL). We apply our approach to Recurrent Neural Network-Transducer (RNN-T), an attractive architecture for on-device streaming speech recognition tasks. We train and evaluate models on 270K hours of English data and show a 5-7% improvement in engine latency while saving up to 10% relative degradation in WER.
* Accepted to SLT 2022
Leveraging Redundancy in Multiple Audio Signals for Far-Field Speech Recognition
Mar 01, 2023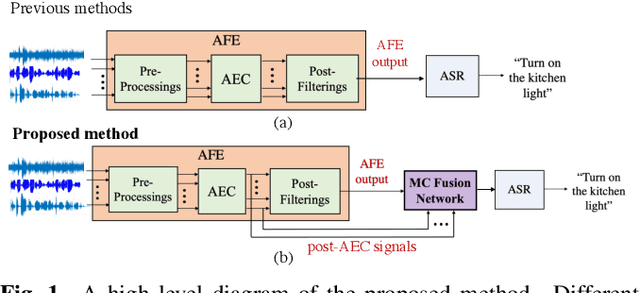

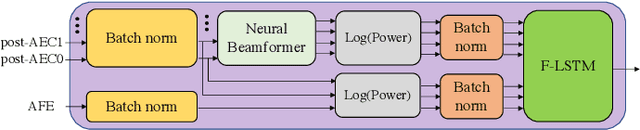
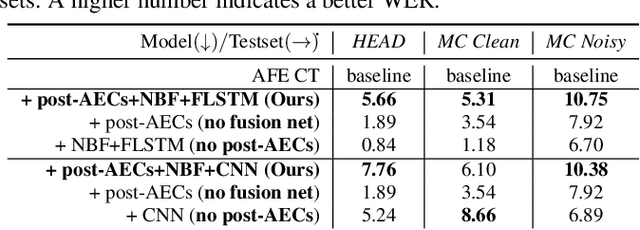
To achieve robust far-field automatic speech recognition (ASR), existing techniques typically employ an acoustic front end (AFE) cascaded with a neural transducer (NT) ASR model. The AFE output, however, could be unreliable, as the beamforming output in AFE is steered to a wrong direction. A promising way to address this issue is to exploit the microphone signals before the beamforming stage and after the acoustic echo cancellation (post-AEC) in AFE. We argue that both, post-AEC and AFE outputs, are complementary and it is possible to leverage the redundancy between these signals to compensate for potential AFE processing errors. We present two fusion networks to explore this redundancy and aggregate these multi-channel (MC) signals: (1) Frequency-LSTM based, and (2) Convolutional Neural Network based fusion networks. We augment the MC fusion networks to a conformer transducer model and train it in an end-to-end fashion. Our experimental results on commercial virtual assistant tasks demonstrate that using the AFE output and two post-AEC signals with fusion networks offers up to 25.9% word error rate (WER) relative improvement over the model using the AFE output only, at the cost of <= 2% parameter increase.
Contextual-Utterance Training for Automatic Speech Recognition
Oct 27, 2022



Recent studies of streaming automatic speech recognition (ASR) recurrent neural network transducer (RNN-T)-based systems have fed the encoder with past contextual information in order to improve its word error rate (WER) performance. In this paper, we first propose a contextual-utterance training technique which makes use of the previous and future contextual utterances in order to do an implicit adaptation to the speaker, topic and acoustic environment. Also, we propose a dual-mode contextual-utterance training technique for streaming automatic speech recognition (ASR) systems. This proposed approach allows to make a better use of the available acoustic context in streaming models by distilling "in-place" the knowledge of a teacher, which is able to see both past and future contextual utterances, to the student which can only see the current and past contextual utterances. The experimental results show that a conformer-transducer system trained with the proposed techniques outperforms the same system trained with the classical RNN-T loss. Specifically, the proposed technique is able to reduce both the WER and the average last token emission latency by more than 6% and 40ms relative, respectively.
ConvRNN-T: Convolutional Augmented Recurrent Neural Network Transducers for Streaming Speech Recognition
Sep 29, 2022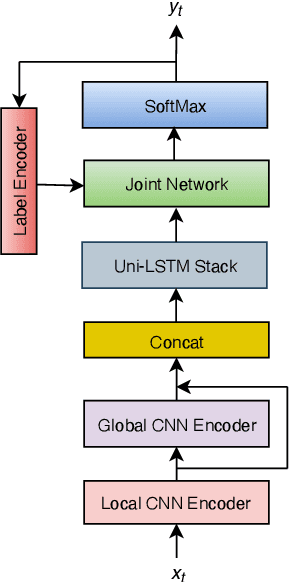
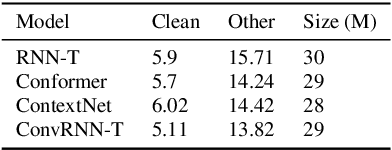
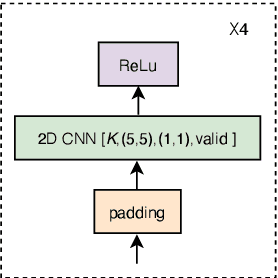

The recurrent neural network transducer (RNN-T) is a prominent streaming end-to-end (E2E) ASR technology. In RNN-T, the acoustic encoder commonly consists of stacks of LSTMs. Very recently, as an alternative to LSTM layers, the Conformer architecture was introduced where the encoder of RNN-T is replaced with a modified Transformer encoder composed of convolutional layers at the frontend and between attention layers. In this paper, we introduce a new streaming ASR model, Convolutional Augmented Recurrent Neural Network Transducers (ConvRNN-T) in which we augment the LSTM-based RNN-T with a novel convolutional frontend consisting of local and global context CNN encoders. ConvRNN-T takes advantage of causal 1-D convolutional layers, squeeze-and-excitation, dilation, and residual blocks to provide both global and local audio context representation to LSTM layers. We show ConvRNN-T outperforms RNN-T, Conformer, and ContextNet on Librispeech and in-house data. In addition, ConvRNN-T offers less computational complexity compared to Conformer. ConvRNN-T's superior accuracy along with its low footprint make it a promising candidate for on-device streaming ASR technologies.
CoDERT: Distilling Encoder Representations with Co-learning for Transducer-based Speech Recognition
Jun 14, 2021


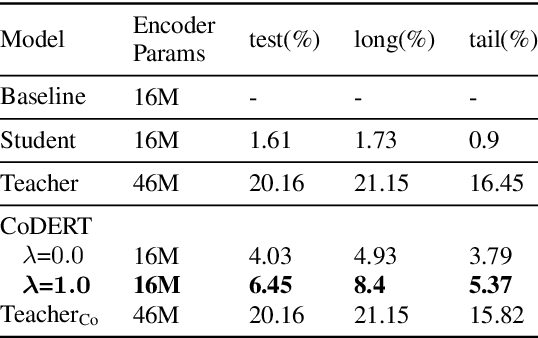
We propose a simple yet effective method to compress an RNN-Transducer (RNN-T) through the well-known knowledge distillation paradigm. We show that the transducer's encoder outputs naturally have a high entropy and contain rich information about acoustically similar word-piece confusions. This rich information is suppressed when combined with the lower entropy decoder outputs to produce the joint network logits. Consequently, we introduce an auxiliary loss to distill the encoder logits from a teacher transducer's encoder, and explore training strategies where this encoder distillation works effectively. We find that tandem training of teacher and student encoders with an inplace encoder distillation outperforms the use of a pre-trained and static teacher transducer. We also report an interesting phenomenon we refer to as implicit distillation, that occurs when the teacher and student encoders share the same decoder. Our experiments show 5.37-8.4% relative word error rate reductions (WERR) on in-house test sets, and 5.05-6.18% relative WERRs on LibriSpeech test sets.
Exploiting Large-scale Teacher-Student Training for On-device Acoustic Models
Jun 11, 2021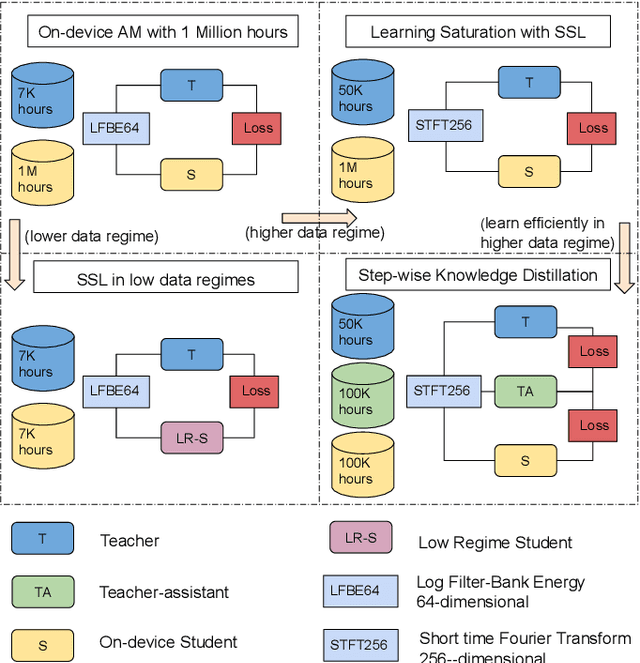
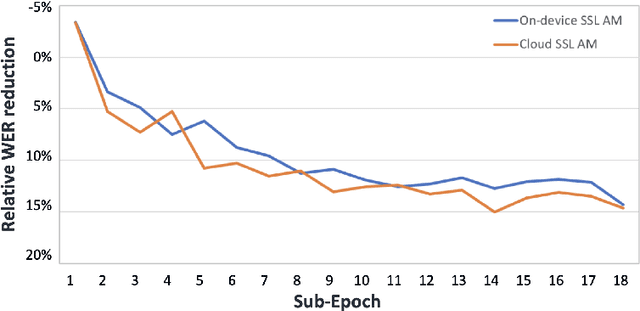
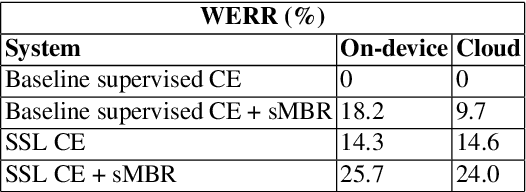
We present results from Alexa speech teams on semi-supervised learning (SSL) of acoustic models (AM) with experiments spanning over 3000 hours of GPU time, making our study one of the largest of its kind. We discuss SSL for AMs in a small footprint setting, showing that a smaller capacity model trained with 1 million hours of unsupervised data can outperform a baseline supervised system by 14.3% word error rate reduction (WERR). When increasing the supervised data to seven-fold, our gains diminish to 7.1% WERR; to improve SSL efficiency at larger supervised data regimes, we employ a step-wise distillation into a smaller model, obtaining a WERR of 14.4%. We then switch to SSL using larger student models in low data regimes; while learning efficiency with unsupervised data is higher, student models may outperform teacher models in such a setting. We develop a theoretical sketch to explain this behavior.