 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Large-scale Teacher-Student Training for On-device Acoustic Models
Jun 11, 2021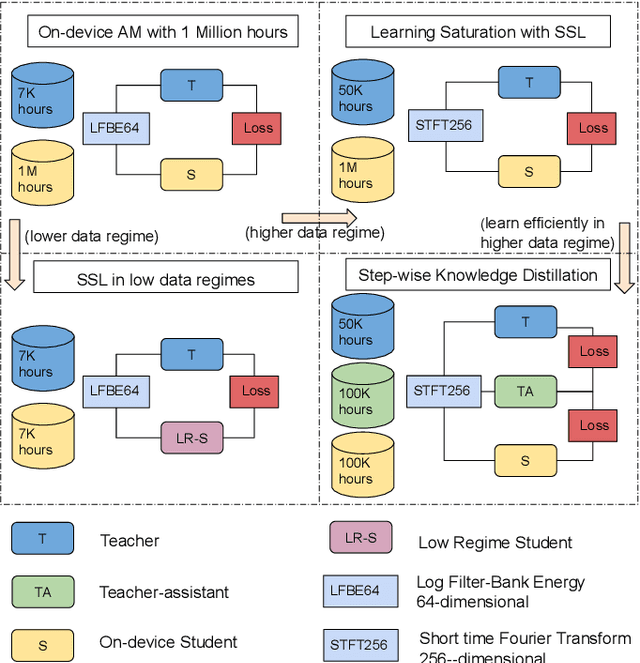
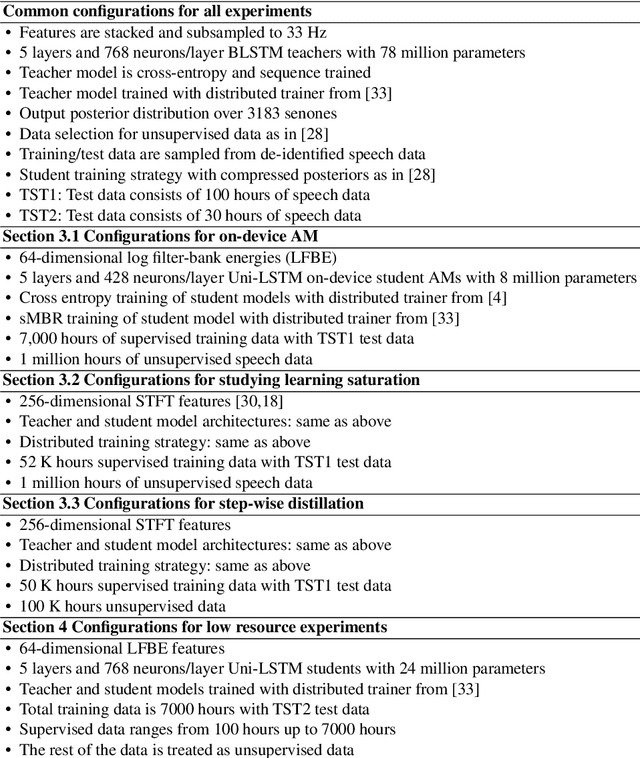
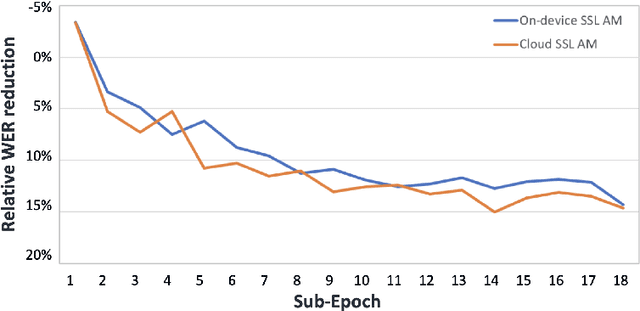
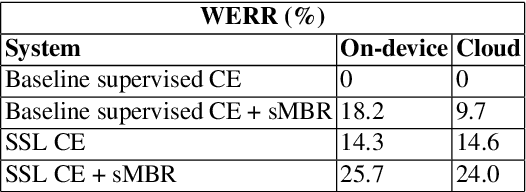
We present results from Alexa speech teams on semi-supervised learning (SSL) of acoustic models (AM) with experiments spanning over 3000 hours of GPU time, making our study one of the largest of its kind. We discuss SSL for AMs in a small footprint setting, showing that a smaller capacity model trained with 1 million hours of unsupervised data can outperform a baseline supervised system by 14.3% word error rate reduction (WERR). When increasing the supervised data to seven-fold, our gains diminish to 7.1% WERR; to improve SSL efficiency at larger supervised data regimes, we employ a step-wise distillation into a smaller model, obtaining a WERR of 14.4%. We then switch to SSL using larger student models in low data regimes; while learning efficiency with unsupervised data is higher, student models may outperform teacher models in such a setting. We develop a theoretical sketch to explain this behavior.
A Differentiable Relaxation of Graph Segmentation and Alignment for AMR Parsing
Oct 23, 2020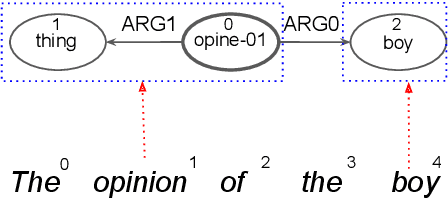
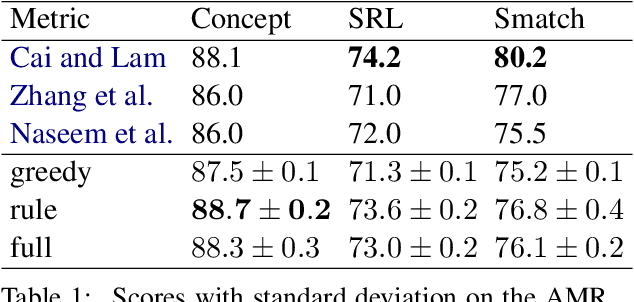
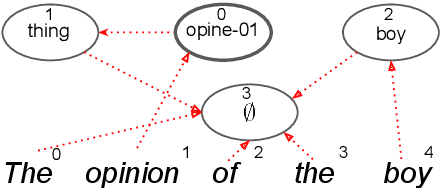
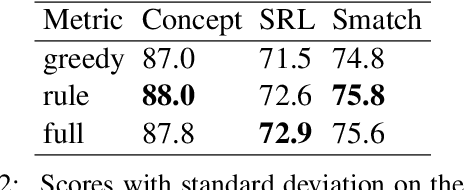
Abstract Meaning Representations (AMR) are a broad-coverage semantic formalism which represents sentence meaning as a directed acyclic graph. To train most AMR parsers, one needs to segment the graph into subgraphs and align each such subgraph to a word in a sentence; this is normally done at preprocessing, relying on hand-crafted rules. In contrast, we treat both alignment and segmentation as latent variables in our model and induce them as part of end-to-end training. As marginalizing over the structured latent variables is infeasible, we use the variational autoencoding framework. To ensure end-to-end differentiable optimization, we introduce a continuous differentiable relaxation of the segmentation and alignment problems. We observe that inducing segmentation yields substantial gains over using a `greedy' segmentation heuristic. The performance of our method also approaches that of a model that relies on \citet{Lyu2018AMRPA}'s segmentation rules, which were hand-crafted to handle individual AMR constructions.
Learning Two-Layer Residual Networks with Nonparametric Function Estimation by Convex Programming
Aug 17, 2020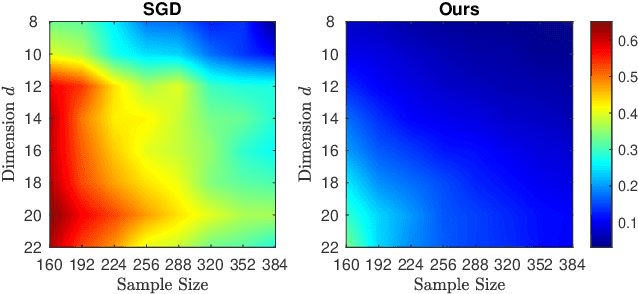
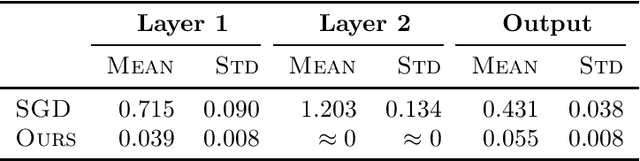
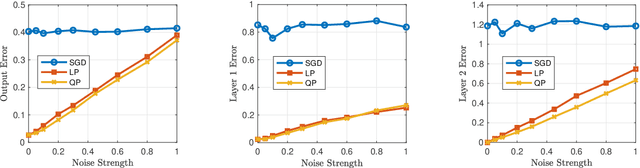
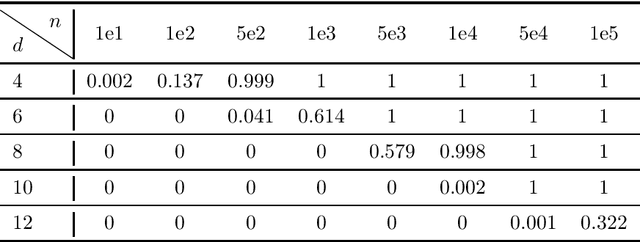
We focus on learning a two-layer residual neural network with preactivation by ReLU (preReLU-TLRN): Suppose the input $\mathbf{x}$ is from a distribution with support space $\mathbb{R}^d$ and the ground-truth generative model is a preReLU-TLRN, given by $$\mathbf{y} = \boldsymbol{B}^\ast\left[\left(\boldsymbol{A}^\ast\mathbf{x}\right)^+ + \mathbf{x}\right]\text{,}$$ where ground-truth network parameters $\boldsymbol{A}^\ast \in \mathbb{R}^{d\times d}$ is a nonnegative full-rank matrix and $\boldsymbol{B}^\ast \in \mathbb{R}^{m\times d}$ is full-rank with $m \geq d$. We design layerwise objectives as functionals whose analytic minimizers sufficiently express the exact ground-truth network in terms of its parameters and nonlinearities. Following this objective landscape, learning a preReLU-TLRN from finite samples can be formulated as convex programming with nonparametric function estimation: For each layer, we first formulate the corresponding empirical risk minimization (ERM) as convex quadratic programming (QP), then we show the solution space of the QP can be equivalently determined by a set of linear inequalities, which can then be efficiently solved by linear programming (LP). Experiments show the robustness and sample efficiency of our methods.
Capturing Argument Interaction in Semantic Role Labeling with Capsule Networks
Oct 07, 2019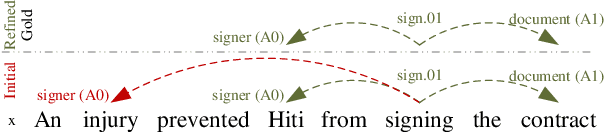
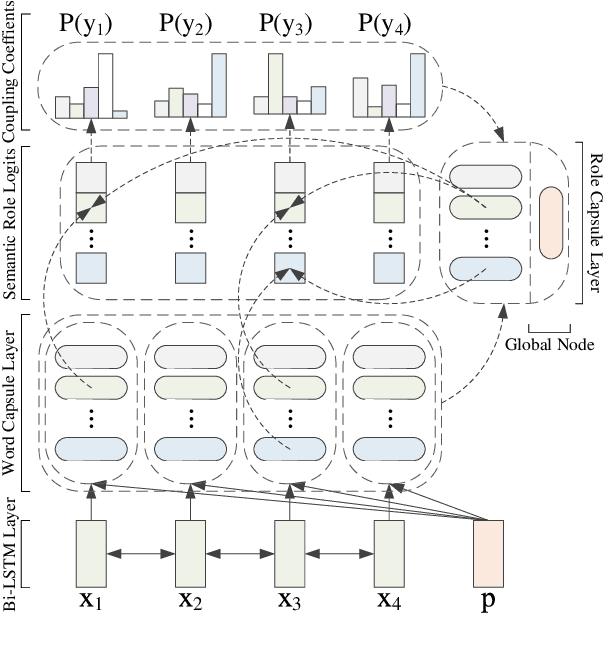
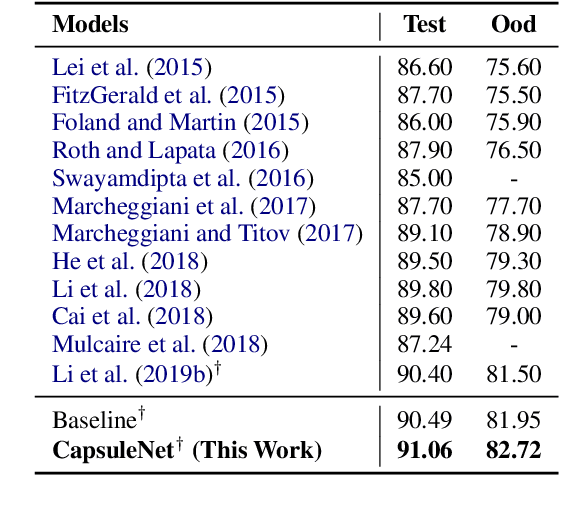
Semantic role labeling (SRL) involves extracting propositions (i.e. predicates and their typed arguments) from natural language sentences. State-of-the-art SRL models rely on powerful encoders (e.g., LSTMs) and do not model non-local interaction between arguments. We propose a new approach to modeling these interactions while maintaining efficient inference. Specifically, we use Capsule Networks: each proposition is encoded as a tuple of \textit{capsules}, one capsule per argument type (i.e. role). These tuples serve as embeddings of entire propositions. In every network layer, the capsules interact with each other and with representations of words in the sentence. Each iteration results in updated proposition embeddings and updated predictions about the SRL structure. Our model substantially outperforms the non-refinement baseline model on all 7 CoNLL-2019 languages and achieves state-of-the-art results on 5 languages (including English) for dependency SRL. We analyze the types of mistakes corrected by the refinement procedure. For example, each role is typically (but not always) filled with at most one argument. Whereas enforcing this approximate constraint is not useful with the modern SRL system, iterative procedure corrects the mistakes by capturing this intuition in a flexible and context-sensitive way.
Semantic Role Labeling with Iterative Structure Refinement
Sep 07, 2019
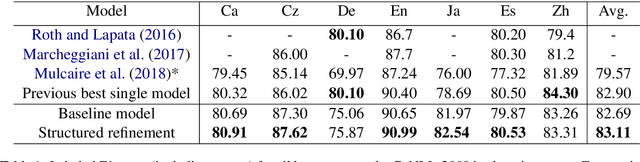
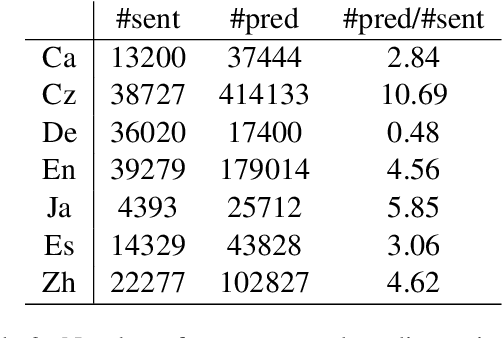
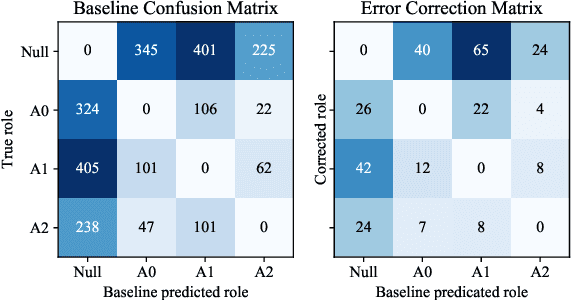
Modern state-of-the-art Semantic Role Labeling (SRL) methods rely on expressive sentence encoders (e.g., multi-layer LSTMs) but tend to model only local (if any) interactions between individual argument labeling decisions. This contrasts with earlier work and also with the intuition that the labels of individual arguments are strongly interdependent. We model interactions between argument labeling decisions through {\it iterative refinement}. Starting with an output produced by a factorized model, we iteratively refine it using a refinement network. Instead of modeling arbitrary interactions among roles and words, we encode prior knowledge about the SRL problem by designing a restricted network architecture capturing non-local interactions. This modeling choice prevents overfitting and results in an effective model, outperforming strong factorized baseline models on all 7 CoNLL-2009 languages, and achieving state-of-the-art results on 5 of them, including English.
AMR Parsing as Graph Prediction with Latent Alignment
May 14, 2018
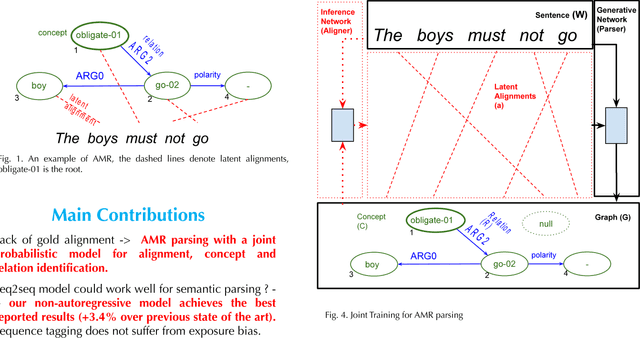
Abstract meaning representations (AMRs) are broad-coverage sentence-level semantic representations. AMRs represent sentences as rooted labeled directed acyclic graphs. AMR parsing is challenging partly due to the lack of annotated alignments between nodes in the graphs and words in the corresponding sentences. We introduce a neural parser which treats alignments as latent variables within a joint probabilistic model of concepts, relations and alignments. As exact inference requires marginalizing over alignments and is infeasible, we use the variational auto-encoding framework and a continuous relaxation of the discrete alignments. We show that joint modeling is preferable to using a pipeline of align and parse. The parser achieves the best reported results on the standard benchmark (74.4% on LDC2016E25).
A Unified Gradient Regularization Family for Adversarial Examples
Nov 19, 2015



Adversarial examples are augmented data points generated by imperceptible perturbation of input samples. They have recently drawn much attention with the machine learning and data mining community. Being difficult to distinguish from real examples, such adversarial examples could change the prediction of many of the best learning models including the state-of-the-art deep learning models. Recent attempts have been made to build robust models that take into account adversarial examples. However, these methods can either lead to performance drops or lack mathematical motivations. In this paper, we propose a unified framework to build robust machine learning models against adversarial examples. More specifically, using the unified framework, we develop a family of gradient regularization methods that effectively penalize the gradient of loss function w.r.t. inputs. Our proposed framework is appealing in that it offers a unified view to deal with adversarial examples. It incorporates another recently-proposed perturbation based approach as a special case. In addition, we present some visual effects that reveals semantic meaning in those perturbations, and thus support our regularization method and provide another explanation for generalizability of adversarial examples. By applying this technique to Maxout networks, we conduct a series of experiments and achieve encouraging results on two benchmark datasets. In particular,we attain the best accuracy on MNIST data (without data augmentation) and competitive performance on CIFAR-10 data.