 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaten: Sparse Augmented Tensor Networks for Post-Training Compression of Large Language Models
May 20, 2025The efficient implementation of large language models (LLMs) is crucial for deployment on resource-constrained devices. Low-rank tensor compression techniques, such as tensor-train (TT) networks, have been widely studied for over-parameterized neural networks. However, their applications to compress pre-trained large language models (LLMs) for downstream tasks (post-training) remains challenging due to the high-rank nature of pre-trained LLMs and the lack of access to pretraining data. In this study, we investigate low-rank tensorized LLMs during fine-tuning and propose sparse augmented tensor networks (Saten) to enhance their performance. The proposed Saten framework enables full model compression. Experimental results demonstrate that Saten enhances both accuracy and compression efficiency in tensorized language models, achieving state-of-the-art performance.
MaZO: Masked Zeroth-Order Optimization for Multi-Task Fine-Tuning of Large Language Models
Feb 17, 2025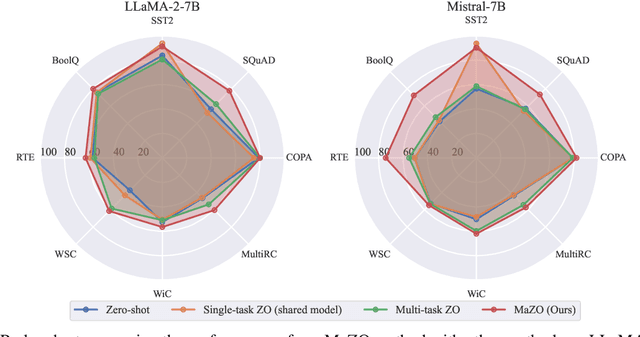
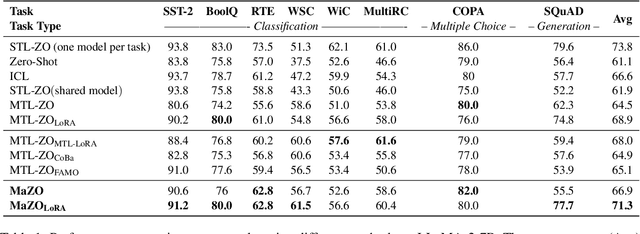
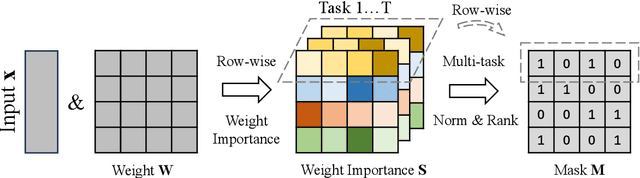

Large language models have demonstrated exceptional capabilities across diverse tasks, but their fine-tuning demands significant memory, posing challenges for resource-constrained environments. Zeroth-order (ZO) optimization provides a memory-efficient alternative by eliminating the need for backpropagation. However, ZO optimization suffers from high gradient variance, and prior research has largely focused on single-task learning, leaving its application to multi-task learning unexplored. Multi-task learning is crucial for leveraging shared knowledge across tasks to improve generalization, yet it introduces unique challenges under ZO settings, such as amplified gradient variance and collinearity. In this paper, we present MaZO, the first framework specifically designed for multi-task LLM fine-tuning under ZO optimization. MaZO tackles these challenges at the parameter level through two key innovations: a weight importance metric to identify critical parameters and a multi-task weight update mask to selectively update these parameters, reducing the dimensionality of the parameter space and mitigating task conflicts. Experiments demonstrate that MaZO achieves state-of-the-art performance, surpassing even multi-task learning methods designed for first-order optimization.
CoMERA: Computing- and Memory-Efficient Training via Rank-Adaptive Tensor Optimization
May 23, 2024



Training large AI models such as deep learning recommendation systems and foundation language (or multi-modal) models costs massive GPUs and computing time. The high training cost has become only affordable to big tech companies, meanwhile also causing increasing concerns about the environmental impact. This paper presents CoMERA, a Computing- and Memory-Efficient training method via Rank-Adaptive tensor optimization. CoMERA achieves end-to-end rank-adaptive tensor-compressed training via a multi-objective optimization formulation, and improves the training to provide both a high compression ratio and excellent accuracy in the training process. Our optimized numerical computation (e.g., optimized tensorized embedding and tensor-vector contractions) and GPU implementation eliminate part of the run-time overhead in the tensorized training on GPU. This leads to, for the first time, $2-3\times$ speedup per training epoch compared with standard training. CoMERA also outperforms the recent GaLore in terms of both memory and computing efficiency. Specifically, CoMERA is $2\times$ faster per training epoch and $9\times$ more memory-efficient than GaLore on a tested six-encoder transformer with single-batch training. With further HPC optimization, CoMERA may significantly reduce the training cost of large language models.
Quantization-Aware and Tensor-Compressed Training of Transformers for Natural Language Understanding
Jun 01, 2023
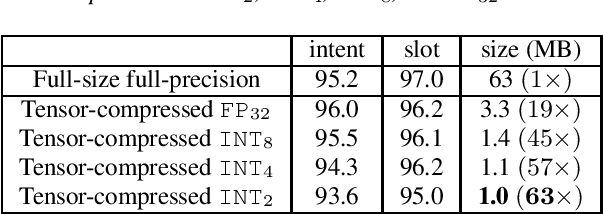
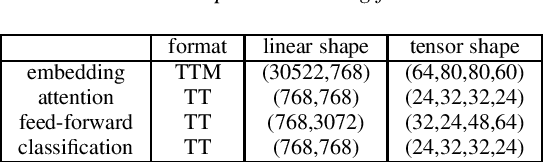
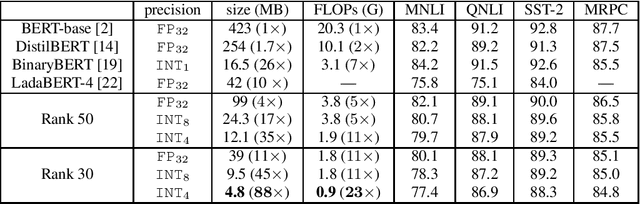
Fine-tuned transformer models have shown superior performances in many natural language tasks. However, the large model size prohibits deploying high-performance transformer models on resource-constrained devices. This paper proposes a quantization-aware tensor-compressed training approach to reduce the model size, arithmetic operations, and ultimately runtime latency of transformer-based models. We compress the embedding and linear layers of transformers into small low-rank tensor cores, which significantly reduces model parameters. A quantization-aware training with learnable scale factors is used to further obtain low-precision representations of the tensor-compressed models. The developed approach can be used for both end-to-end training and distillation-based training. To improve the convergence, a layer-by-layer distillation is applied to distill a quantized and tensor-compressed student model from a pre-trained transformer. The performance is demonstrated in two natural language understanding tasks, showing up to $63\times$ compression ratio, little accuracy loss and remarkable inference and training speedup.
Dual-Attention Neural Transducers for Efficient Wake Word Spotting in Speech Recognition
Apr 05, 2023



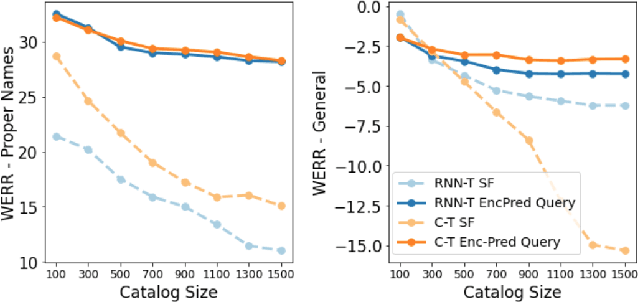
We present dual-attention neural biasing, an architecture designed to boost Wake Words (WW) recognition and improve inference time latency on speech recognition tasks. This architecture enables a dynamic switch for its runtime compute paths by exploiting WW spotting to select which branch of its attention networks to execute for an input audio frame. With this approach, we effectively improve WW spotting accuracy while saving runtime compute cost as defined by floating point operations (FLOPs). Using an in-house de-identified dataset, we demonstrate that the proposed dual-attention network can reduce the compute cost by $90\%$ for WW audio frames, with only $1\%$ increase in the number of parameters. This architecture improves WW F1 score by $16\%$ relative and improves generic rare word error rate by $3\%$ relative compared to the baselines.
Contextual Adapters for Personalized Speech Recognition in Neural Transducers
May 26, 2022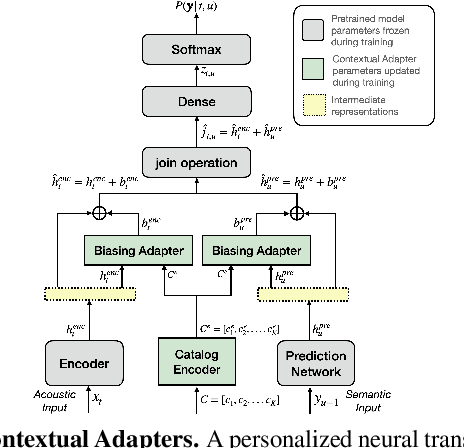
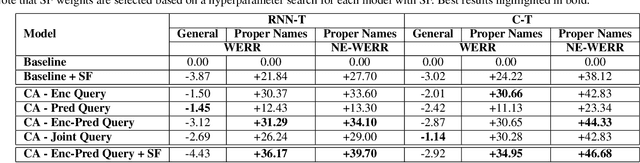
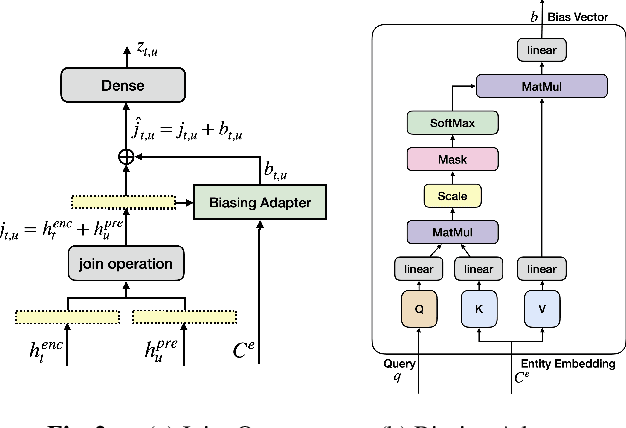
Personal rare word recognition in end-to-end Automatic Speech Recognition (E2E ASR) models is a challenge due to the lack of training data. A standard way to address this issue is with shallow fusion methods at inference time. However, due to their dependence on external language models and the deterministic approach to weight boosting, their performance is limited. In this paper, we propose training neural contextual adapters for personalization in neural transducer based ASR models. Our approach can not only bias towards user-defined words, but also has the flexibility to work with pretrained ASR models. Using an in-house dataset, we demonstrate that contextual adapters can be applied to any general purpose pretrained ASR model to improve personalization. Our method outperforms shallow fusion, while retaining functionality of the pretrained models by not altering any of the model weights. We further show that the adapter style training is superior to full-fine-tuning of the ASR models on datasets with user-defined content.
Context-Aware Transformer Transducer for Speech Recognition
Nov 05, 2021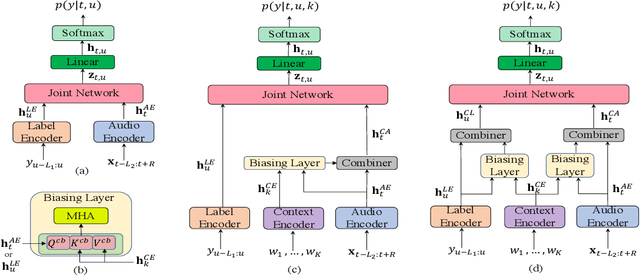

End-to-end (E2E) automatic speech recognition (ASR) systems often have difficulty recognizing uncommon words, that appear infrequently in the training data. One promising method, to improve the recognition accuracy on such rare words, is to latch onto personalized/contextual information at inference. In this work, we present a novel context-aware transformer transducer (CATT) network that improves the state-of-the-art transformer-based ASR system by taking advantage of such contextual signals. Specifically, we propose a multi-head attention-based context-biasing network, which is jointly trained with the rest of the ASR sub-networks. We explore different techniques to encode contextual data and to create the final attention context vectors. We also leverage both BLSTM and pretrained BERT based models to encode contextual data and guide the network training. Using an in-house far-field dataset, we show that CATT, using a BERT based context encoder, improves the word error rate of the baseline transformer transducer and outperforms an existing deep contextual model by 24.2% and 19.4% respectively.
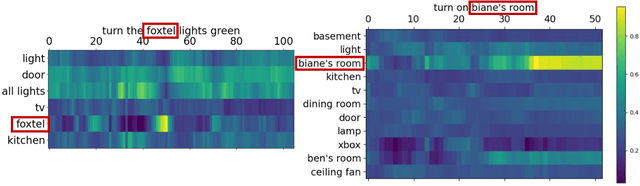
FANS: Fusing ASR and NLU for on-device SLU
Oct 31, 2021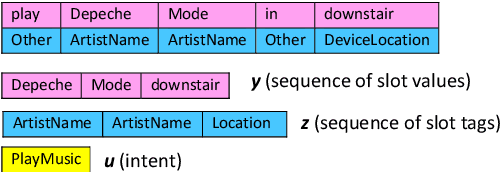
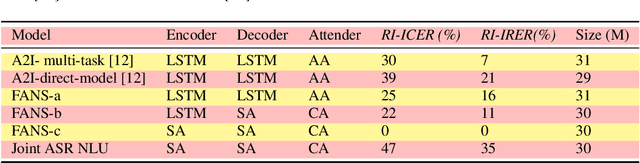
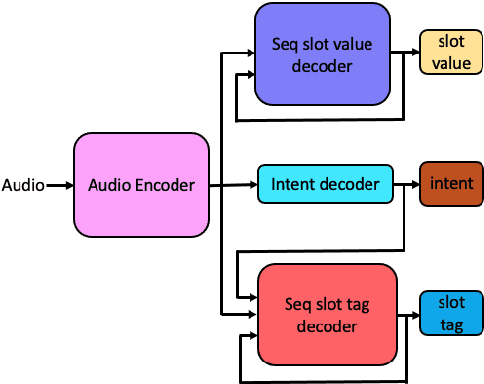
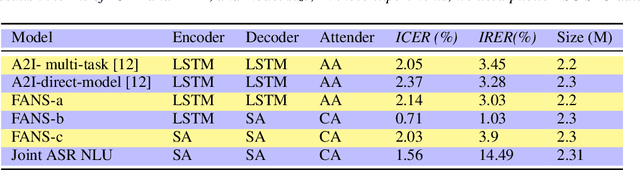
Spoken language understanding (SLU) systems translate voice input commands to semantics which are encoded as an intent and pairs of slot tags and values. Most current SLU systems deploy a cascade of two neural models where the first one maps the input audio to a transcript (ASR) and the second predicts the intent and slots from the transcript (NLU). In this paper, we introduce FANS, a new end-to-end SLU model that fuses an ASR audio encoder to a multi-task NLU decoder to infer the intent, slot tags, and slot values directly from a given input audio, obviating the need for transcription. FANS consists of a shared audio encoder and three decoders, two of which are seq-to-seq decoders that predict non null slot tags and slot values in parallel and in an auto-regressive manner. FANS neural encoder and decoders architectures are flexible which allows us to leverage different combinations of LSTM, self-attention, and attenders. Our experiments show compared to the state-of-the-art end-to-end SLU models, FANS reduces ICER and IRER errors relatively by 30 % and 7 %, respectively, when tested on an in-house SLU dataset and by 0.86 % and 2 % absolute when tested on a public SLU dataset.
Exploiting Large-scale Teacher-Student Training for On-device Acoustic Models
Jun 11, 2021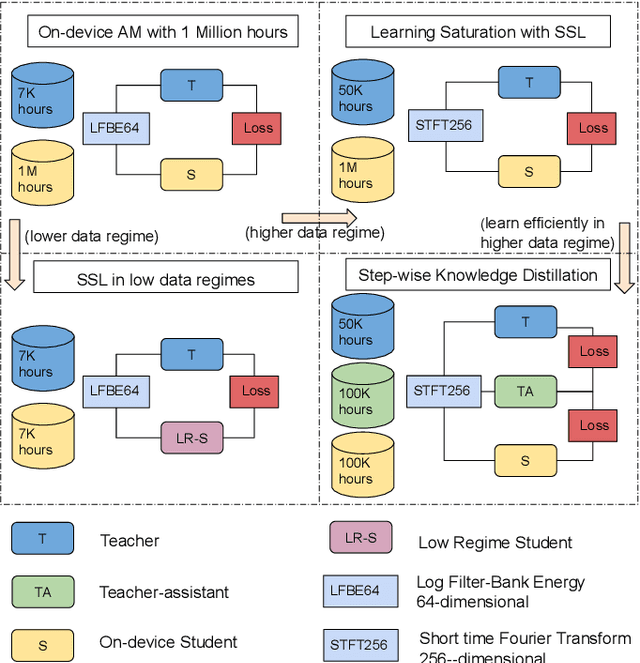
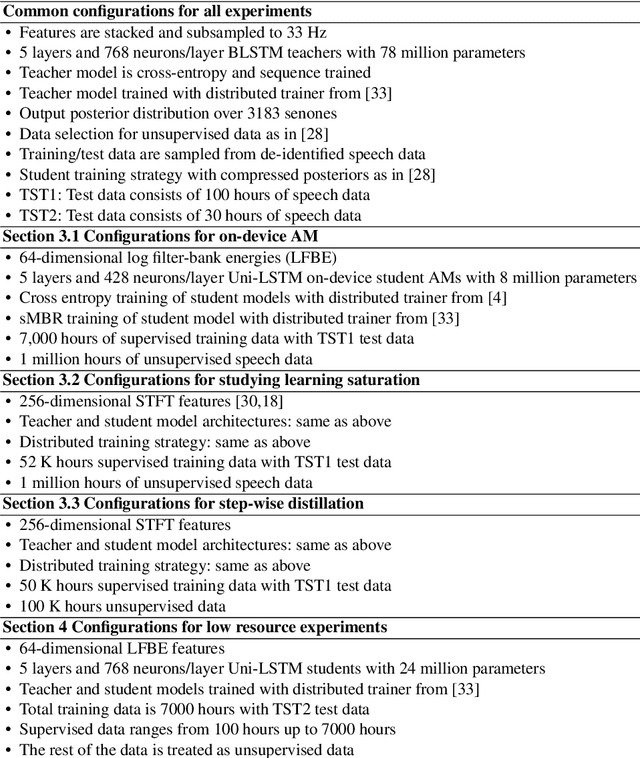
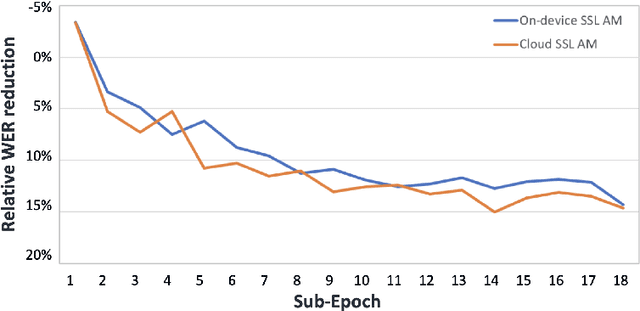
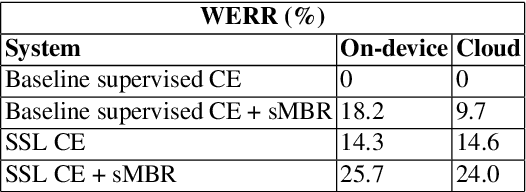
We present results from Alexa speech teams on semi-supervised learning (SSL) of acoustic models (AM) with experiments spanning over 3000 hours of GPU time, making our study one of the largest of its kind. We discuss SSL for AMs in a small footprint setting, showing that a smaller capacity model trained with 1 million hours of unsupervised data can outperform a baseline supervised system by 14.3% word error rate reduction (WERR). When increasing the supervised data to seven-fold, our gains diminish to 7.1% WERR; to improve SSL efficiency at larger supervised data regimes, we employ a step-wise distillation into a smaller model, obtaining a WERR of 14.4%. We then switch to SSL using larger student models in low data regimes; while learning efficiency with unsupervised data is higher, student models may outperform teacher models in such a setting. We develop a theoretical sketch to explain this behavior.
End-to-End Multi-Channel Transformer for Speech Recognition
Feb 08, 2021
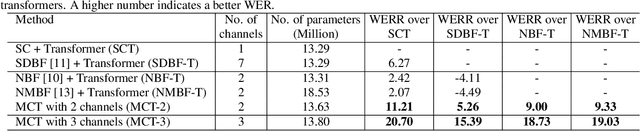
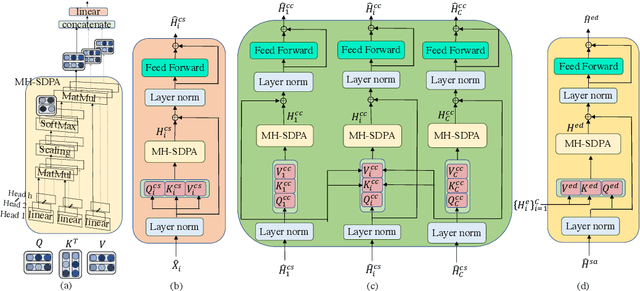

Transformers are powerful neural architectures that allow integrating different modalities using attention mechanisms. In this paper, we leverage the neural transformer architectures for multi-channel speech recognition systems, where the spectral and spatial information collected from different microphones are integrated using attention layers. Our multi-channel transformer network mainly consists of three parts: channel-wise self attention layers (CSA), cross-channel attention layers (CCA), and multi-channel encoder-decoder attention layers (EDA). The CSA and CCA layers encode the contextual relationship within and between channels and across time, respectively. The channel-attended outputs from CSA and CCA are then fed into the EDA layers to help decode the next token given the preceding ones. The experiments show that in a far-field in-house dataset, our method outperforms the baseline single-channel transformer, as well as the super-directive and neural beamformers cascaded with the transformers.