 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookahead When It Matters: Adaptive Non-causal Transformers for Streaming Neural Transducers
May 09, 2023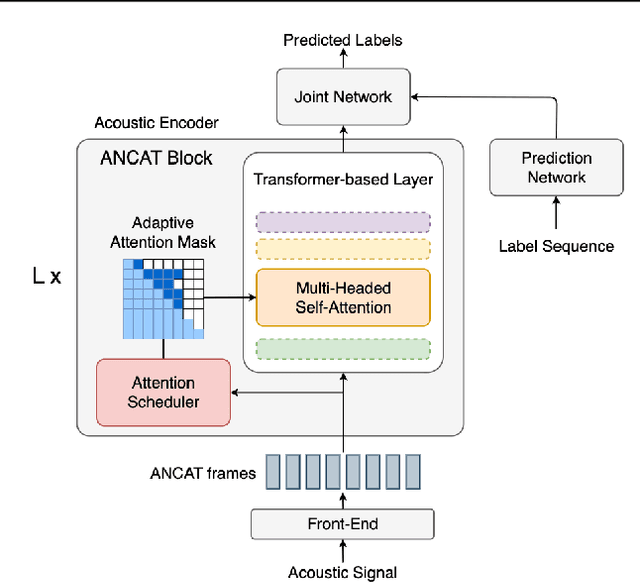
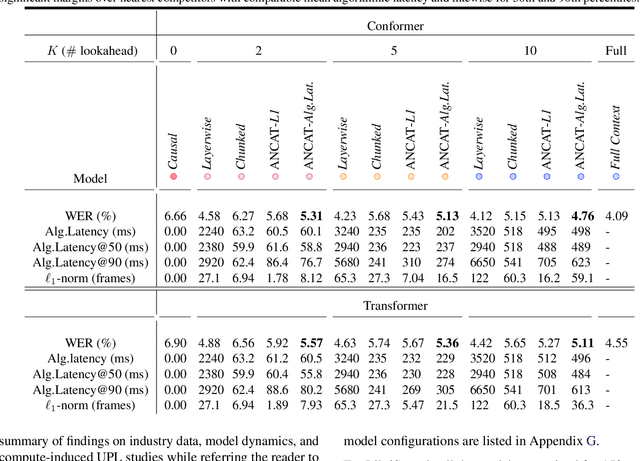
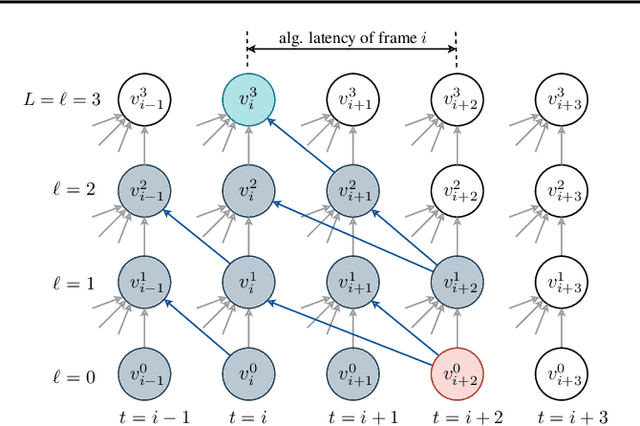
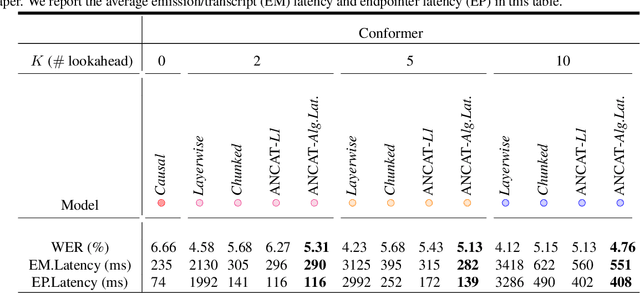
Streaming speech recognition architectures are employed for low-latency, real-time applications. Such architectures are often characterized by their causality. Causal architectures emit tokens at each frame, relying only on current and past signal, while non-causal models are exposed to a window of future frames at each step to increase predictive accuracy. This dichotomy amounts to a trade-off for real-time Automatic Speech Recognition (ASR) system design: profit from the low-latency benefit of strictly-causal architectures while accepting predictive performance limitations, or realize the modeling benefits of future-context models accompanied by their higher latency penalty. In this work, we relax the constraints of this choice and present the Adaptive Non-Causal Attention Transducer (ANCAT). Our architecture is non-causal in the traditional sense, but executes in a low-latency, streaming manner by dynamically choosing when to rely on future context and to what degree within the audio stream. The resulting mechanism, when coupled with our novel regularization algorithms, delivers comparable accuracy to non-causal configurations while improving significantly upon latency, closing the gap with their causal counterparts. We showcase our design experimentally by reporting comparative ASR task results with measures of accuracy and latency on both publicly accessible and production-scale, voice-assistant datasets.
End-to-end spoken language understanding using joint CTC loss and self-supervised, pretrained acoustic encoders
May 04, 2023



It is challenging to extract semantic meanings directly from audio signals in spoken language understanding (SLU), due to the lack of textual information. Popular end-to-end (E2E) SLU models utilize sequence-to-sequence automatic speech recognition (ASR) models to extract textual embeddings as input to infer semantics, which, however, require computationally expensive auto-regressive decoding. In this work, we leverage self-supervised acoustic encoders fine-tuned with Connectionist Temporal Classification (CTC) to extract textual embeddings and use joint CTC and SLU losses for utterance-level SLU tasks. Experiments show that our model achieves 4% absolute improvement over the the state-of-the-art (SOTA) dialogue act classification model on the DSTC2 dataset and 1.3% absolute improvement over the SOTA SLU model on the SLURP dataset.
Leveraging Redundancy in Multiple Audio Signals for Far-Field Speech Recognition
Mar 01, 2023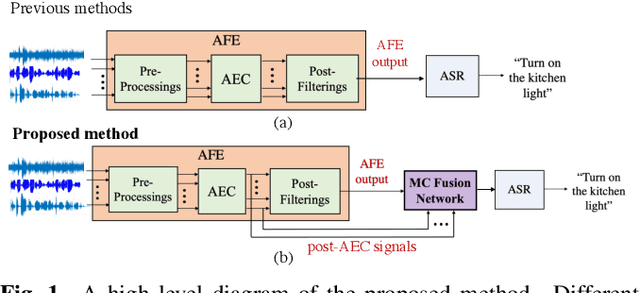

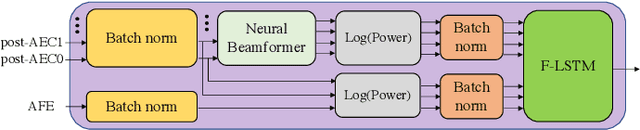
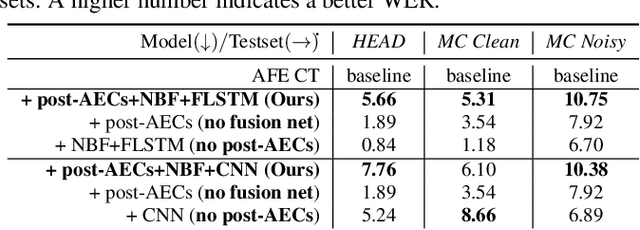
To achieve robust far-field automatic speech recognition (ASR), existing techniques typically employ an acoustic front end (AFE) cascaded with a neural transducer (NT) ASR model. The AFE output, however, could be unreliable, as the beamforming output in AFE is steered to a wrong direction. A promising way to address this issue is to exploit the microphone signals before the beamforming stage and after the acoustic echo cancellation (post-AEC) in AFE. We argue that both, post-AEC and AFE outputs, are complementary and it is possible to leverage the redundancy between these signals to compensate for potential AFE processing errors. We present two fusion networks to explore this redundancy and aggregate these multi-channel (MC) signals: (1) Frequency-LSTM based, and (2) Convolutional Neural Network based fusion networks. We augment the MC fusion networks to a conformer transducer model and train it in an end-to-end fashion. Our experimental results on commercial virtual assistant tasks demonstrate that using the AFE output and two post-AEC signals with fusion networks offers up to 25.9% word error rate (WER) relative improvement over the model using the AFE output only, at the cost of <= 2% parameter increase.
Sub-8-bit quantization for on-device speech recognition: a regularization-free approach
Oct 17, 2022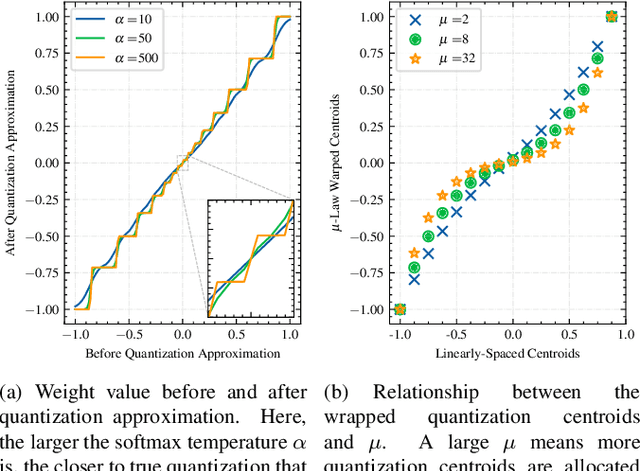
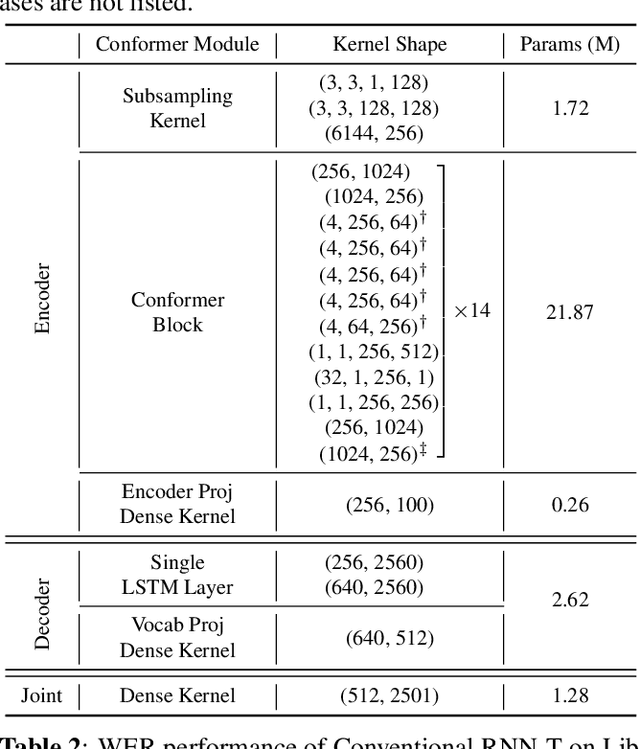

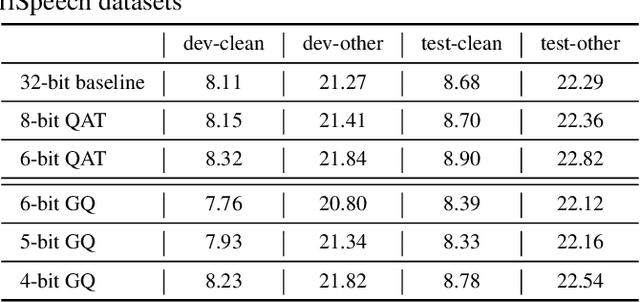
For on-device automatic speech recognition (ASR), quantization aware training (QAT) is ubiquitous to achieve the trade-off between model predictive performance and efficiency. Among existing QAT methods, one major drawback is that the quantization centroids have to be predetermined and fixed. To overcome this limitation, we introduce a regularization-free, "soft-to-hard" compression mechanism with self-adjustable centroids in a mu-Law constrained space, resulting in a simpler yet more versatile quantization scheme, called General Quantizer (GQ). We apply GQ to ASR tasks using Recurrent Neural Network Transducer (RNN-T) and Conformer architectures on both LibriSpeech and de-identified far-field datasets. Without accuracy degradation, GQ can compress both RNN-T and Conformer into sub-8-bit, and for some RNN-T layers, to 1-bit for fast and accurate inference. We observe a 30.73% memory footprint saving and 31.75% user-perceived latency reduction compared to 8-bit QAT via physical device benchmarking.
ConvRNN-T: Convolutional Augmented Recurrent Neural Network Transducers for Streaming Speech Recognition
Sep 29, 2022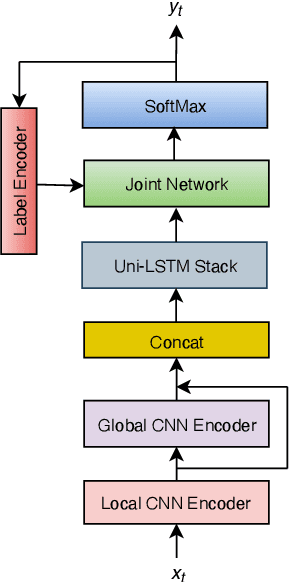
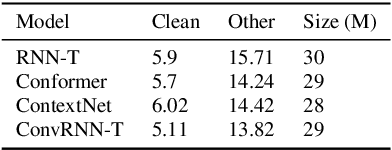
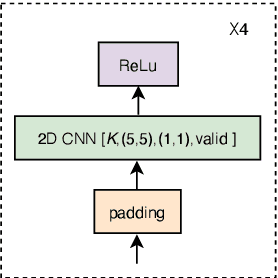

The recurrent neural network transducer (RNN-T) is a prominent streaming end-to-end (E2E) ASR technology. In RNN-T, the acoustic encoder commonly consists of stacks of LSTMs. Very recently, as an alternative to LSTM layers, the Conformer architecture was introduced where the encoder of RNN-T is replaced with a modified Transformer encoder composed of convolutional layers at the frontend and between attention layers. In this paper, we introduce a new streaming ASR model, Convolutional Augmented Recurrent Neural Network Transducers (ConvRNN-T) in which we augment the LSTM-based RNN-T with a novel convolutional frontend consisting of local and global context CNN encoders. ConvRNN-T takes advantage of causal 1-D convolutional layers, squeeze-and-excitation, dilation, and residual blocks to provide both global and local audio context representation to LSTM layers. We show ConvRNN-T outperforms RNN-T, Conformer, and ContextNet on Librispeech and in-house data. In addition, ConvRNN-T offers less computational complexity compared to Conformer. ConvRNN-T's superior accuracy along with its low footprint make it a promising candidate for on-device streaming ASR technologies.
Compute Cost Amortized Transformer for Streaming ASR
Jul 05, 2022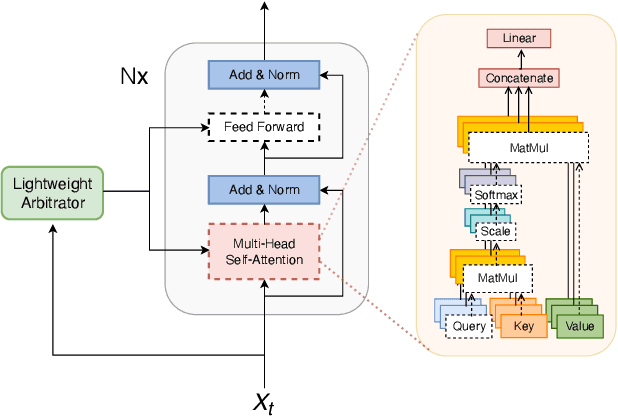
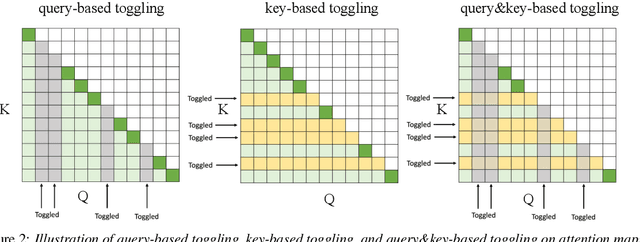
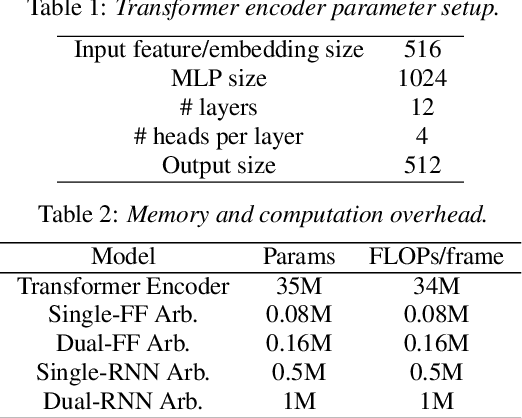
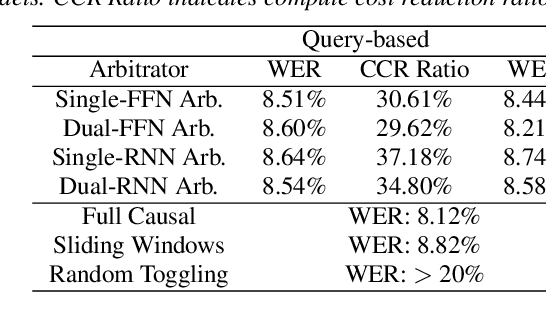
We present a streaming, Transformer-based end-to-end automatic speech recognition (ASR) architecture which achieves efficient neural inference through compute cost amortization. Our architecture creates sparse computation pathways dynamically at inference time, resulting in selective use of compute resources throughout decoding, enabling significant reductions in compute with minimal impact on accuracy. The fully differentiable architecture is trained end-to-end with an accompanying lightweight arbitrator mechanism operating at the frame-level to make dynamic decisions on each input while a tunable loss function is used to regularize the overall level of compute against predictive performance. We report empirical results from experiments using the compute amortized Transformer-Transducer (T-T) model conducted on LibriSpeech data. Our best model can achieve a 60% compute cost reduction with only a 3% relative word error rate (WER) increase.
A neural prosody encoder for end-ro-end dialogue act classification
May 11, 2022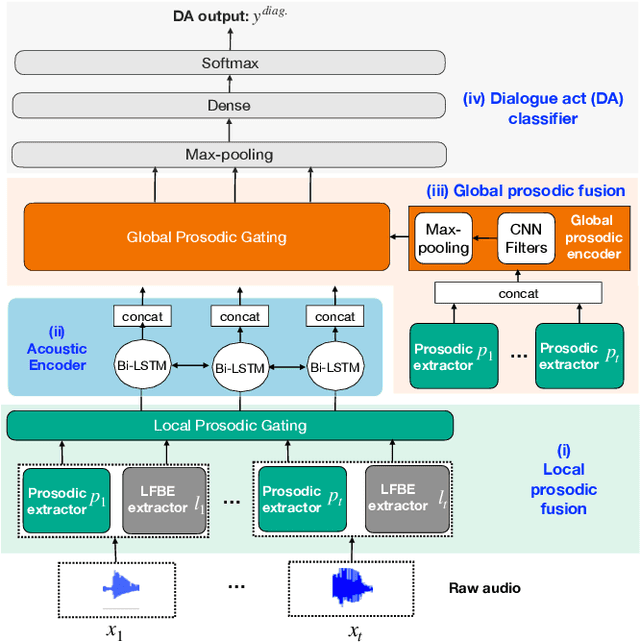
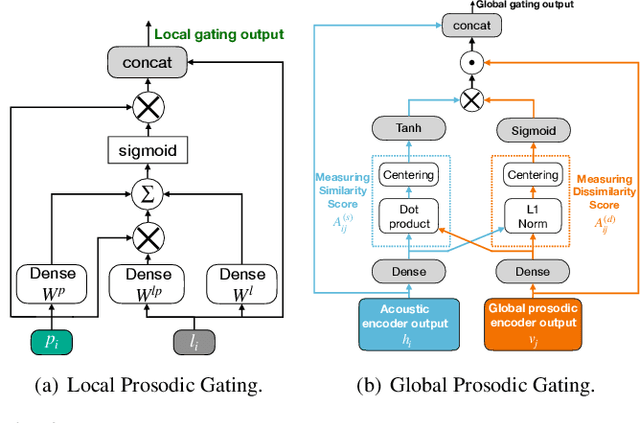

Dialogue act classification (DAC) is a critical task for spoken language understanding in dialogue systems. Prosodic features such as energy and pitch have been shown to be useful for DAC. Despite their importance, little research has explored neural approaches to integrate prosodic features into end-to-end (E2E) DAC models which infer dialogue acts directly from audio signals. In this work, we propose an E2E neural architecture that takes into account the need for characterizing prosodic phenomena co-occurring at different levels inside an utterance. A novel part of this architecture is a learnable gating mechanism that assesses the importance of prosodic features and selectively retains core information necessary for E2E DAC. Our proposed model improves DAC accuracy by 1.07% absolute across three publicly available benchmark datasets.
Multi-task RNN-T with Semantic Decoder for Streamable Spoken Language Understanding
Apr 01, 2022
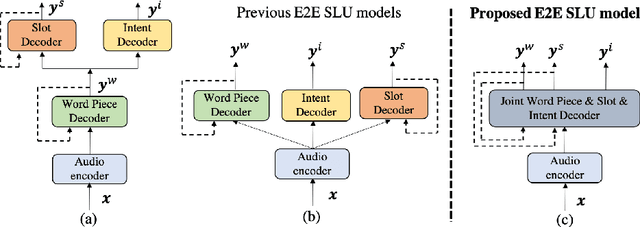
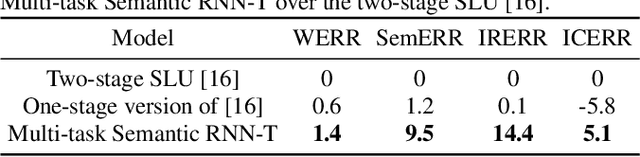
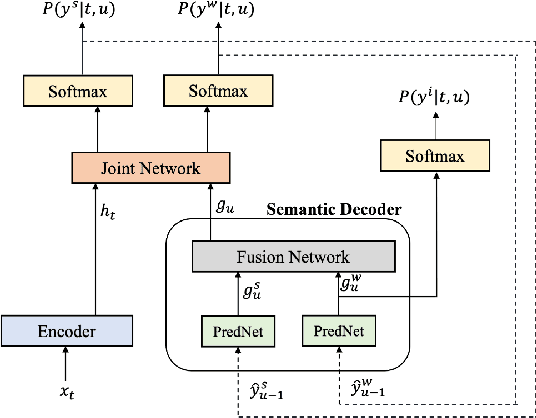
End-to-end Spoken Language Understanding (E2E SLU) has attracted increasing interest due to its advantages of joint optimization and low latency when compared to traditionally cascaded pipelines. Existing E2E SLU models usually follow a two-stage configuration where an Automatic Speech Recognition (ASR) network first predicts a transcript which is then passed to a Natural Language Understanding (NLU) module through an interface to infer semantic labels, such as intent and slot tags. This design, however, does not consider the NLU posterior while making transcript predictions, nor correct the NLU prediction error immediately by considering the previously predicted word-pieces. In addition, the NLU model in the two-stage system is not streamable, as it must wait for the audio segments to complete processing, which ultimately impacts the latency of the SLU system. In this work, we propose a streamable multi-task semantic transducer model to address these considerations. Our proposed architecture predicts ASR and NLU labels auto-regressively and uses a semantic decoder to ingest both previously predicted word-pieces and slot tags while aggregating them through a fusion network. Using an industry scale SLU and a public FSC dataset, we show the proposed model outperforms the two-stage E2E SLU model for both ASR and NLU metrics.
Context-Aware Transformer Transducer for Speech Recognition
Nov 05, 2021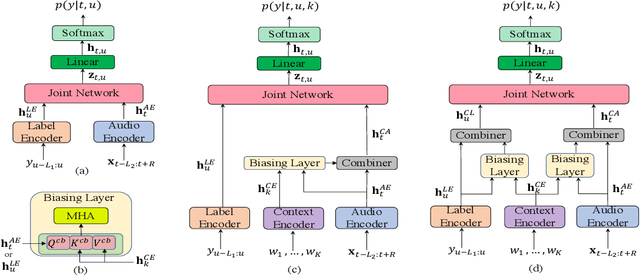
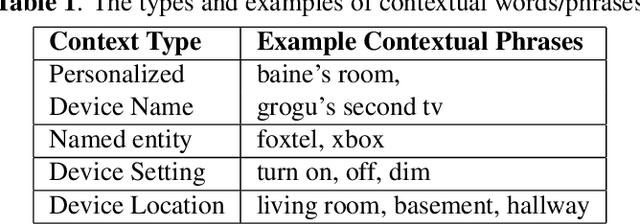

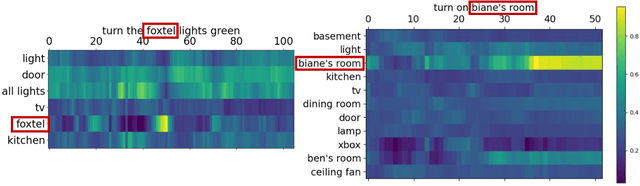
End-to-end (E2E) automatic speech recognition (ASR) systems often have difficulty recognizing uncommon words, that appear infrequently in the training data. One promising method, to improve the recognition accuracy on such rare words, is to latch onto personalized/contextual information at inference. In this work, we present a novel context-aware transformer transducer (CATT) network that improves the state-of-the-art transformer-based ASR system by taking advantage of such contextual signals. Specifically, we propose a multi-head attention-based context-biasing network, which is jointly trained with the rest of the ASR sub-networks. We explore different techniques to encode contextual data and to create the final attention context vectors. We also leverage both BLSTM and pretrained BERT based models to encode contextual data and guide the network training. Using an in-house far-field dataset, we show that CATT, using a BERT based context encoder, improves the word error rate of the baseline transformer transducer and outperforms an existing deep contextual model by 24.2% and 19.4% respectively.
Speech Emotion Recognition Using Quaternion Convolutional Neural Networks
Oct 31, 2021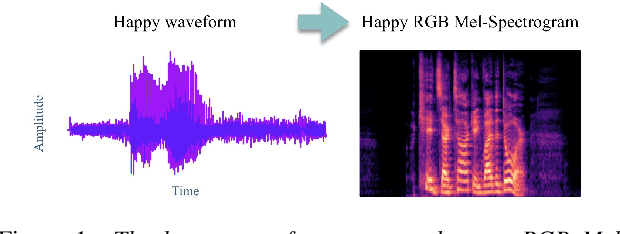
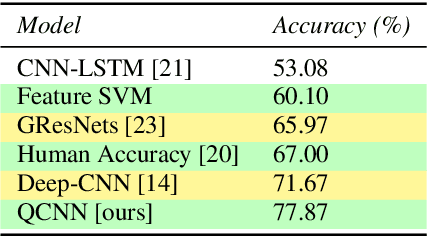
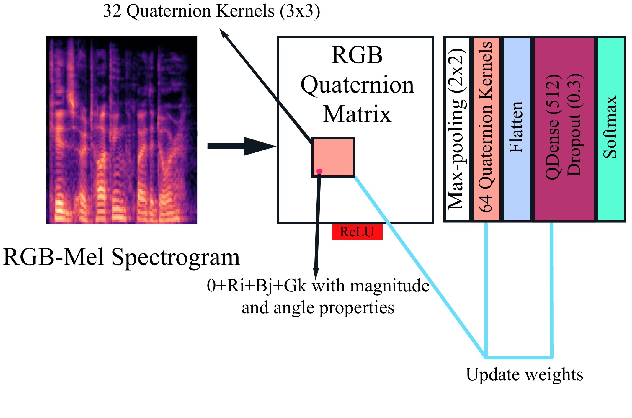
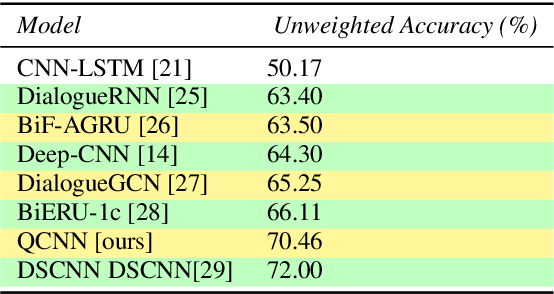
Although speech recognition has become a widespread technology, inferring emotion from speech signals still remains a challenge. To address this problem, this paper proposes a quaternion convolutional neural network (QCNN) based speech emotion recognition (SER) model in which Mel-spectrogram features of speech signals are encoded in an RGB quaternion domain. We show that our QCNN based SER model outperforms other real-valued methods in the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS, 8-classes) dataset, achieving, to the best of our knowledge, state-of-the-art results. The QCNN also achieves comparable results with the state-of-the-art methods in the Interactive Emotional Dyadic Motion Capture (IEMOCAP 4-classes) and Berlin EMO-DB (7-classes) datasets. Specifically, the model achieves an accuracy of 77.87\%, 70.46\%, and 88.78\% for the RAVDESS, IEMOCAP, and EMO-DB datasets, respectively. In addition, our results show that the quaternion unit structure is better able to encode internal dependencies to reduce its model size significantly compared to other methods.