 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Scheduling for Efficient Inference-Time Reasoning in Large Language Models
Feb 01, 2026Large language models (LLMs) achieve state-of-the-art accuracy on complex reasoning tasks by generating multiple chain-of-thought (CoT) traces, but using a fixed token budget per query leads to over-computation on easy inputs and under-computation on hard ones. We introduce Predictive Scheduling, a plug-and-play framework that pre-runs lightweight predictors, an MLP on intermediate transformer hidden states or a LoRA-fine-tuned classifier on raw question text, to estimate each query's optimal reasoning length or difficulty before any full generation. Our greedy batch allocator dynamically distributes a fixed total token budget across queries to maximize expected accuracy. On the GSM8K arithmetic benchmark, predictive scheduling yields up to 7.9 percentage points of absolute accuracy gain over uniform budgeting at identical token cost, closing over 50\% of the gap to an oracle with perfect foresight. A systematic layer-wise study reveals that middle layers (12 - 17) of the transformer carry the richest signals for size estimation. These results demonstrate that pre-run budget prediction enables fine-grained control of the compute-accuracy trade-off, offering a concrete path toward latency-sensitive, cost-efficient LLM deployments.
Permutation Invariant Learning with High-Dimensional Particle Filters
Oct 30, 2024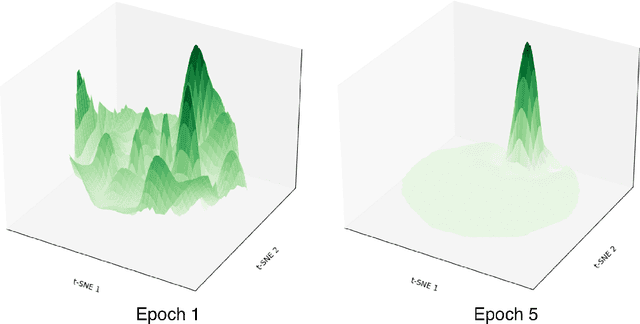
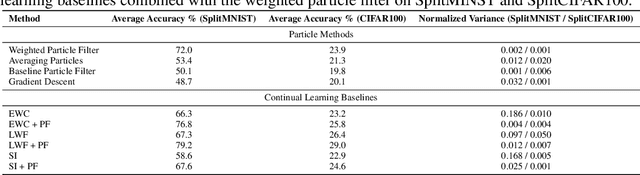
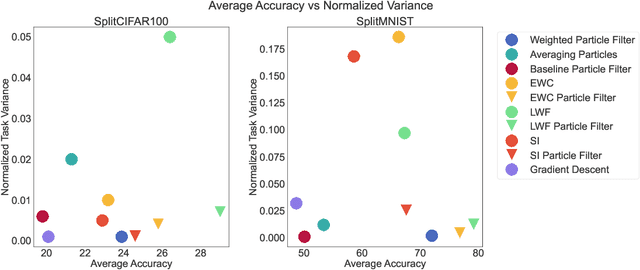
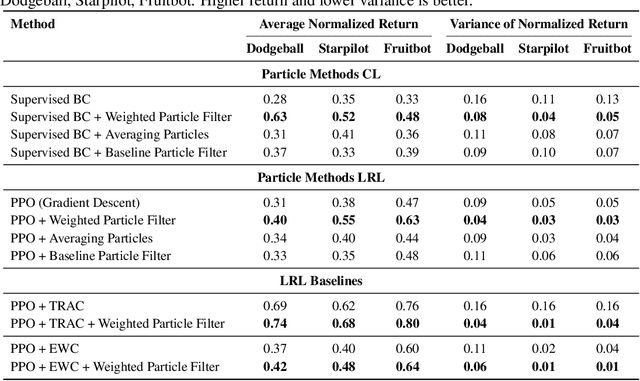
Sequential learning in deep models often suffers from challenges such as catastrophic forgetting and loss of plasticity, largely due to the permutation dependence of gradient-based algorithms, where the order of training data impacts the learning outcome. In this work, we introduce a novel permutation-invariant learning framework based on high-dimensional particle filters. We theoretically demonstrate that particle filters are invariant to the sequential ordering of training minibatches or tasks, offering a principled solution to mitigate catastrophic forgetting and loss-of-plasticity. We develop an efficient particle filter for optimizing high-dimensional models, combining the strengths of Bayesian methods with gradient-based optimization. Through extensive experiments on continual supervised and reinforcement learning benchmarks, including SplitMNIST, SplitCIFAR100, and ProcGen, we empirically show that our method consistently improves performance, while reducing variance compared to standard baselines.
Pick up the PACE: A Parameter-Free Optimizer for Lifelong Reinforcement Learning
May 26, 2024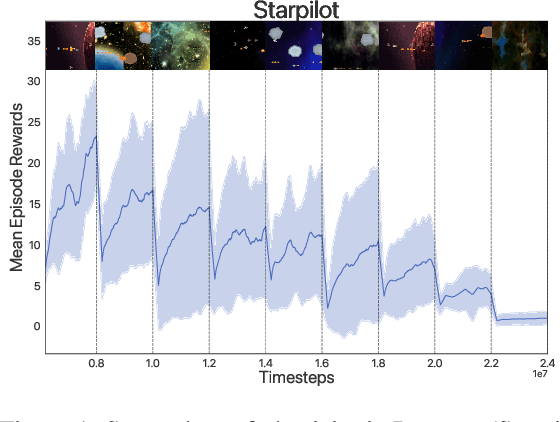
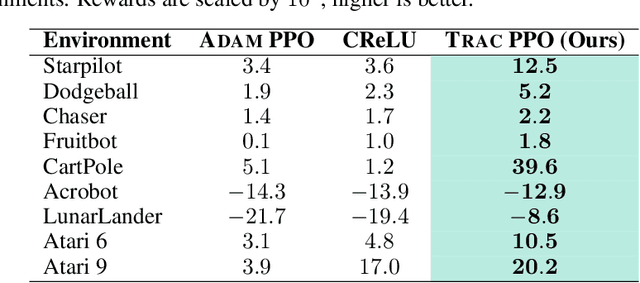
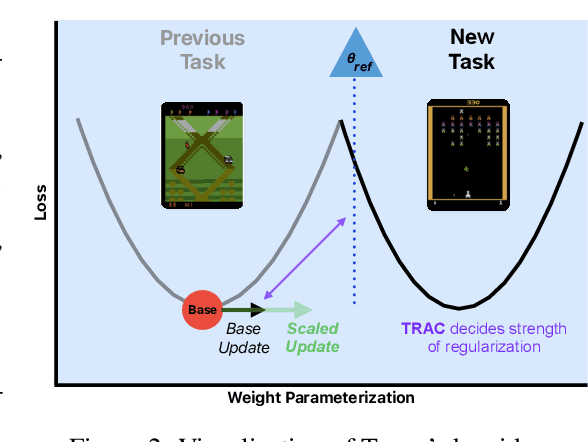
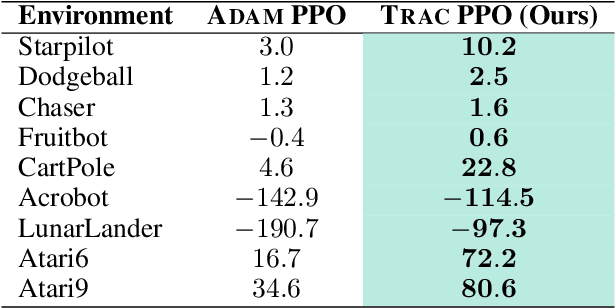
A key challenge in lifelong reinforcement learning (RL) is the loss of plasticity, where previous learning progress hinders an agent's adaptation to new tasks. While regularization and resetting can help, they require precise hyperparameter selection at the outset and environment-dependent adjustments. Building on the principled theory of online convex optimization, we present a parameter-free optimizer for lifelong RL, called PACE, which requires no tuning or prior knowledge about the distribution shifts. Extensive experiments on Procgen, Atari, and Gym Control environments show that PACE works surprisingly well$\unicode{x2013}$mitigating loss of plasticity and rapidly adapting to challenging distribution shifts$\unicode{x2013}$despite the underlying optimization problem being nonconvex and nonstationary.
Resampling-free Particle Filters in High-dimensions
Apr 21, 2024
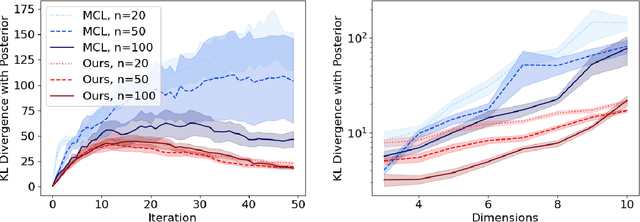

State estimation is crucial for the performance and safety of numerous robotic applications. Among the suite of estimation techniques, particle filters have been identified as a powerful solution due to their non-parametric nature. Yet, in high-dimensional state spaces, these filters face challenges such as 'particle deprivation' which hinders accurate representation of the true posterior distribution. This paper introduces a novel resampling-free particle filter designed to mitigate particle deprivation by forgoing the traditional resampling step. This ensures a broader and more diverse particle set, especially vital in high-dimensional scenarios. Theoretically, our proposed filter is shown to offer a near-accurate representation of the desired posterior distribution in high-dimensional contexts. Empirically, the effectiveness of our approach is underscored through a high-dimensional synthetic state estimation task and a 6D pose estimation derived from videos. We posit that as robotic systems evolve with greater degrees of freedom, particle filters tailored for high-dimensional state spaces will be indispensable.
Speech Emotion Recognition Using Quaternion Convolutional Neural Networks
Oct 31, 2021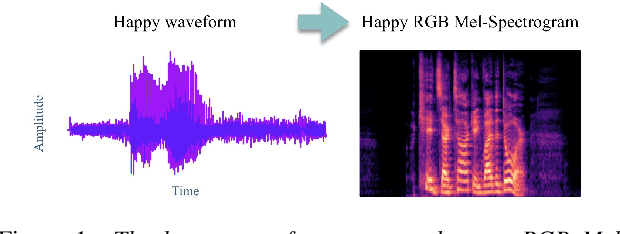
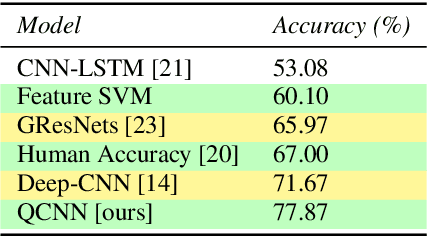
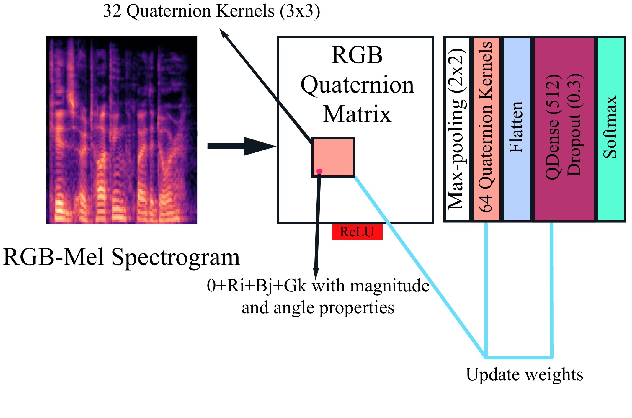
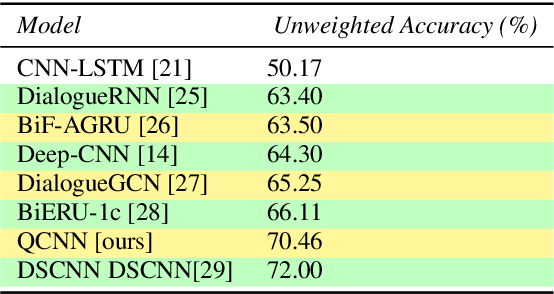
Although speech recognition has become a widespread technology, inferring emotion from speech signals still remains a challenge. To address this problem, this paper proposes a quaternion convolutional neural network (QCNN) based speech emotion recognition (SER) model in which Mel-spectrogram features of speech signals are encoded in an RGB quaternion domain. We show that our QCNN based SER model outperforms other real-valued methods in the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS, 8-classes) dataset, achieving, to the best of our knowledge, state-of-the-art results. The QCNN also achieves comparable results with the state-of-the-art methods in the Interactive Emotional Dyadic Motion Capture (IEMOCAP 4-classes) and Berlin EMO-DB (7-classes) datasets. Specifically, the model achieves an accuracy of 77.87\%, 70.46\%, and 88.78\% for the RAVDESS, IEMOCAP, and EMO-DB datasets, respectively. In addition, our results show that the quaternion unit structure is better able to encode internal dependencies to reduce its model size significantly compared to other methods.