 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePermutation Invariant Learning with High-Dimensional Particle Filters
Paper and Code
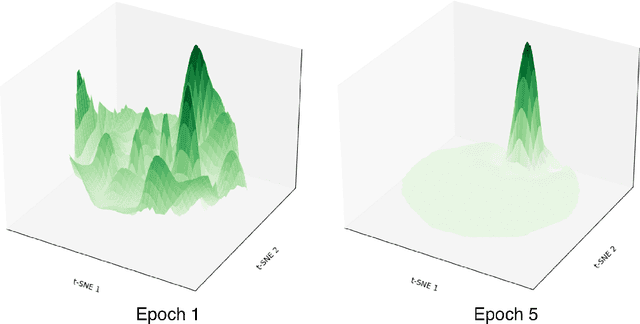
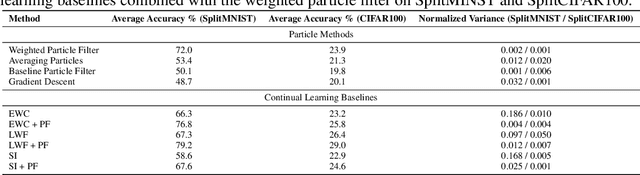
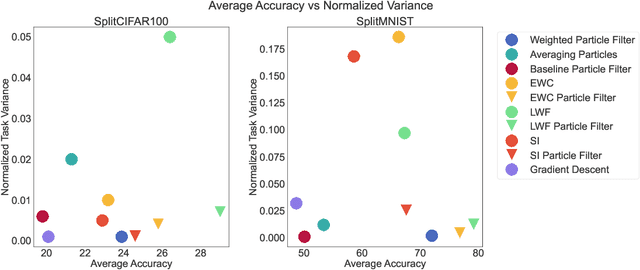
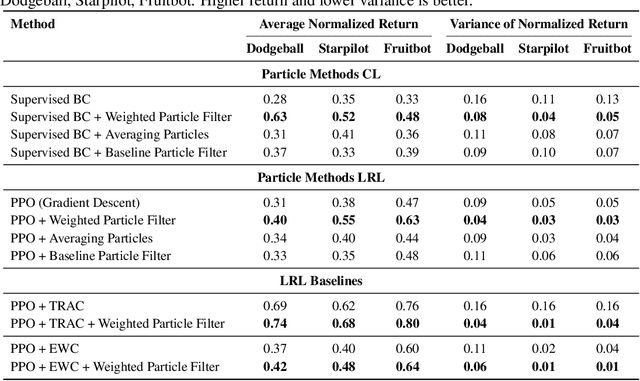
Sequential learning in deep models often suffers from challenges such as catastrophic forgetting and loss of plasticity, largely due to the permutation dependence of gradient-based algorithms, where the order of training data impacts the learning outcome. In this work, we introduce a novel permutation-invariant learning framework based on high-dimensional particle filters. We theoretically demonstrate that particle filters are invariant to the sequential ordering of training minibatches or tasks, offering a principled solution to mitigate catastrophic forgetting and loss-of-plasticity. We develop an efficient particle filter for optimizing high-dimensional models, combining the strengths of Bayesian methods with gradient-based optimization. Through extensive experiments on continual supervised and reinforcement learning benchmarks, including SplitMNIST, SplitCIFAR100, and ProcGen, we empirically show that our method consistently improves performance, while reducing variance compared to standard baselines.