 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Federated Learning
Mar 03, 2024
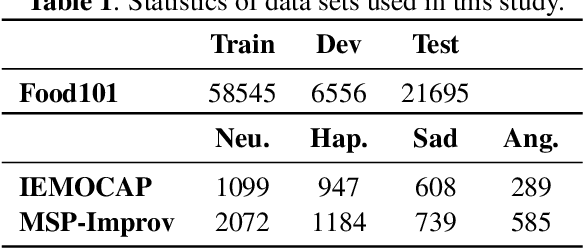
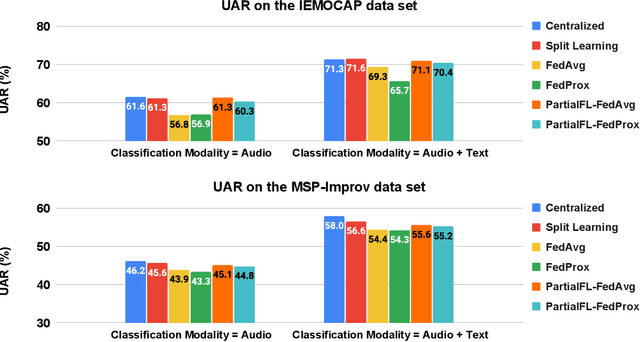
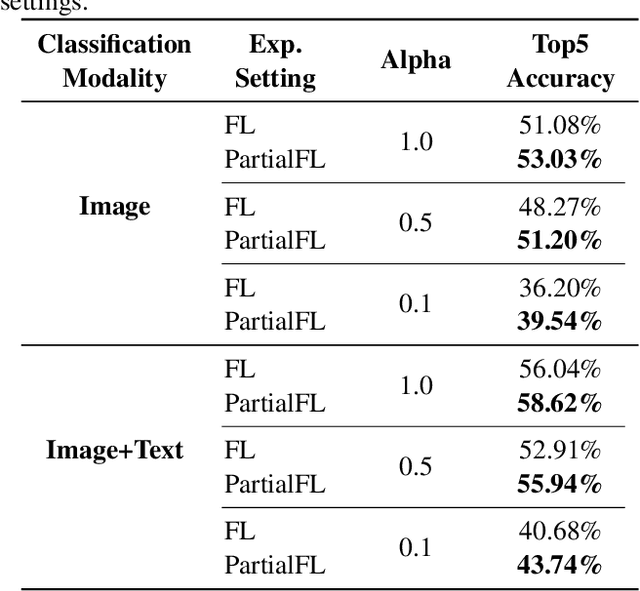
Federated Learning (FL) is a popular algorithm to train machine learning models on user data constrained to edge devices (for example, mobile phones) due to privacy concerns. Typically, FL is trained with the assumption that no part of the user data can be egressed from the edge. However, in many production settings, specific data-modalities/meta-data are limited to be on device while others are not. For example, in commercial SLU systems, it is typically desired to prevent transmission of biometric signals (such as audio recordings of the input prompt) to the cloud, but egress of locally (i.e. on the edge device) transcribed text to the cloud may be possible. In this work, we propose a new algorithm called Partial Federated Learning (PartialFL), where a machine learning model is trained using data where a subset of data modalities or their intermediate representations can be made available to the server. We further restrict our model training by preventing the egress of data labels to the cloud for better privacy, and instead use a contrastive learning based model objective. We evaluate our approach on two different multi-modal datasets and show promising results with our proposed approach.
Coordinated Replay Sample Selection for Continual Federated Learning
Oct 23, 2023



Continual Federated Learning (CFL) combines Federated Learning (FL), the decentralized learning of a central model on a number of client devices that may not communicate their data, and Continual Learning (CL), the learning of a model from a continual stream of data without keeping the entire history. In CL, the main challenge is \textit{forgetting} what was learned from past data. While replay-based algorithms that keep a small pool of past training data are effective to reduce forgetting, only simple replay sample selection strategies have been applied to CFL in prior work, and no previous work has explored coordination among clients for better sample selection. To bridge this gap, we adapt a replay sample selection objective based on loss gradient diversity to CFL and propose a new relaxation-based selection of samples to optimize the objective. Next, we propose a practical algorithm to coordinate gradient-based replay sample selection across clients without communicating private data. We benchmark our coordinated and uncoordinated replay sample selection algorithms against random sampling-based baselines with language models trained on a large scale de-identified real-world text dataset. We show that gradient-based sample selection methods both boost performance and reduce forgetting compared to random sampling methods, with our coordination method showing gains early in the low replay size regime (when the budget for storing past data is small).
End-to-end spoken language understanding using joint CTC loss and self-supervised, pretrained acoustic encoders
May 04, 2023



It is challenging to extract semantic meanings directly from audio signals in spoken language understanding (SLU), due to the lack of textual information. Popular end-to-end (E2E) SLU models utilize sequence-to-sequence automatic speech recognition (ASR) models to extract textual embeddings as input to infer semantics, which, however, require computationally expensive auto-regressive decoding. In this work, we leverage self-supervised acoustic encoders fine-tuned with Connectionist Temporal Classification (CTC) to extract textual embeddings and use joint CTC and SLU losses for utterance-level SLU tasks. Experiments show that our model achieves 4% absolute improvement over the the state-of-the-art (SOTA) dialogue act classification model on the DSTC2 dataset and 1.3% absolute improvement over the SOTA SLU model on the SLURP dataset.
How to Minimize the Weighted Sum AoI in Two-Source Status Update Systems: OMA or NOMA?
May 06, 2022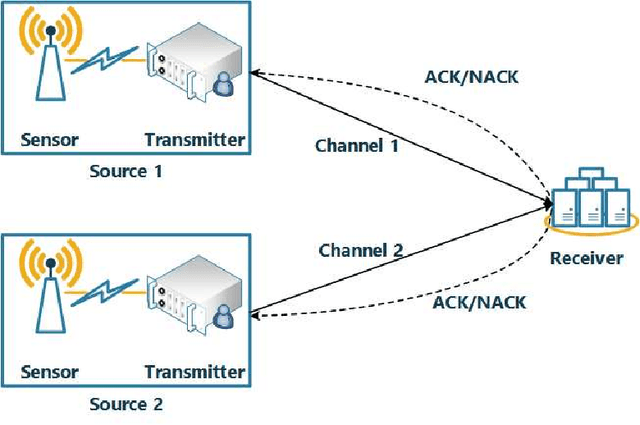
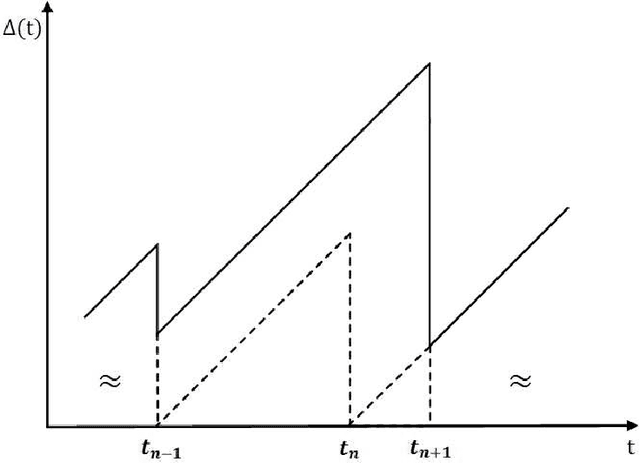
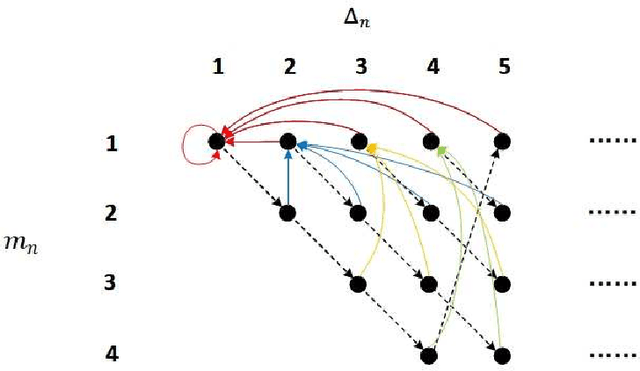
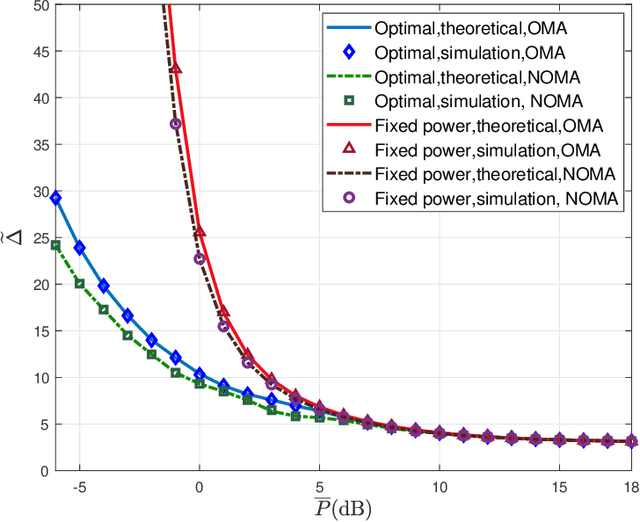
In this paper, the minimization of the weighted sum average age of information (AoI) in a two-source status update communication system is studied. Two independent sources send update packets to a common destination node in a time-slotted manner under the limit of maximum retransmission rounds. Different multiple access schemes, i.e., orthogonal multiple access (OMA) and non-orthogonal multiple access (NOMA) are exploited here over a block-fading multiple access channel (MAC). Constrained Markov decision process (CMDP) problems are formulated to describe the AoI minimization problems considering both transmission schemes. The Lagrangian method is utilised to convert CMDP problems to unconstraint Markov decision process (MDP) problems and corresponding algorithms to derive the power allocation policies are obtained. On the other hand, for the case of unknown environments, two online reinforcement learning approaches considering both multiple access schemes are proposed to achieve near-optimal age performance. Numerical simulations validate the improvement of the proposed policy in terms of weighted sum AoI compared to the fixed power transmission policy, and illustrate that NOMA is more favorable in case of larger packet size.
On the data requirements of probing
Feb 25, 2022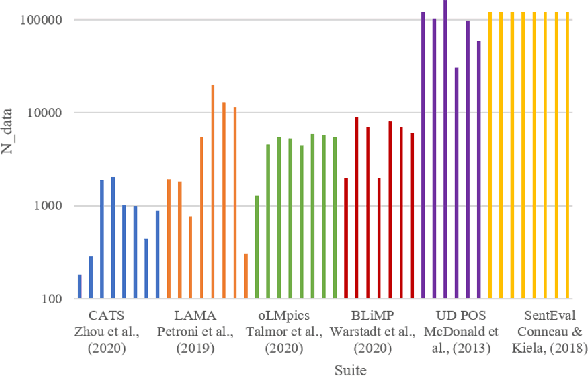

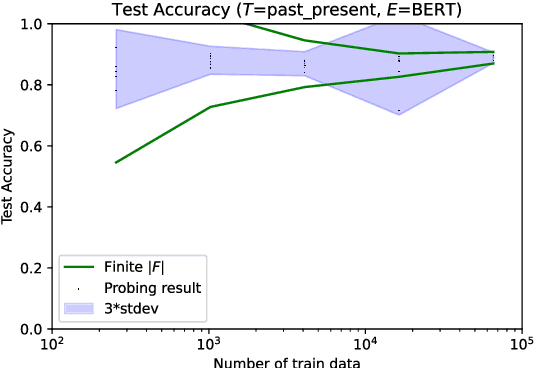
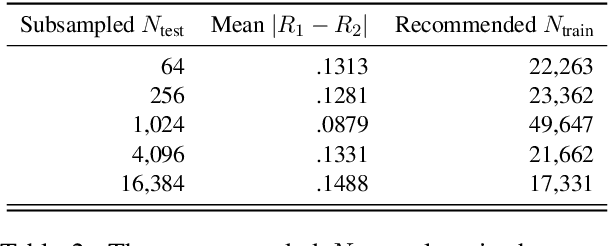
As large and powerful neural language models are developed, researchers have been increasingly interested in developing diagnostic tools to probe them. There are many papers with conclusions of the form "observation X is found in model Y", using their own datasets with varying sizes. Larger probing datasets bring more reliability, but are also expensive to collect. There is yet to be a quantitative method for estimating reasonable probing dataset sizes. We tackle this omission in the context of comparing two probing configurations: after we have collected a small dataset from a pilot study, how many additional data samples are sufficient to distinguish two different configurations? We present a novel method to estimate the required number of data samples in such experiments and, across several case studies, we verify that our estimations have sufficient statistical power. Our framework helps to systematically construct probing datasets to diagnose neural NLP models.
Grad2Task: Improved Few-shot Text Classification Using Gradients for Task Representation
Jan 27, 2022
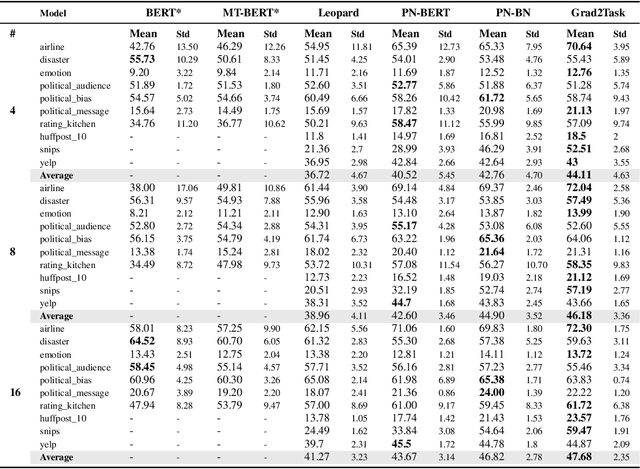
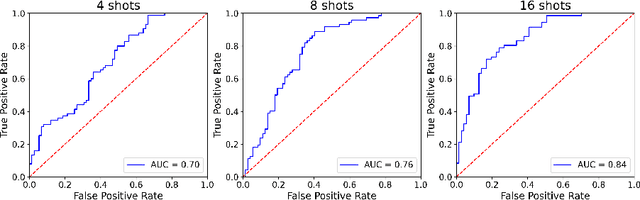
Large pretrained language models (LMs) like BERT have improved performance in many disparate natural language processing (NLP) tasks. However, fine tuning such models requires a large number of training examples for each target task. Simultaneously, many realistic NLP problems are "few shot", without a sufficiently large training set. In this work, we propose a novel conditional neural process-based approach for few-shot text classification that learns to transfer from other diverse tasks with rich annotation. Our key idea is to represent each task using gradient information from a base model and to train an adaptation network that modulates a text classifier conditioned on the task representation. While previous task-aware few-shot learners represent tasks by input encoding, our novel task representation is more powerful, as the gradient captures input-output relationships of a task. Experimental results show that our approach outperforms traditional fine-tuning, sequential transfer learning, and state-of-the-art meta learning approaches on a collection of diverse few-shot tasks. We further conducted analysis and ablations to justify our design choices.
Speaker attribution with voice profiles by graph-based semi-supervised learning
Feb 06, 2021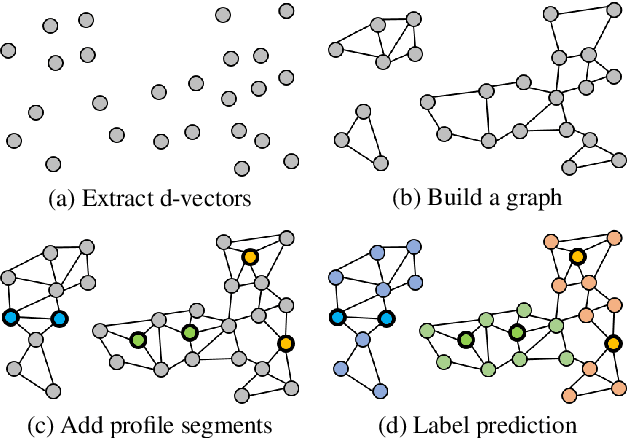
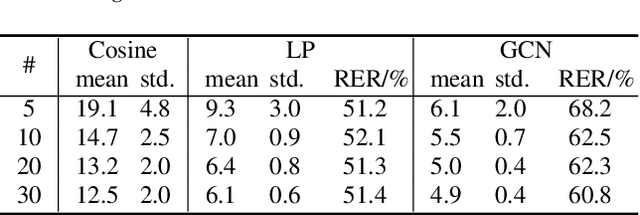
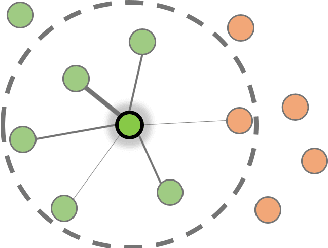
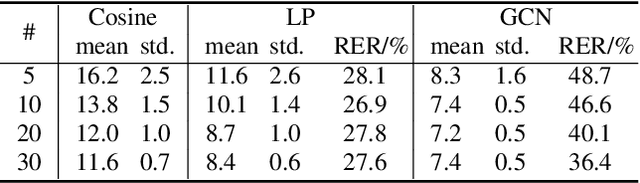
Speaker attribution is required in many real-world applications, such as meeting transcription, where speaker identity is assigned to each utterance according to speaker voice profiles. In this paper, we propose to solve the speaker attribution problem by using graph-based semi-supervised learning methods. A graph of speech segments is built for each session, on which segments from voice profiles are represented by labeled nodes while segments from test utterances are unlabeled nodes. The weight of edges between nodes is evaluated by the similarities between the pretrained speaker embeddings of speech segments. Speaker attribution then becomes a semi-supervised learning problem on graphs, on which two graph-based methods are applied: label propagation (LP) and graph neural networks (GNNs). The proposed approaches are able to utilize the structural information of the graph to improve speaker attribution performance. Experimental results on real meeting data show that the graph based approaches reduce speaker attribution error by up to 68% compared to a baseline speaker identification approach that processes each utterance independently.
Encoding Syntactic Knowledge in Transformer Encoder for Intent Detection and Slot Filling
Dec 21, 2020



We propose a novel Transformer encoder-based architecture with syntactical knowledge encoded for intent detection and slot filling. Specifically, we encode syntactic knowledge into the Transformer encoder by jointly training it to predict syntactic parse ancestors and part-of-speech of each token via multi-task learning. Our model is based on self-attention and feed-forward layers and does not require external syntactic information to be available at inference time. Experiments show that on two benchmark datasets, our models with only two Transformer encoder layers achieve state-of-the-art results. Compared to the previously best performed model without pre-training, our models achieve absolute F1 score and accuracy improvement of 1.59% and 0.85% for slot filling and intent detection on the SNIPS dataset, respectively. Our models also achieve absolute F1 score and accuracy improvement of 0.1% and 0.34% for slot filling and intent detection on the ATIS dataset, respectively, over the previously best performed model. Furthermore, the visualization of the self-attention weights illustrates the benefits of incorporating syntactic information during training.
Speaker diarization with session-level speaker embedding refinement using graph neural networks
May 22, 2020
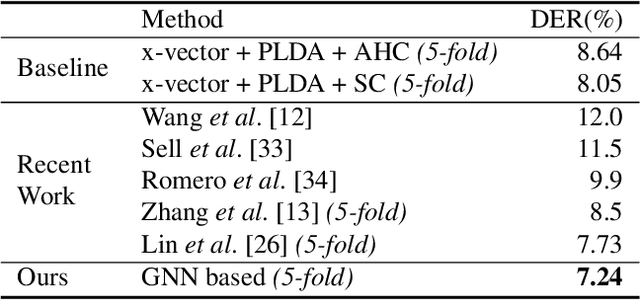
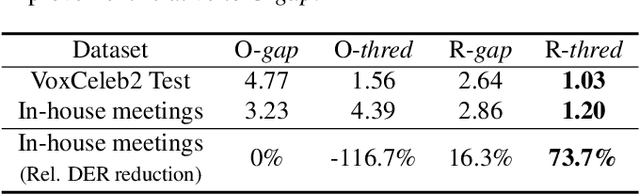
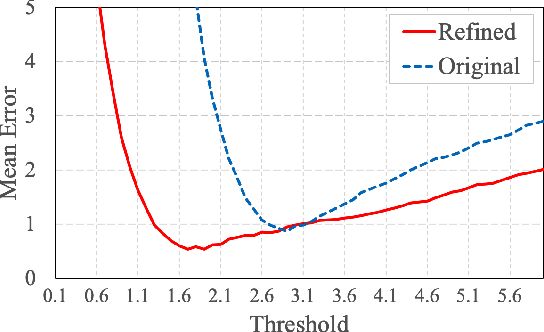
Deep speaker embedding models have been commonly used as a building block for speaker diarization systems; however, the speaker embedding model is usually trained according to a global loss defined on the training data, which could be sub-optimal for distinguishing speakers locally in a specific meeting session. In this work we present the first use of graph neural networks (GNNs) for the speaker diarization problem, utilizing a GNN to refine speaker embeddings locally using the structural information between speech segments inside each session. The speaker embeddings extracted by a pre-trained model are remapped into a new embedding space, in which the different speakers within a single session are better separated. The model is trained for linkage prediction in a supervised manner by minimizing the difference between the affinity matrix constructed by the refined embeddings and the ground-truth adjacency matrix. Spectral clustering is then applied on top of the refined embeddings. We show that the clustering performance of the refined speaker embeddings outperforms the original embeddings significantly on both simulated and real meeting data, and our system achieves the state-of-the-art result on the NIST SRE 2000 CALLHOME database.
Training without training data: Improving the generalizability of automated medical abbreviation disambiguation
Dec 12, 2019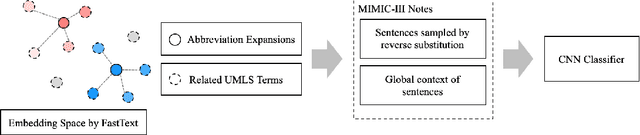
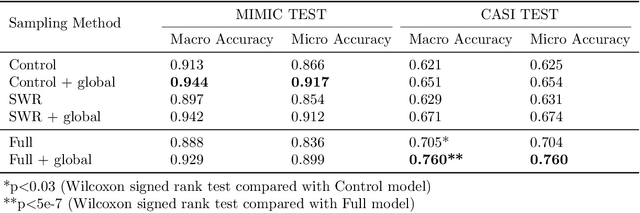
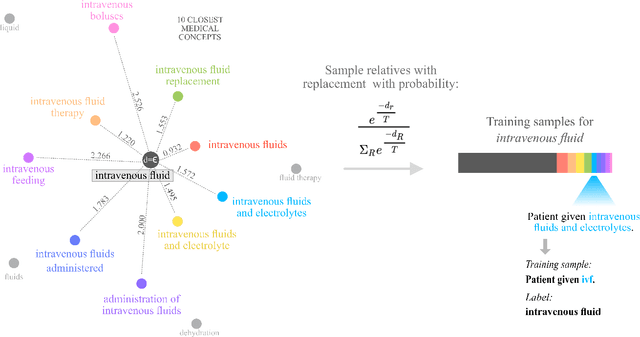
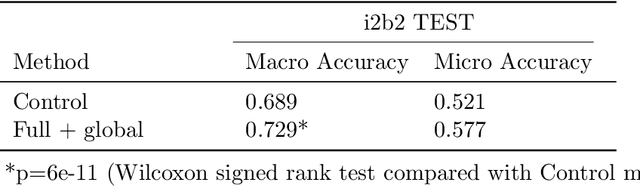
Abbreviation disambiguation is important for automated clinical note processing due to the frequent use of abbreviations in clinical settings. Current models for automated abbreviation disambiguation are restricted by the scarcity and imbalance of labeled training data, decreasing their generalizability to orthogonal sources. In this work we propose a novel data augmentation technique that utilizes information from related medical concepts, which improves our model's ability to generalize. Furthermore, we show that incorporating the global context information within the whole medical note (in addition to the traditional local context window), can significantly improve the model's representation for abbreviations. We train our model on a public dataset (MIMIC III) and test its performance on datasets from different sources (CASI, i2b2). Together, these two techniques boost the accuracy of abbreviation disambiguation by almost 14% on the CASI dataset and 4% on i2b2.