 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker attribution with voice profiles by graph-based semi-supervised learning
Feb 06, 2021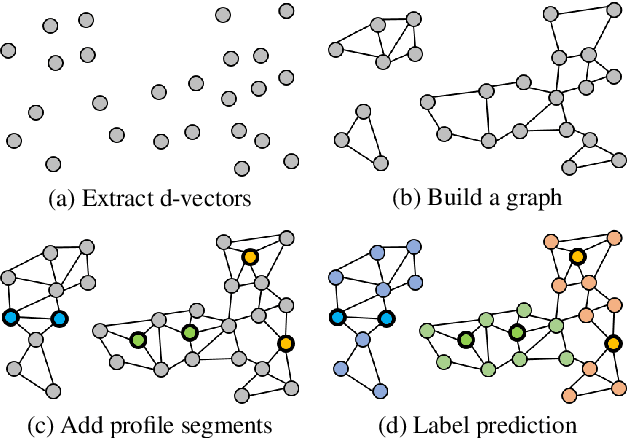
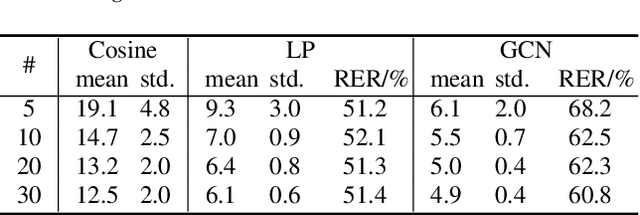
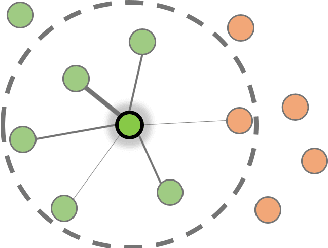
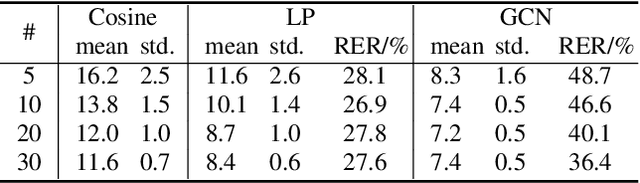
Speaker attribution is required in many real-world applications, such as meeting transcription, where speaker identity is assigned to each utterance according to speaker voice profiles. In this paper, we propose to solve the speaker attribution problem by using graph-based semi-supervised learning methods. A graph of speech segments is built for each session, on which segments from voice profiles are represented by labeled nodes while segments from test utterances are unlabeled nodes. The weight of edges between nodes is evaluated by the similarities between the pretrained speaker embeddings of speech segments. Speaker attribution then becomes a semi-supervised learning problem on graphs, on which two graph-based methods are applied: label propagation (LP) and graph neural networks (GNNs). The proposed approaches are able to utilize the structural information of the graph to improve speaker attribution performance. Experimental results on real meeting data show that the graph based approaches reduce speaker attribution error by up to 68% compared to a baseline speaker identification approach that processes each utterance independently.
Speaker diarization with session-level speaker embedding refinement using graph neural networks
May 22, 2020
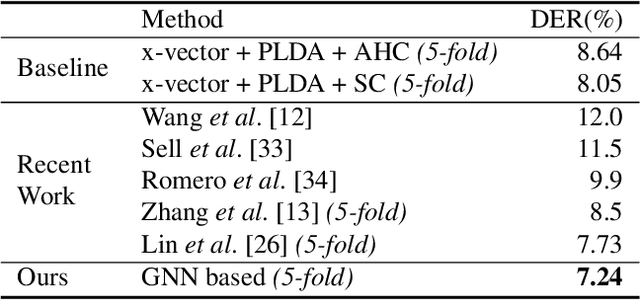
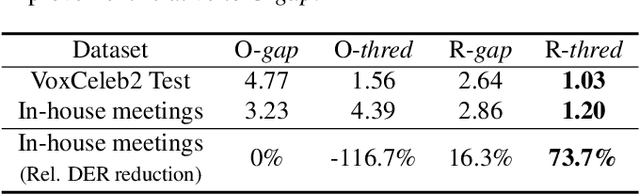
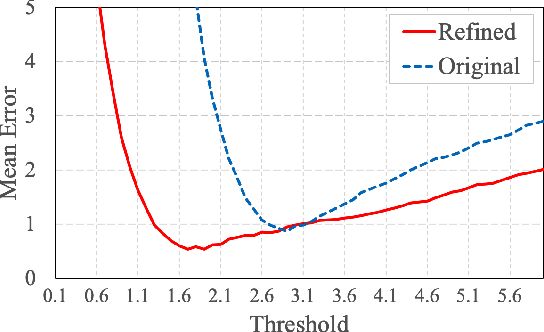
Deep speaker embedding models have been commonly used as a building block for speaker diarization systems; however, the speaker embedding model is usually trained according to a global loss defined on the training data, which could be sub-optimal for distinguishing speakers locally in a specific meeting session. In this work we present the first use of graph neural networks (GNNs) for the speaker diarization problem, utilizing a GNN to refine speaker embeddings locally using the structural information between speech segments inside each session. The speaker embeddings extracted by a pre-trained model are remapped into a new embedding space, in which the different speakers within a single session are better separated. The model is trained for linkage prediction in a supervised manner by minimizing the difference between the affinity matrix constructed by the refined embeddings and the ground-truth adjacency matrix. Spectral clustering is then applied on top of the refined embeddings. We show that the clustering performance of the refined speaker embeddings outperforms the original embeddings significantly on both simulated and real meeting data, and our system achieves the state-of-the-art result on the NIST SRE 2000 CALLHOME database.