 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIFT: Latent Implicit Functions for Task- and Data-Agnostic Encoding
Mar 19, 2025Implicit Neural Representations (INRs) are proving to be a powerful paradigm in unifying task modeling across diverse data domains, offering key advantages such as memory efficiency and resolution independence. Conventional deep learning models are typically modality-dependent, often requiring custom architectures and objectives for different types of signals. However, existing INR frameworks frequently rely on global latent vectors or exhibit computational inefficiencies that limit their broader applicability. We introduce LIFT, a novel, high-performance framework that addresses these challenges by capturing multiscale information through meta-learning. LIFT leverages multiple parallel localized implicit functions alongside a hierarchical latent generator to produce unified latent representations that span local, intermediate, and global features. This architecture facilitates smooth transitions across local regions, enhancing expressivity while maintaining inference efficiency. Additionally, we introduce ReLIFT, an enhanced variant of LIFT that incorporates residual connections and expressive frequency encodings. With this straightforward approach, ReLIFT effectively addresses the convergence-capacity gap found in comparable methods, providing an efficient yet powerful solution to improve capacity and speed up convergence. Empirical results show that LIFT achieves state-of-the-art (SOTA) performance in generative modeling and classification tasks, with notable reductions in computational costs. Moreover, in single-task settings, the streamlined ReLIFT architecture proves effective in signal representations and inverse problem tasks.
SUM: Saliency Unification through Mamba for Visual Attention Modeling
Jun 25, 2024

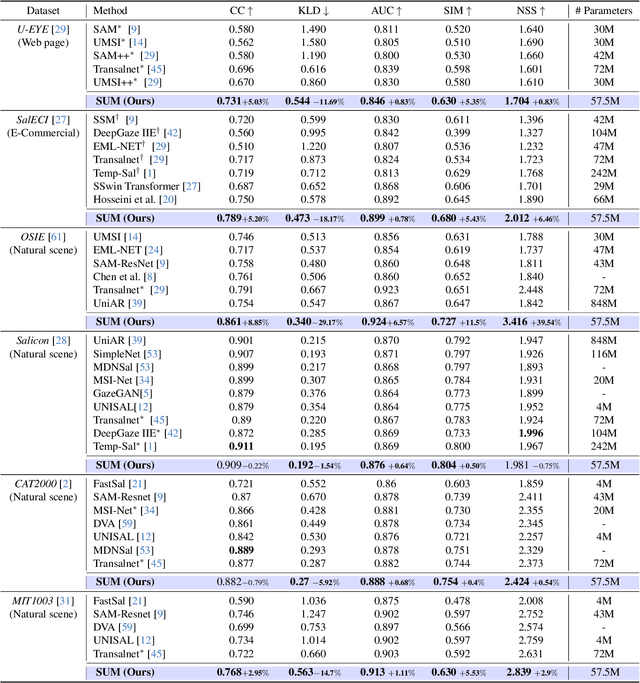

Visual attention modeling, important for interpreting and prioritizing visual stimuli, plays a significant role in applications such as marketing, multimedia, and robotics. Traditional saliency prediction models, especially those based on Convolutional Neural Networks (CNNs) or Transformers, achieve notable success by leveraging large-scale annotated datasets. However, the current state-of-the-art (SOTA) models that use Transformers are computationally expensive. Additionally, separate models are often required for each image type, lacking a unified approach. In this paper, we propose Saliency Unification through Mamba (SUM), a novel approach that integrates the efficient long-range dependency modeling of Mamba with U-Net to provide a unified model for diverse image types. Using a novel Conditional Visual State Space (C-VSS) block, SUM dynamically adapts to various image types, including natural scenes, web pages, and commercial imagery, ensuring universal applicability across different data types. Our comprehensive evaluations across five benchmarks demonstrate that SUM seamlessly adapts to different visual characteristics and consistently outperforms existing models. These results position SUM as a versatile and powerful tool for advancing visual attention modeling, offering a robust solution universally applicable across different types of visual content.
Grad2Task: Improved Few-shot Text Classification Using Gradients for Task Representation
Jan 27, 2022
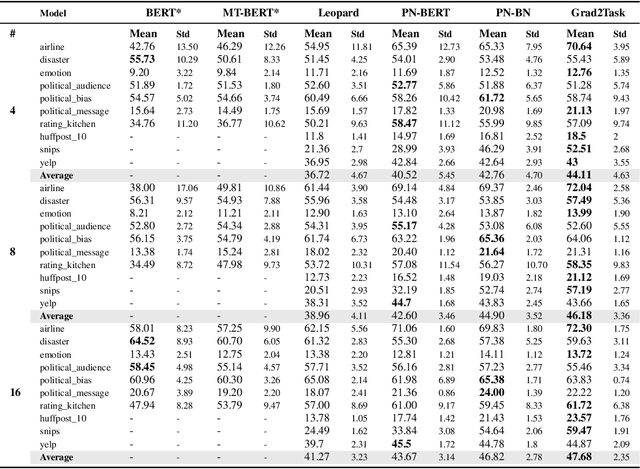
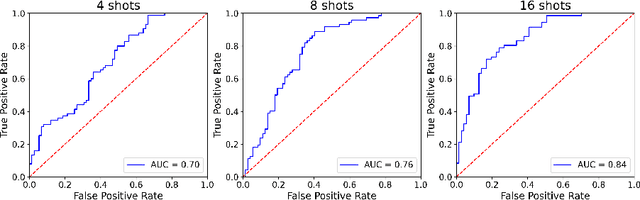
Large pretrained language models (LMs) like BERT have improved performance in many disparate natural language processing (NLP) tasks. However, fine tuning such models requires a large number of training examples for each target task. Simultaneously, many realistic NLP problems are "few shot", without a sufficiently large training set. In this work, we propose a novel conditional neural process-based approach for few-shot text classification that learns to transfer from other diverse tasks with rich annotation. Our key idea is to represent each task using gradient information from a base model and to train an adaptation network that modulates a text classifier conditioned on the task representation. While previous task-aware few-shot learners represent tasks by input encoding, our novel task representation is more powerful, as the gradient captures input-output relationships of a task. Experimental results show that our approach outperforms traditional fine-tuning, sequential transfer learning, and state-of-the-art meta learning approaches on a collection of diverse few-shot tasks. We further conducted analysis and ablations to justify our design choices.
Speaker attribution with voice profiles by graph-based semi-supervised learning
Feb 06, 2021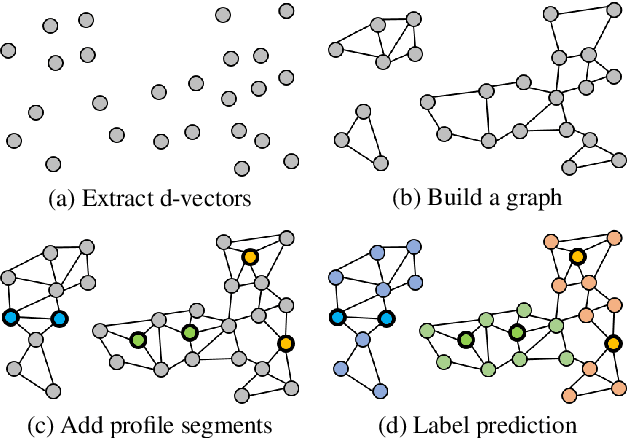
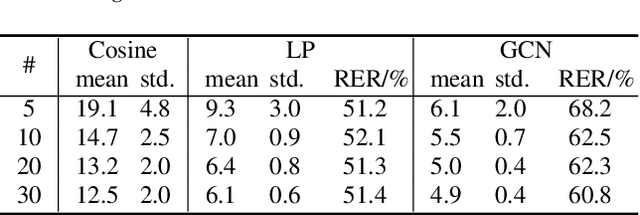
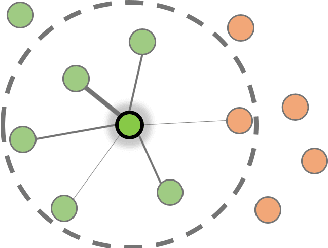
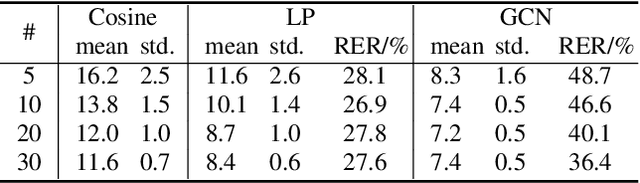
Speaker attribution is required in many real-world applications, such as meeting transcription, where speaker identity is assigned to each utterance according to speaker voice profiles. In this paper, we propose to solve the speaker attribution problem by using graph-based semi-supervised learning methods. A graph of speech segments is built for each session, on which segments from voice profiles are represented by labeled nodes while segments from test utterances are unlabeled nodes. The weight of edges between nodes is evaluated by the similarities between the pretrained speaker embeddings of speech segments. Speaker attribution then becomes a semi-supervised learning problem on graphs, on which two graph-based methods are applied: label propagation (LP) and graph neural networks (GNNs). The proposed approaches are able to utilize the structural information of the graph to improve speaker attribution performance. Experimental results on real meeting data show that the graph based approaches reduce speaker attribution error by up to 68% compared to a baseline speaker identification approach that processes each utterance independently.
Speaker diarization with session-level speaker embedding refinement using graph neural networks
May 22, 2020
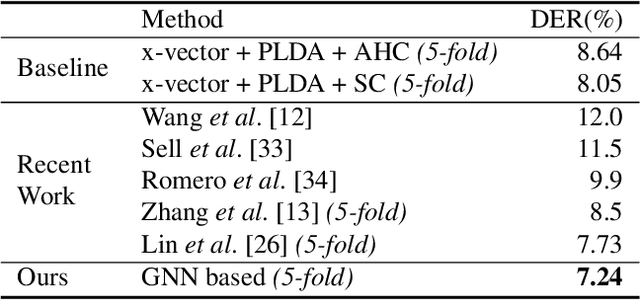
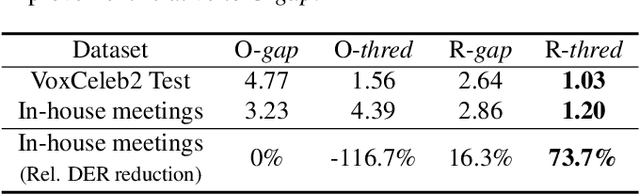
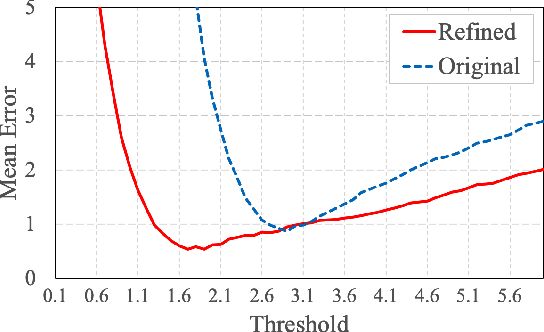
Deep speaker embedding models have been commonly used as a building block for speaker diarization systems; however, the speaker embedding model is usually trained according to a global loss defined on the training data, which could be sub-optimal for distinguishing speakers locally in a specific meeting session. In this work we present the first use of graph neural networks (GNNs) for the speaker diarization problem, utilizing a GNN to refine speaker embeddings locally using the structural information between speech segments inside each session. The speaker embeddings extracted by a pre-trained model are remapped into a new embedding space, in which the different speakers within a single session are better separated. The model is trained for linkage prediction in a supervised manner by minimizing the difference between the affinity matrix constructed by the refined embeddings and the ground-truth adjacency matrix. Spectral clustering is then applied on top of the refined embeddings. We show that the clustering performance of the refined speaker embeddings outperforms the original embeddings significantly on both simulated and real meeting data, and our system achieves the state-of-the-art result on the NIST SRE 2000 CALLHOME database.
Training without training data: Improving the generalizability of automated medical abbreviation disambiguation
Dec 12, 2019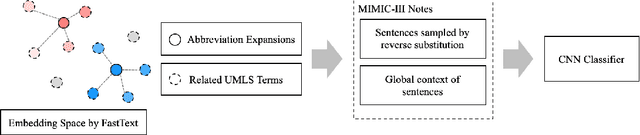
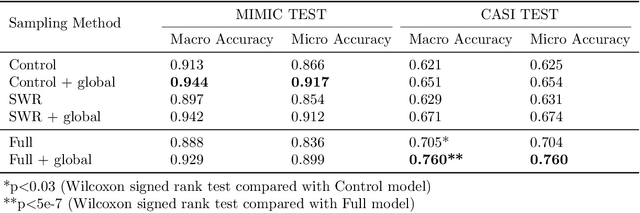
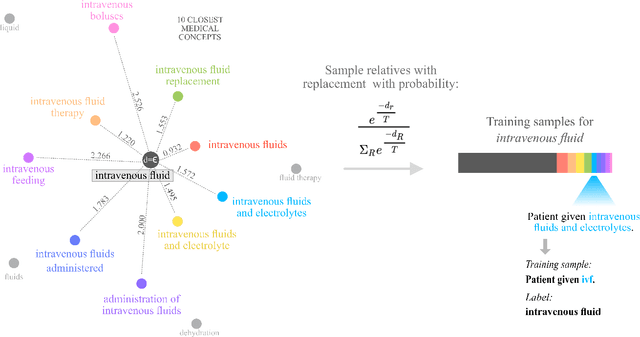
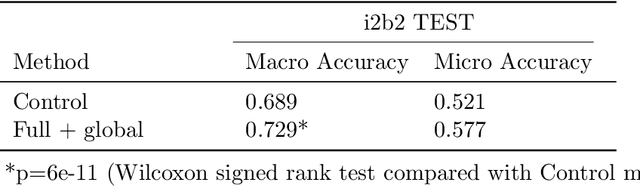
Abbreviation disambiguation is important for automated clinical note processing due to the frequent use of abbreviations in clinical settings. Current models for automated abbreviation disambiguation are restricted by the scarcity and imbalance of labeled training data, decreasing their generalizability to orthogonal sources. In this work we propose a novel data augmentation technique that utilizes information from related medical concepts, which improves our model's ability to generalize. Furthermore, we show that incorporating the global context information within the whole medical note (in addition to the traditional local context window), can significantly improve the model's representation for abbreviations. We train our model on a public dataset (MIMIC III) and test its performance on datasets from different sources (CASI, i2b2). Together, these two techniques boost the accuracy of abbreviation disambiguation by almost 14% on the CASI dataset and 4% on i2b2.
Centroid-based deep metric learning for speaker recognition
Feb 06, 2019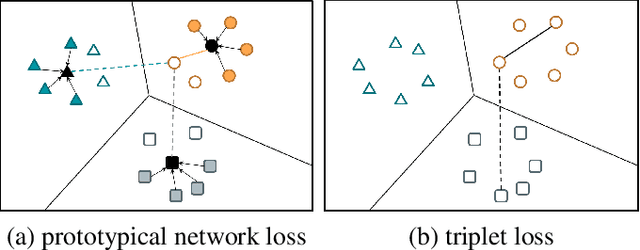
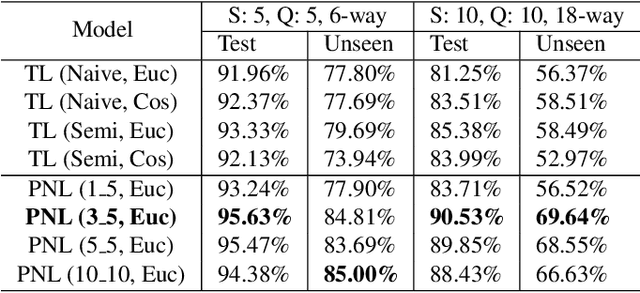
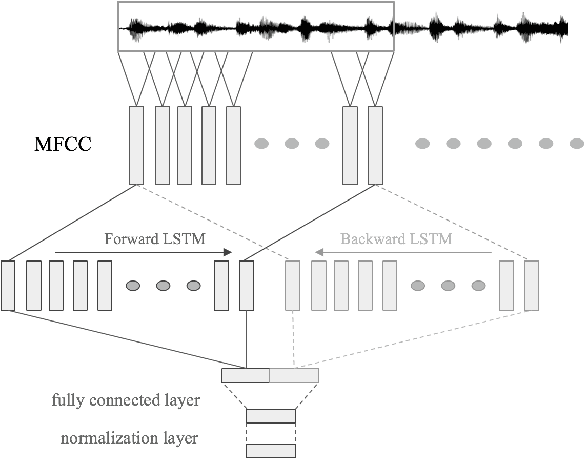
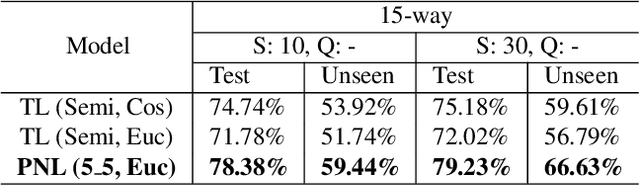
Speaker embedding models that utilize neural networks to map utterances to a space where distances reflect similarity between speakers have driven recent progress in the speaker recognition task. However, there is still a significant performance gap between recognizing speakers in the training set and unseen speakers. The latter case corresponds to the few-shot learning task, where a trained model is evaluated on unseen classes. Here, we optimize a speaker embedding model with prototypical network loss (PNL), a state-of-the-art approach for the few-shot image classification task. The resulting embedding model outperforms the state-of-the-art triplet loss based models in both speaker verification and identification tasks, for both seen and unseen speakers.