 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2D2: Relational Text Decoding with Transformers
May 10, 2021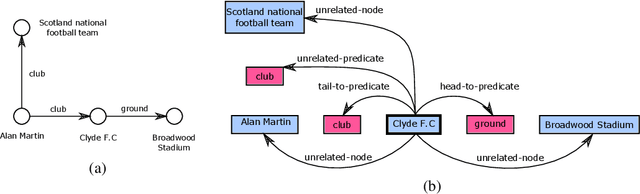
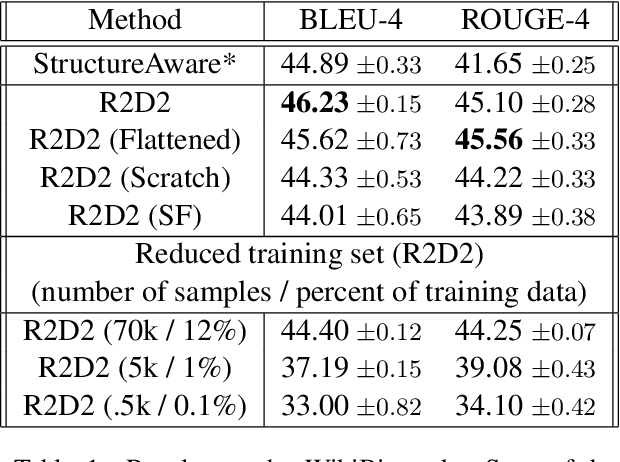
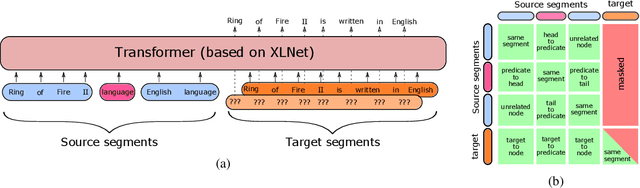
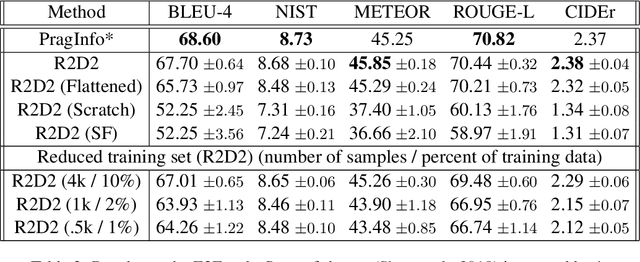
We propose a novel framework for modeling the interaction between graphical structures and the natural language text associated with their nodes and edges. Existing approaches typically fall into two categories. On group ignores the relational structure by converting them into linear sequences and then utilize the highly successful Seq2Seq models. The other side ignores the sequential nature of the text by representing them as fixed-dimensional vectors and apply graph neural networks. Both simplifications lead to information loss. Our proposed method utilizes both the graphical structure as well as the sequential nature of the texts. The input to our model is a set of text segments associated with the nodes and edges of the graph, which are then processed with a transformer encoder-decoder model, equipped with a self-attention mechanism that is aware of the graphical relations between the nodes containing the segments. This also allows us to use BERT-like models that are already trained on large amounts of text. While the proposed model has wide applications, we demonstrate its capabilities on data-to-text generation tasks. Our approach compares favorably against state-of-the-art methods in four tasks without tailoring the model architecture. We also provide an early demonstration in a novel practical application -- generating clinical notes from the medical entities mentioned during clinical visits.
Training without training data: Improving the generalizability of automated medical abbreviation disambiguation
Dec 12, 2019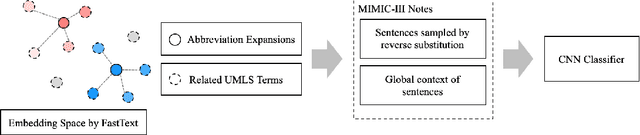
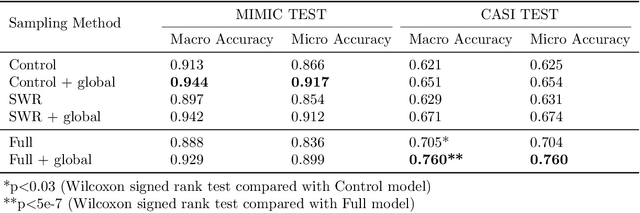
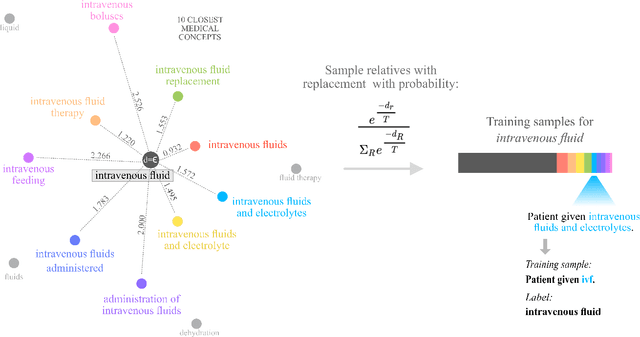
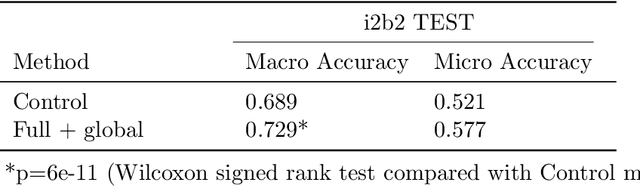
Abbreviation disambiguation is important for automated clinical note processing due to the frequent use of abbreviations in clinical settings. Current models for automated abbreviation disambiguation are restricted by the scarcity and imbalance of labeled training data, decreasing their generalizability to orthogonal sources. In this work we propose a novel data augmentation technique that utilizes information from related medical concepts, which improves our model's ability to generalize. Furthermore, we show that incorporating the global context information within the whole medical note (in addition to the traditional local context window), can significantly improve the model's representation for abbreviations. We train our model on a public dataset (MIMIC III) and test its performance on datasets from different sources (CASI, i2b2). Together, these two techniques boost the accuracy of abbreviation disambiguation by almost 14% on the CASI dataset and 4% on i2b2.
$β$-VAEs can retain label information even at high compression
Dec 06, 2018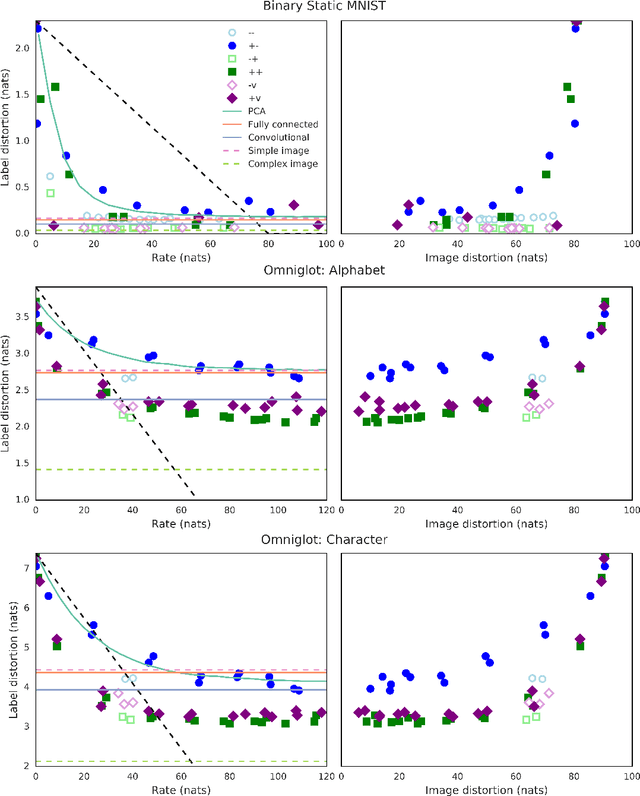
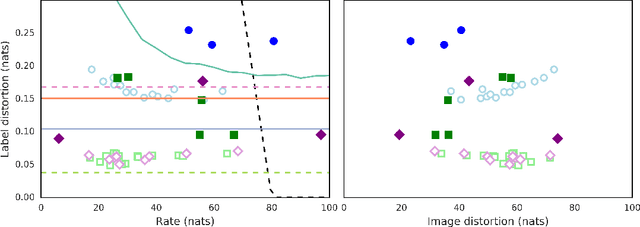
In this paper, we investigate the degree to which the encoding of a $\beta$-VAE captures label information across multiple architectures on Binary Static MNIST and Omniglot. Even though they are trained in a completely unsupervised manner, we demonstrate that a $\beta$-VAE can retain a large amount of label information, even when asked to learn a highly compressed representation.