Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$β$-VAEs can retain label information even at high compression
Paper and Code
Dec 06, 2018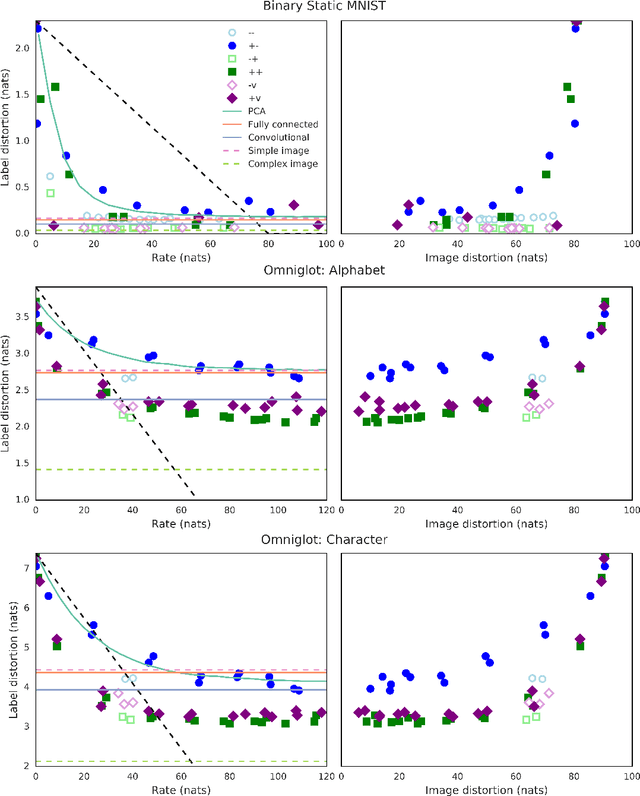
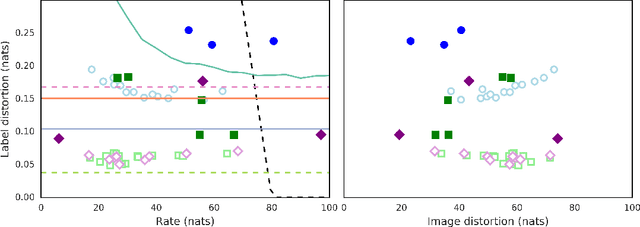
In this paper, we investigate the degree to which the encoding of a $\beta$-VAE captures label information across multiple architectures on Binary Static MNIST and Omniglot. Even though they are trained in a completely unsupervised manner, we demonstrate that a $\beta$-VAE can retain a large amount of label information, even when asked to learn a highly compressed representation.
* NeurIPS2018, BDL workshop
View paper on