 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUM: Saliency Unification through Mamba for Visual Attention Modeling
Paper and Code


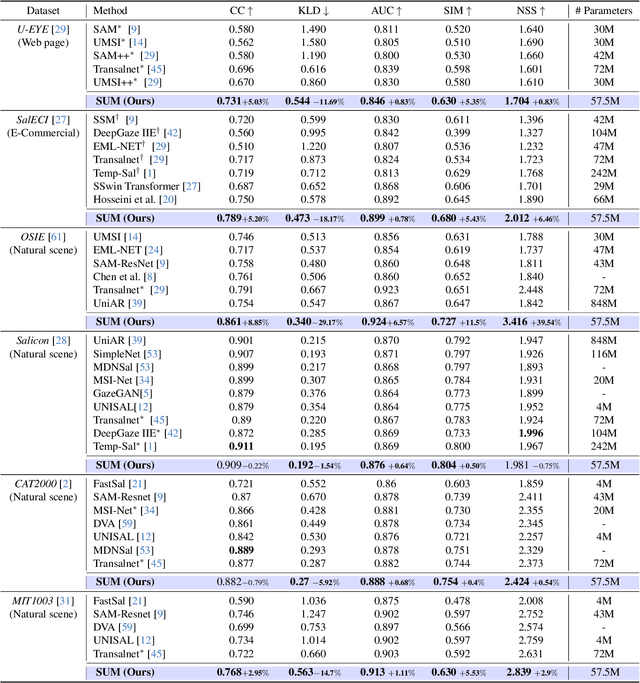

Visual attention modeling, important for interpreting and prioritizing visual stimuli, plays a significant role in applications such as marketing, multimedia, and robotics. Traditional saliency prediction models, especially those based on Convolutional Neural Networks (CNNs) or Transformers, achieve notable success by leveraging large-scale annotated datasets. However, the current state-of-the-art (SOTA) models that use Transformers are computationally expensive. Additionally, separate models are often required for each image type, lacking a unified approach. In this paper, we propose Saliency Unification through Mamba (SUM), a novel approach that integrates the efficient long-range dependency modeling of Mamba with U-Net to provide a unified model for diverse image types. Using a novel Conditional Visual State Space (C-VSS) block, SUM dynamically adapts to various image types, including natural scenes, web pages, and commercial imagery, ensuring universal applicability across different data types. Our comprehensive evaluations across five benchmarks demonstrate that SUM seamlessly adapts to different visual characteristics and consistently outperforms existing models. These results position SUM as a versatile and powerful tool for advancing visual attention modeling, offering a robust solution universally applicable across different types of visual content.