 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIR-VLA+: Decoupling Movement and Manipulation via Cascaded Dual-Action Decoders with Asymmetric MoE for Aerial Robots
Jun 11, 2026Aerial manipulation systems have long suffered from representation coupling in end-to-end control, as platform-level Unmanned Aerial Vehicle (UAV) movement and end-effector-level arm manipulation differ substantially in action scale, dynamics, and control objectives. In this paper, we propose AIR-VLA+, a flow matching action generation architecture specifically designed for aerial manipulation, featuring cascaded dual-action decoders and an asymmetric feature-level Mixture of Experts (MoE). We construct cascaded manipulation and movement decoders, allowing the UAV to unidirectionally observe the manipulator's intent during movement to achieve workflow coordination, while isolating the impact of UAV movement information backpropagation on arm manipulation stability. Addressing the characteristic that UAV movement is highly dependent on high-level semantics and responsible for task state transitions in aerial manipulation, we design an input feature enhancement module for the UAV movement decoder. This module introduces an implicit visual grasp projector to perceive the interaction state between the gripper and the object, and injects compressed global semantic features. Within the UAV movement decoder, we deploy an implicit MoE architecture, enabling different movement experts to spontaneously exhibit capacity inclinations for various task stages during training. Through dense soft blending computation on the feature manifold, the UAV movement is endowed with stronger task-stage adaptability. Experiments on the standardized AIR-VLA benchmark demonstrate that our method comprehensively surpasses all baselines with an overall average score of 48.0. The overall task completion score improves by 80.2\% compared to the single-head $π_{0.5}$ policy, effectively mitigating the heterogeneous coordinated control conflicts of composite robots.
DARTS: A Drone-Based AI-Powered Real-Time Traffic Incident Detection System
Oct 29, 2025Rapid and reliable incident detection is critical for reducing crash-related fatalities, injuries, and congestion. However, conventional methods, such as closed-circuit television, dashcam footage, and sensor-based detection, separate detection from verification, suffer from limited flexibility, and require dense infrastructure or high penetration rates, restricting adaptability and scalability to shifting incident hotspots. To overcome these challenges, we developed DARTS, a drone-based, AI-powered real-time traffic incident detection system. DARTS integrates drones' high mobility and aerial perspective for adaptive surveillance, thermal imaging for better low-visibility performance and privacy protection, and a lightweight deep learning framework for real-time vehicle trajectory extraction and incident detection. The system achieved 99% detection accuracy on a self-collected dataset and supports simultaneous online visual verification, severity assessment, and incident-induced congestion propagation monitoring via a web-based interface. In a field test on Interstate 75 in Florida, DARTS detected and verified a rear-end collision 12 minutes earlier than the local transportation management center and monitored incident-induced congestion propagation, suggesting potential to support faster emergency response and enable proactive traffic control to reduce congestion and secondary crash risk. Crucially, DARTS's flexible deployment architecture reduces dependence on frequent physical patrols, indicating potential scalability and cost-effectiveness for use in remote areas and resource-constrained settings. This study presents a promising step toward a more flexible and integrated real-time traffic incident detection system, with significant implications for the operational efficiency and responsiveness of modern transportation management.
UAVs Meet LLMs: Overviews and Perspectives Toward Agentic Low-Altitude Mobility
Jan 04, 2025Low-altitude mobility, exemplified by unmanned aerial vehicles (UAVs), has introduced transformative advancements across various domains, like transportation, logistics, and agriculture. Leveraging flexible perspectives and rapid maneuverability, UAVs extend traditional systems' perception and action capabilities, garnering widespread attention from academia and industry. However, current UAV operations primarily depend on human control, with only limited autonomy in simple scenarios, and lack the intelligence and adaptability needed for more complex environments and tasks. The emergence of large language models (LLMs) demonstrates remarkable problem-solving and generalization capabilities, offering a promising pathway for advancing UAV intelligence. This paper explores the integration of LLMs and UAVs, beginning with an overview of UAV systems' fundamental components and functionalities, followed by an overview of the state-of-the-art in LLM technology. Subsequently, it systematically highlights the multimodal data resources available for UAVs, which provide critical support for training and evaluation. Furthermore, it categorizes and analyzes key tasks and application scenarios where UAVs and LLMs converge. Finally, a reference roadmap towards agentic UAVs is proposed, aiming to enable UAVs to achieve agentic intelligence through autonomous perception, memory, reasoning, and tool utilization. Related resources are available at https://github.com/Hub-Tian/UAVs_Meet_LLMs.
Milestones in Autonomous Driving and Intelligent Vehicles Part II: Perception and Planning
Jun 03, 2023



Growing interest in autonomous driving (AD) and intelligent vehicles (IVs) is fueled by their promise for enhanced safety, efficiency, and economic benefits. While previous surveys have captured progress in this field, a comprehensive and forward-looking summary is needed. Our work fills this gap through three distinct articles. The first part, a "Survey of Surveys" (SoS), outlines the history, surveys, ethics, and future directions of AD and IV technologies. The second part, "Milestones in Autonomous Driving and Intelligent Vehicles Part I: Control, Computing System Design, Communication, HD Map, Testing, and Human Behaviors" delves into the development of control, computing system, communication, HD map, testing, and human behaviors in IVs. This part, the third part, reviews perception and planning in the context of IVs. Aiming to provide a comprehensive overview of the latest advancements in AD and IVs, this work caters to both newcomers and seasoned researchers. By integrating the SoS and Part I, we offer unique insights and strive to serve as a bridge between past achievements and future possibilities in this dynamic field.
Milestones in Autonomous Driving and Intelligent Vehicles: Survey of Surveys
Mar 30, 2023



Interest in autonomous driving (AD) and intelligent vehicles (IVs) is growing at a rapid pace due to the convenience, safety, and economic benefits. Although a number of surveys have reviewed research achievements in this field, they are still limited in specific tasks, lack of systematic summary and research directions in the future. Here we propose a Survey of Surveys (SoS) for total technologies of AD and IVs that reviews the history, summarizes the milestones, and provides the perspectives, ethics, and future research directions. To our knowledge, this article is the first SoS with milestones in AD and IVs, which constitutes our complete research work together with two other technical surveys. We anticipate that this article will bring novel and diverse insights to researchers and abecedarians, and serve as a bridge between past and future.
* 13 pages, 3 tables, 0 figure
Motion Planning for Autonomous Driving: The State of the Art and Future Perspectives
Mar 29, 2023



Thanks to the augmented convenience, safety advantages, and potential commercial value, Intelligent vehicles (IVs) have attracted wide attention throughout the world. Although a few autonomous driving unicorns assert that IVs will be commercially deployable by 2025, their implementation is still restricted to small-scale validation due to various issues, among which precise computation of control commands or trajectories by planning methods remains a prerequisite for IVs. This paper aims to review state-of-the-art planning methods, including pipeline planning and end-to-end planning methods. In terms of pipeline methods, a survey of selecting algorithms is provided along with a discussion of the expansion and optimization mechanisms, whereas in end-to-end methods, the training approaches and verification scenarios of driving tasks are points of concern. Experimental platforms are reviewed to facilitate readers in selecting suitable training and validation methods. Finally, the current challenges and future directions are discussed. The side-by-side comparison presented in this survey not only helps to gain insights into the strengths and limitations of the reviewed methods but also assists with system-level design choices.
Embodied Footprints: A Safety-guaranteed Collision Avoidance Model for Numerical Optimization-based Trajectory Planning
Feb 15, 2023Numerical optimization-based methods are among the prevalent trajectory planners for autonomous driving. In a numerical optimization-based planner, the nominal continuous-time trajectory planning problem is discretized into a nonlinear program (NLP) problem with finite constraints imposed on finite collocation points. However, constraint violations between adjacent collocation points may still occur. This study proposes a safety-guaranteed collision-avoidance modeling method to eliminate the collision risks between adjacent collocation points in using numerical optimization-based trajectory planners. A new concept called embodied box is proposed, which is formed by enlarging the rectangular footprint of the ego vehicle. If one can ensure that the embodied boxes at finite collocation points are collide-free, then the ego vehicle's footprint is collide-free at any a moment between adjacent collocation points. We find that the geometric size of an embodied box is a simple function of vehicle velocity and curvature. The proposed theory lays a foundation for numerical optimization-based trajectory planners in autonomous driving.
Integrating Linguistic Theory and Neural Language Models
Jul 20, 2022
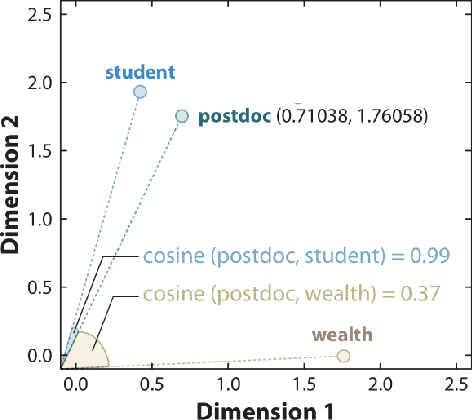

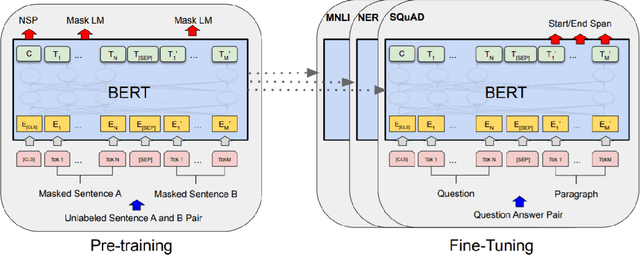
Transformer-based language models have recently achieved remarkable results in many natural language tasks. However, performance on leaderboards is generally achieved by leveraging massive amounts of training data, and rarely by encoding explicit linguistic knowledge into neural models. This has led many to question the relevance of linguistics for modern natural language processing. In this dissertation, I present several case studies to illustrate how theoretical linguistics and neural language models are still relevant to each other. First, language models are useful to linguists by providing an objective tool to measure semantic distance, which is difficult to do using traditional methods. On the other hand, linguistic theory contributes to language modelling research by providing frameworks and sources of data to probe our language models for specific aspects of language understanding. This thesis contributes three studies that explore different aspects of the syntax-semantics interface in language models. In the first part of my thesis, I apply language models to the problem of word class flexibility. Using mBERT as a source of semantic distance measurements, I present evidence in favour of analyzing word class flexibility as a directional process. In the second part of my thesis, I propose a method to measure surprisal at intermediate layers of language models. My experiments show that sentences containing morphosyntactic anomalies trigger surprisals earlier in language models than semantic and commonsense anomalies. Finally, in the third part of my thesis, I adapt several psycholinguistic studies to show that language models contain knowledge of argument structure constructions. In summary, my thesis develops new connections between natural language processing, linguistic theory, and psycholinguistics to provide fresh perspectives for the interpretation of language models.
On the data requirements of probing
Feb 25, 2022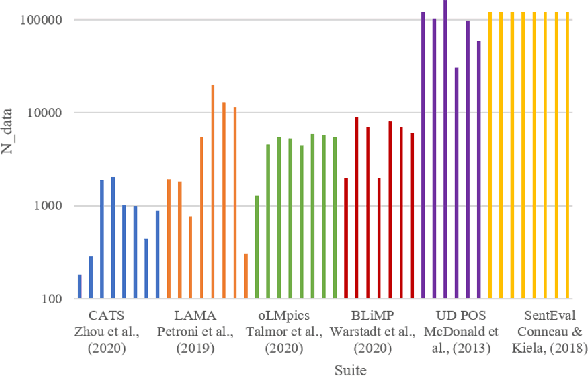

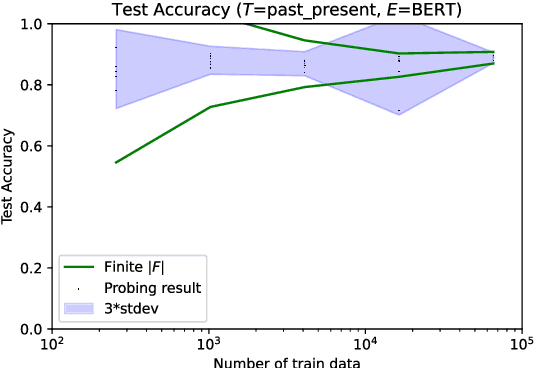
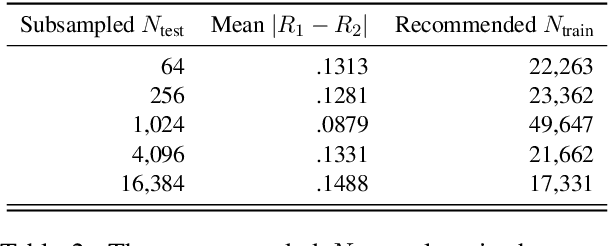
As large and powerful neural language models are developed, researchers have been increasingly interested in developing diagnostic tools to probe them. There are many papers with conclusions of the form "observation X is found in model Y", using their own datasets with varying sizes. Larger probing datasets bring more reliability, but are also expensive to collect. There is yet to be a quantitative method for estimating reasonable probing dataset sizes. We tackle this omission in the context of comparing two probing configurations: after we have collected a small dataset from a pilot study, how many additional data samples are sufficient to distinguish two different configurations? We present a novel method to estimate the required number of data samples in such experiments and, across several case studies, we verify that our estimations have sufficient statistical power. Our framework helps to systematically construct probing datasets to diagnose neural NLP models.
Neural reality of argument structure constructions
Feb 24, 2022

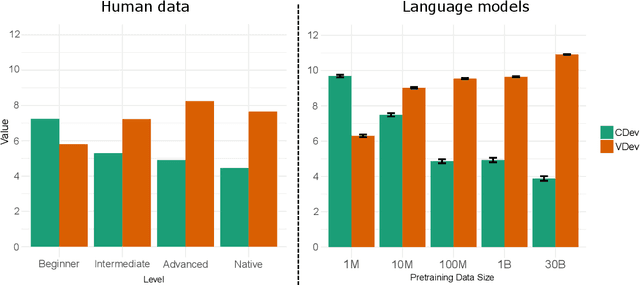
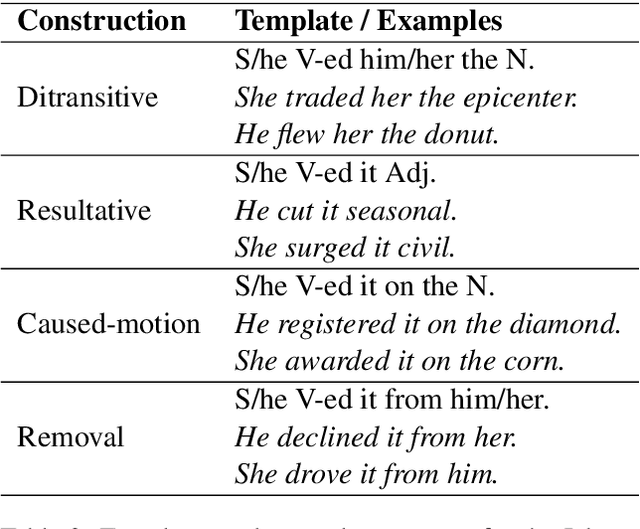
In lexicalist linguistic theories, argument structure is assumed to be predictable from the meaning of verbs. As a result, the verb is the primary determinant of the meaning of a clause. In contrast, construction grammarians propose that argument structure is encoded in constructions (or form-meaning pairs) that are distinct from verbs. Decades of psycholinguistic research have produced substantial empirical evidence in favor of the construction view. Here we adapt several psycholinguistic studies to probe for the existence of argument structure constructions (ASCs) in Transformer-based language models (LMs). First, using a sentence sorting experiment, we find that sentences sharing the same construction are closer in embedding space than sentences sharing the same verb. Furthermore, LMs increasingly prefer grouping by construction with more input data, mirroring the behaviour of non-native language learners. Second, in a "Jabberwocky" priming-based experiment, we find that LMs associate ASCs with meaning, even in semantically nonsensical sentences. Our work offers the first evidence for ASCs in LMs and highlights the potential to devise novel probing methods grounded in psycholinguistic research.