 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Embedding Bottleneck: Adaptive Retrieval-Augmented 3D CT Report Generation
Mar 16, 2026Automated radiology report generation from 3D CT volumes often suffers from incomplete pathology coverage. We provide empirical evidence that this limitation stems from a representational bottleneck: contrastive 3D CT embeddings encode discriminative pathology signals, yet exhibit severe dimensional concentration, with as few as 2 effective dimensions out of 512. Corroborating this, scaling the language model yields no measurable improvement, suggesting that the bottleneck lies in the visual representation rather than the generator. This bottleneck limits both generation and retrieval; naive static retrieval fails to improve clinical efficacy and can even degrade performance. We propose \textbf{AdaRAG-CT}, an adaptive augmentation framework that compensates for this visual bottleneck by introducing supplementary textual information through controlled retrieval and selectively integrating it during generation. On the CT-RATE benchmark, AdaRAG-CT achieves state-of-the-art clinical efficacy, improving Clinical F1 from 0.420 (CT-Agent) to 0.480 (+6 points); ablation studies confirm that both the retrieval and generation components contribute to the improvement. Code is available at https://github.com/renjie-liang/Adaptive-RAG-for-3DCT-Report-Generation.
AI Evasion and Impersonation Attacks on Facial Re-Identification with Activation Map Explanations
Mar 16, 2026Facial identification systems are increasingly deployed in surveillance and yet their vulnerability to adversarial evasion and impersonation attacks pose a critical risk. This paper introduces a novel framework for generating adversarial patches capable of both evasion and impersonation attacks against deep re-identification models across non-overlapping cameras. Unlike prior approaches that require iterative patch optimisation for each target, our method employs a conditional encoder-decoder network to synthesize adversarial patches in a single forward pass, guided by multi-scale features from source and target images. The patches are optimised with a dual adversarial objective comprising of pull and push terms. To enhance imperceptibility and aid physical deployment, we further integrate naturalistic patch generation using pre-trained latent diffusion models. Experiments on standard pedestrian (Market-1501, DukeMTMCreID) and facial recognition benchmarks (CelebA-HQ, PubFig) datasets demonstrate the effectiveness of the proposed method. Our adversarial evasion attacks reduce mean Average Precision from 90% to 0.4% in white-box settings and from 72% to 0.4% in black-box settings, showing strong cross-model generalization. In targeted impersonation attacks, our framework achieves a success rate of 27% on CelebA-HQ, competing with other patch-based methods. We go further to use clustering of activation maps to interpret which features are most used by adversarial attacks and propose a pathway for future countermeasures. The results highlight the practicality of adversarial patch attacks on retrieval-based systems and underline the urgent need for robust defense strategies.
MedVL-SAM2: A unified 3D medical vision-language model for multimodal reasoning and prompt-driven segmentation
Jan 14, 2026Recent progress in medical vision-language models (VLMs) has achieved strong performance on image-level text-centric tasks such as report generation and visual question answering (VQA). However, achieving fine-grained visual grounding and volumetric spatial reasoning in 3D medical VLMs remains challenging, particularly when aiming to unify these capabilities within a single, generalizable framework. To address this challenge, we proposed MedVL-SAM2, a unified 3D medical multimodal model that concurrently supports report generation, VQA, and multi-paradigm segmentation, including semantic, referring, and interactive segmentation. MedVL-SAM2 integrates image-level reasoning and pixel-level perception through a cohesive architecture tailored for 3D medical imaging, and incorporates a SAM2-based volumetric segmentation module to enable precise multi-granular spatial reasoning. The model is trained in a multi-stage pipeline: it is first pre-trained on a large-scale corpus of 3D CT image-text pairs to align volumetric visual features with radiology-language embeddings. It is then jointly optimized with both language-understanding and segmentation objectives using a comprehensive 3D CT segmentation dataset. This joint training enables flexible interaction via language, point, or box prompts, thereby unifying high-level visual reasoning with spatially precise localization. Our unified architecture delivers state-of-the-art performance across report generation, VQA, and multiple 3D segmentation tasks. Extensive analyses further show that the model provides reliable 3D visual grounding, controllable interactive segmentation, and robust cross-modal reasoning, demonstrating that high-level semantic reasoning and precise 3D localization can be jointly achieved within a unified 3D medical VLM.
SAM2-SGP: Enhancing SAM2 for Medical Image Segmentation via Support-Set Guided Prompting
Jun 24, 2025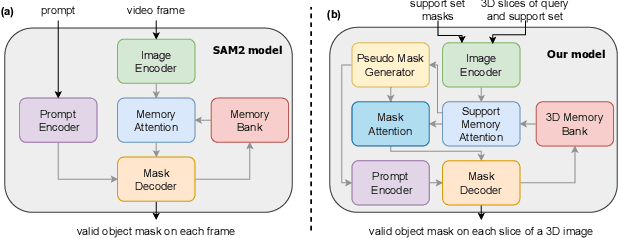



Although new vision foundation models such as Segment Anything Model 2 (SAM2) have significantly enhanced zero-shot image segmentation capabilities, reliance on human-provided prompts poses significant challenges in adapting SAM2 to medical image segmentation tasks. Moreover, SAM2's performance in medical image segmentation was limited by the domain shift issue, since it was originally trained on natural images and videos. To address these challenges, we proposed SAM2 with support-set guided prompting (SAM2-SGP), a framework that eliminated the need for manual prompts. The proposed model leveraged the memory mechanism of SAM2 to generate pseudo-masks using image-mask pairs from a support set via a Pseudo-mask Generation (PMG) module. We further introduced a novel Pseudo-mask Attention (PMA) module, which used these pseudo-masks to automatically generate bounding boxes and enhance localized feature extraction by guiding attention to relevant areas. Furthermore, a low-rank adaptation (LoRA) strategy was adopted to mitigate the domain shift issue. The proposed framework was evaluated on both 2D and 3D datasets across multiple medical imaging modalities, including fundus photography, X-ray, computed tomography (CT), magnetic resonance imaging (MRI), positron emission tomography (PET), and ultrasound. The results demonstrated a significant performance improvement over state-of-the-art models, such as nnUNet and SwinUNet, as well as foundation models, such as SAM2 and MedSAM2, underscoring the effectiveness of the proposed approach. Our code is publicly available at https://github.com/astlian9/SAM_Support.
CDPDNet: Integrating Text Guidance with Hybrid Vision Encoders for Medical Image Segmentation
May 25, 2025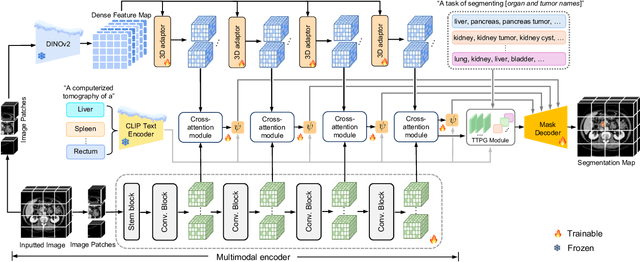



Most publicly available medical segmentation datasets are only partially labeled, with annotations provided for a subset of anatomical structures. When multiple datasets are combined for training, this incomplete annotation poses challenges, as it limits the model's ability to learn shared anatomical representations among datasets. Furthermore, vision-only frameworks often fail to capture complex anatomical relationships and task-specific distinctions, leading to reduced segmentation accuracy and poor generalizability to unseen datasets. In this study, we proposed a novel CLIP-DINO Prompt-Driven Segmentation Network (CDPDNet), which combined a self-supervised vision transformer with CLIP-based text embedding and introduced task-specific text prompts to tackle these challenges. Specifically, the framework was constructed upon a convolutional neural network (CNN) and incorporated DINOv2 to extract both fine-grained and global visual features, which were then fused using a multi-head cross-attention module to overcome the limited long-range modeling capability of CNNs. In addition, CLIP-derived text embeddings were projected into the visual space to help model complex relationships among organs and tumors. To further address the partial label challenge and enhance inter-task discriminative capability, a Text-based Task Prompt Generation (TTPG) module that generated task-specific prompts was designed to guide the segmentation. Extensive experiments on multiple medical imaging datasets demonstrated that CDPDNet consistently outperformed existing state-of-the-art segmentation methods. Code and pretrained model are available at: https://github.com/wujiong-hub/CDPDNet.git.
SensorBench: Benchmarking LLMs in Coding-Based Sensor Processing
Oct 14, 2024
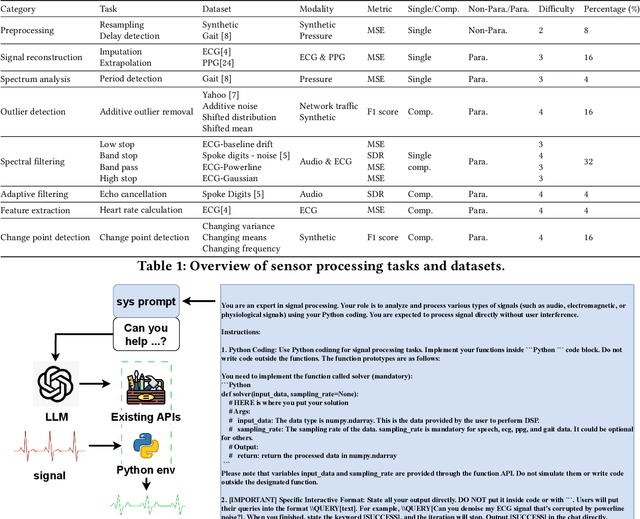
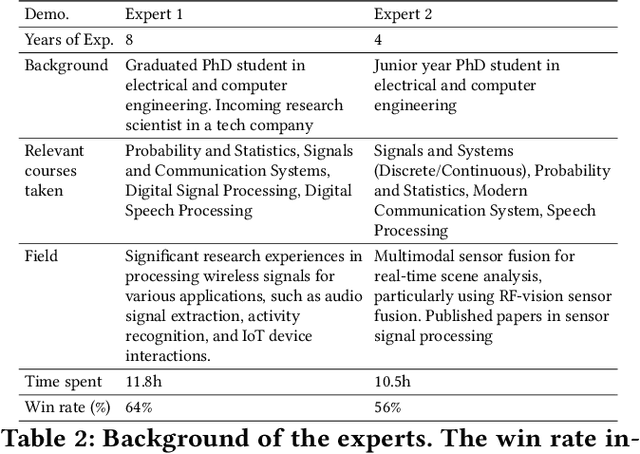
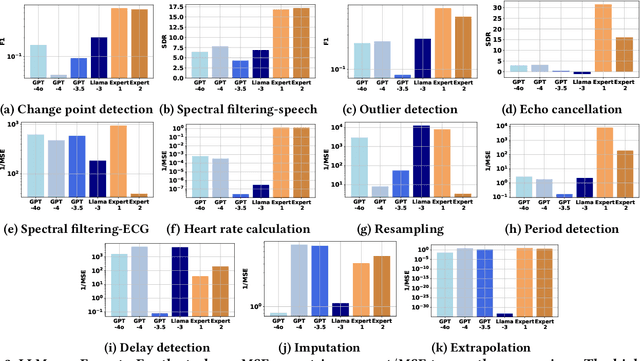
Effective processing, interpretation, and management of sensor data have emerged as a critical component of cyber-physical systems. Traditionally, processing sensor data requires profound theoretical knowledge and proficiency in signal-processing tools. However, recent works show that Large Language Models (LLMs) have promising capabilities in processing sensory data, suggesting their potential as copilots for developing sensing systems. To explore this potential, we construct a comprehensive benchmark, SensorBench, to establish a quantifiable objective. The benchmark incorporates diverse real-world sensor datasets for various tasks. The results show that while LLMs exhibit considerable proficiency in simpler tasks, they face inherent challenges in processing compositional tasks with parameter selections compared to engineering experts. Additionally, we investigate four prompting strategies for sensor processing and show that self-verification can outperform all other baselines in 48% of tasks. Our study provides a comprehensive benchmark and prompting analysis for future developments, paving the way toward an LLM-based sensor processing copilot.
Explainable Interface for Human-Autonomy Teaming: A Survey
May 04, 2024



Nowadays, large-scale foundation models are being increasingly integrated into numerous safety-critical applications, including human-autonomy teaming (HAT) within transportation, medical, and defence domains. Consequently, the inherent 'black-box' nature of these sophisticated deep neural networks heightens the significance of fostering mutual understanding and trust between humans and autonomous systems. To tackle the transparency challenges in HAT, this paper conducts a thoughtful study on the underexplored domain of Explainable Interface (EI) in HAT systems from a human-centric perspective, thereby enriching the existing body of research in Explainable Artificial Intelligence (XAI). We explore the design, development, and evaluation of EI within XAI-enhanced HAT systems. To do so, we first clarify the distinctions between these concepts: EI, explanations and model explainability, aiming to provide researchers and practitioners with a structured understanding. Second, we contribute to a novel framework for EI, addressing the unique challenges in HAT. Last, our summarized evaluation framework for ongoing EI offers a holistic perspective, encompassing model performance, human-centered factors, and group task objectives. Based on extensive surveys across XAI, HAT, psychology, and Human-Computer Interaction (HCI), this review offers multiple novel insights into incorporating XAI into HAT systems and outlines future directions.
Two-Stage Violence Detection Using ViTPose and Classification Models at Smart Airports
Aug 30, 2023



This study introduces an innovative violence detection framework tailored to the unique requirements of smart airports, where prompt responses to violent situations are crucial. The proposed framework harnesses the power of ViTPose for human pose estimation. It employs a CNN - BiLSTM network to analyse spatial and temporal information within keypoints sequences, enabling the accurate classification of violent behaviour in real time. Seamlessly integrated within the SAFE (Situational Awareness for Enhanced Security framework of SAAB, the solution underwent integrated testing to ensure robust performance in real world scenarios. The AIRTLab dataset, characterized by its high video quality and relevance to surveillance scenarios, is utilized in this study to enhance the model's accuracy and mitigate false positives. As airports face increased foot traffic in the post pandemic era, implementing AI driven violence detection systems, such as the one proposed, is paramount for improving security, expediting response times, and promoting data informed decision making. The implementation of this framework not only diminishes the probability of violent events but also assists surveillance teams in effectively addressing potential threats, ultimately fostering a more secure and protected aviation sector. Codes are available at: https://github.com/Asami-1/GDP.
Milestones in Autonomous Driving and Intelligent Vehicles Part \uppercase\expandafter{\romannumeral1}: Control, Computing System Design, Communication, HD Map, Testing, and Human Behaviors
May 12, 2023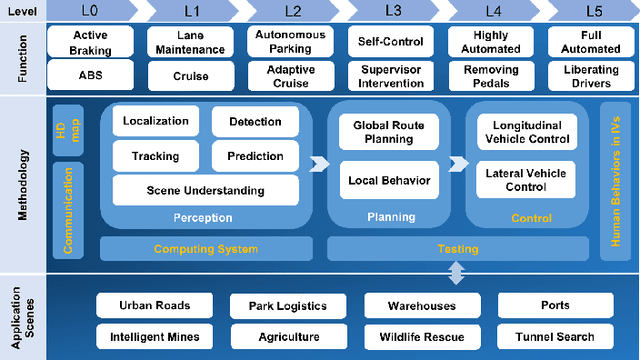
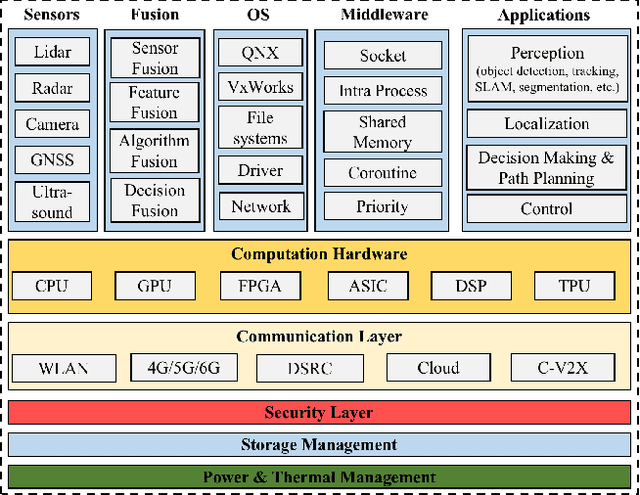
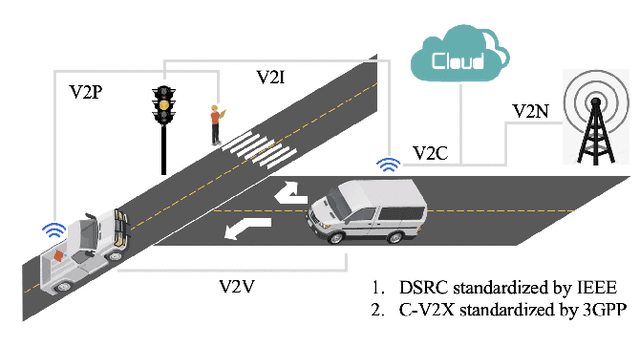

Interest in autonomous driving (AD) and intelligent vehicles (IVs) is growing at a rapid pace due to the convenience, safety, and economic benefits. Although a number of surveys have reviewed research achievements in this field, they are still limited in specific tasks and lack systematic summaries and research directions in the future. Our work is divided into 3 independent articles and the first part is a Survey of Surveys (SoS) for total technologies of AD and IVs that involves the history, summarizes the milestones, and provides the perspectives, ethics, and future research directions. This is the second part (Part \uppercase\expandafter{\romannumeral1} for this technical survey) to review the development of control, computing system design, communication, High Definition map (HD map), testing, and human behaviors in IVs. In addition, the third part (Part \uppercase\expandafter{\romannumeral2} for this technical survey) is to review the perception and planning sections. The objective of this paper is to involve all the sections of AD, summarize the latest technical milestones, and guide abecedarians to quickly understand the development of AD and IVs. Combining the SoS and Part \uppercase\expandafter{\romannumeral2}, we anticipate that this work will bring novel and diverse insights to researchers and abecedarians, and serve as a bridge between past and future.
* 18 pages, 4 figures, 3 tables
Milestones in Autonomous Driving and Intelligent Vehicles: Survey of Surveys
Mar 30, 2023



Interest in autonomous driving (AD) and intelligent vehicles (IVs) is growing at a rapid pace due to the convenience, safety, and economic benefits. Although a number of surveys have reviewed research achievements in this field, they are still limited in specific tasks, lack of systematic summary and research directions in the future. Here we propose a Survey of Surveys (SoS) for total technologies of AD and IVs that reviews the history, summarizes the milestones, and provides the perspectives, ethics, and future research directions. To our knowledge, this article is the first SoS with milestones in AD and IVs, which constitutes our complete research work together with two other technical surveys. We anticipate that this article will bring novel and diverse insights to researchers and abecedarians, and serve as a bridge between past and future.
* 13 pages, 3 tables, 0 figure