 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparScene: Efficient Traffic Scene Representation via Sparse Graph Learning for Large-Scale Trajectory Generation
Dec 24, 2025Multi-agent trajectory generation is a core problem for autonomous driving and intelligent transportation systems. However, efficiently modeling the dynamic interactions between numerous road users and infrastructures in complex scenes remains an open problem. Existing methods typically employ distance-based or fully connected dense graph structures to capture interaction information, which not only introduces a large number of redundant edges but also requires complex and heavily parameterized networks for encoding, thereby resulting in low training and inference efficiency, limiting scalability to large and complex traffic scenes. To overcome the limitations of existing methods, we propose SparScene, a sparse graph learning framework designed for efficient and scalable traffic scene representation. Instead of relying on distance thresholds, SparScene leverages the lane graph topology to construct structure-aware sparse connections between agents and lanes, enabling efficient yet informative scene graph representation. SparScene adopts a lightweight graph encoder that efficiently aggregates agent-map and agent-agent interactions, yielding compact scene representations with substantially improved efficiency and scalability. On the motion prediction benchmark of the Waymo Open Motion Dataset (WOMD), SparScene achieves competitive performance with remarkable efficiency. It generates trajectories for more than 200 agents in a scene within 5 ms and scales to more than 5,000 agents and 17,000 lanes with merely 54 ms of inference time with a GPU memory of 2.9 GB, highlighting its superior scalability for large-scale traffic scenes.
Survey of Design Paradigms for Social Robots
Jul 30, 2024The demand for social robots in fields like healthcare, education, and entertainment increases due to their emotional adaptation features. These robots leverage multimodal communication, incorporating speech, facial expressions, and gestures to enhance user engagement and emotional support. The understanding of design paradigms of social robots is obstructed by the complexity of the system and the necessity to tune it to a specific task. This article provides a structured review of social robot design paradigms, categorizing them into cognitive architectures, role design models, linguistic models, communication flow, activity system models, and integrated design models. By breaking down the articles on social robot design and application based on these paradigms, we highlight the strengths and areas for improvement in current approaches. We further propose our original integrated design model that combines the most important aspects of the design of social robots. Our approach shows the importance of integrating operational, communicational, and emotional dimensions to create more adaptive and empathetic interactions between robots and humans.
Hybrid-Prediction Integrated Planning for Autonomous Driving
Feb 04, 2024Autonomous driving systems require the ability to fully understand and predict the surrounding environment to make informed decisions in complex scenarios. Recent advancements in learning-based systems have highlighted the importance of integrating prediction and planning modules. However, this integration has brought forth three major challenges: inherent trade-offs by sole prediction, consistency between prediction patterns, and social coherence in prediction and planning. To address these challenges, we introduce a hybrid-prediction integrated planning (HPP) system, which possesses three novelly designed modules. First, we introduce marginal-conditioned occupancy prediction to align joint occupancy with agent-wise perceptions. Our proposed MS-OccFormer module achieves multi-stage alignment per occupancy forecasting with consistent awareness from agent-wise motion predictions. Second, we propose a game-theoretic motion predictor, GTFormer, to model the interactive future among individual agents with their joint predictive awareness. Third, hybrid prediction patterns are concurrently integrated with Ego Planner and optimized by prediction guidance. HPP achieves state-of-the-art performance on the nuScenes dataset, demonstrating superior accuracy and consistency for end-to-end paradigms in prediction and planning. Moreover, we test the long-term open-loop and closed-loop performance of HPP on the Waymo Open Motion Dataset and CARLA benchmark, surpassing other integrated prediction and planning pipelines with enhanced accuracy and compatibility.
A Generalized Multi-Modal Fusion Detection Framework
Mar 13, 2023LiDAR point clouds have become the most common data source in autonomous driving. However, due to the sparsity of point clouds, accurate and reliable detection cannot be achieved in specific scenarios. Because of their complementarity with point clouds, images are getting increasing attention. Although with some success, existing fusion methods either perform hard fusion or do not fuse in a direct manner. In this paper, we propose a generic 3D detection framework called MMFusion, using multi-modal features. The framework aims to achieve accurate fusion between LiDAR and images to improve 3D detection in complex scenes. Our framework consists of two separate streams: the LiDAR stream and the camera stream, which can be compatible with any single-modal feature extraction network. The Voxel Local Perception Module in the LiDAR stream enhances local feature representation, and then the Multi-modal Feature Fusion Module selectively combines feature output from different streams to achieve better fusion. Extensive experiments have shown that our framework not only outperforms existing benchmarks but also improves their detection, especially for detecting cyclists and pedestrians on KITTI benchmarks, with strong robustness and generalization capabilities. Hopefully, our work will stimulate more research into multi-modal fusion for autonomous driving tasks.
Augmenting Reinforcement Learning with Transformer-based Scene Representation Learning for Decision-making of Autonomous Driving
Aug 24, 2022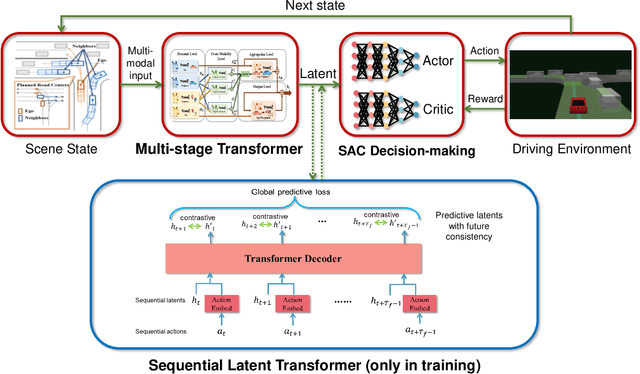
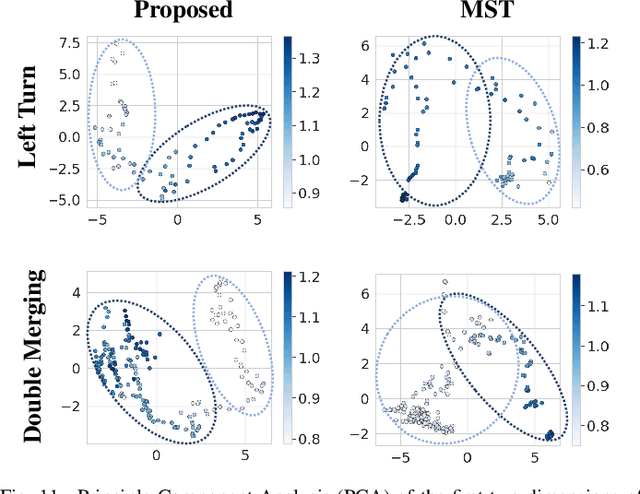
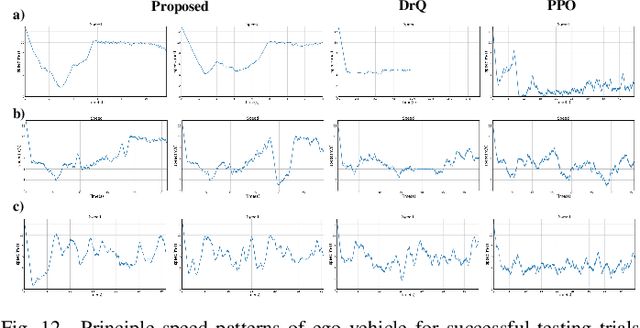
Decision-making for urban autonomous driving is challenging due to the stochastic nature of interactive traffic participants and the complexity of road structures. Although reinforcement learning (RL)-based decision-making scheme is promising to handle urban driving scenarios, it suffers from low sample efficiency and poor adaptability. In this paper, we propose Scene-Rep Transformer to improve the RL decision-making capabilities with better scene representation encoding and sequential predictive latent distillation. Specifically, a multi-stage Transformer (MST) encoder is constructed to model not only the interaction awareness between the ego vehicle and its neighbors but also intention awareness between the agents and their candidate routes. A sequential latent Transformer (SLT) with self-supervised learning objectives is employed to distill the future predictive information into the latent scene representation, in order to reduce the exploration space and speed up training. The final decision-making module based on soft actor-critic (SAC) takes as input the refined latent scene representation from the Scene-Rep Transformer and outputs driving actions. The framework is validated in five challenging simulated urban scenarios with dense traffic, and its performance is manifested quantitatively by the substantial improvements in data efficiency and performance in terms of success rate, safety, and efficiency. The qualitative results reveal that our framework is able to extract the intentions of neighbor agents to help make decisions and deliver more diversified driving behaviors.
ReCoAt: A Deep Learning-based Framework for Multi-Modal Motion Prediction in Autonomous Driving Application
Jul 02, 2022
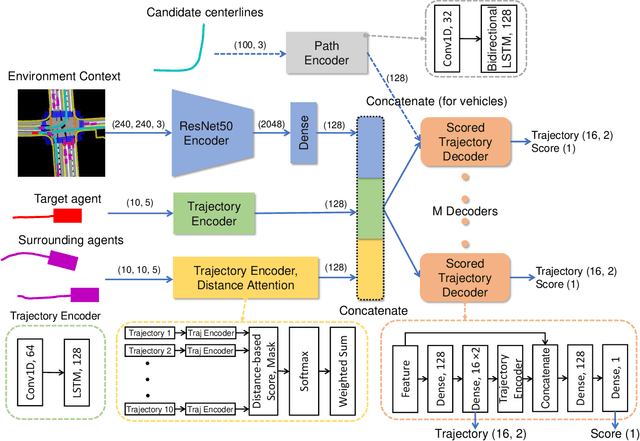
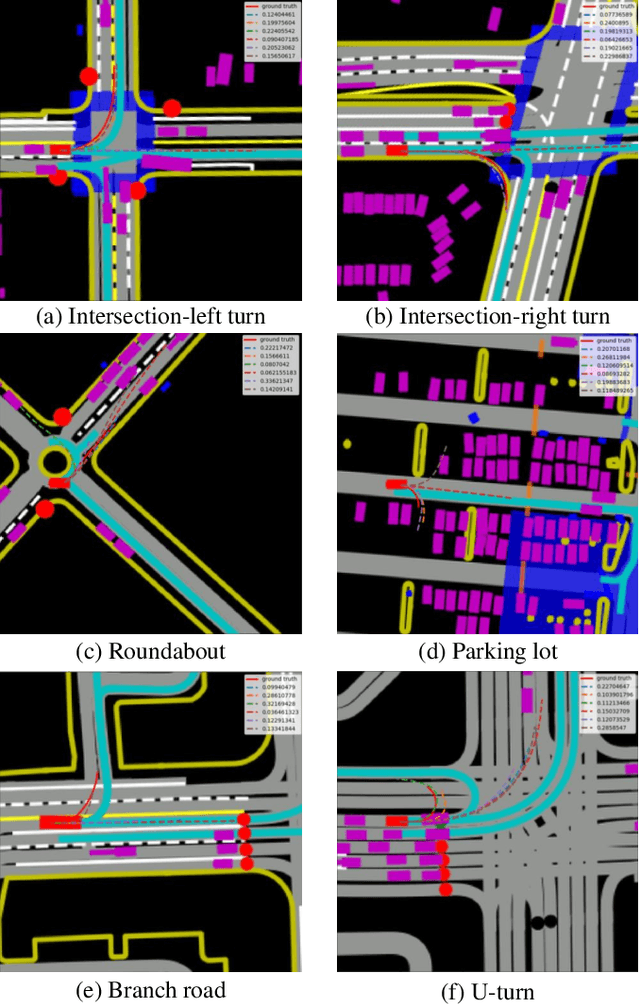
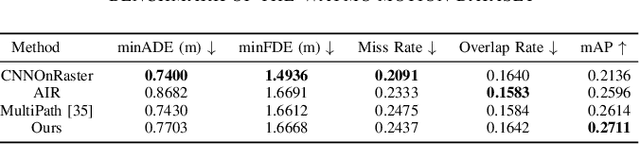
This paper proposes a novel deep learning framework for multi-modal motion prediction. The framework consists of three parts: recurrent neural networks to process the target agent's motion process, convolutional neural networks to process the rasterized environment representation, and a distance-based attention mechanism to process the interactions among different agents. We validate the proposed framework on a large-scale real-world driving dataset, Waymo open motion dataset, and compare its performance against other methods on the standard testing benchmark. The qualitative results manifest that the predicted trajectories given by our model are accurate, diverse, and in accordance with the road structure. The quantitative results on the standard benchmark reveal that our model outperforms other baseline methods in terms of prediction accuracy and other evaluation metrics. The proposed framework is the second-place winner of the 2021 Waymo open dataset motion prediction challenge.
Multi-modal Motion Prediction with Transformer-based Neural Network for Autonomous Driving
Sep 14, 2021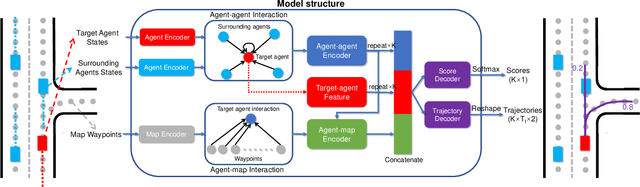
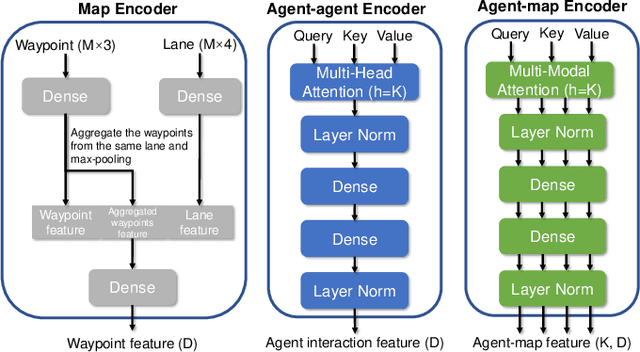
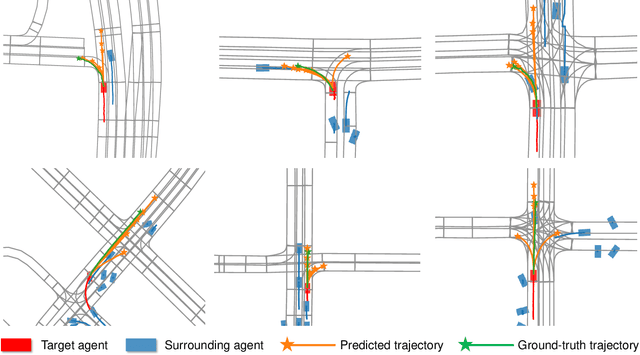
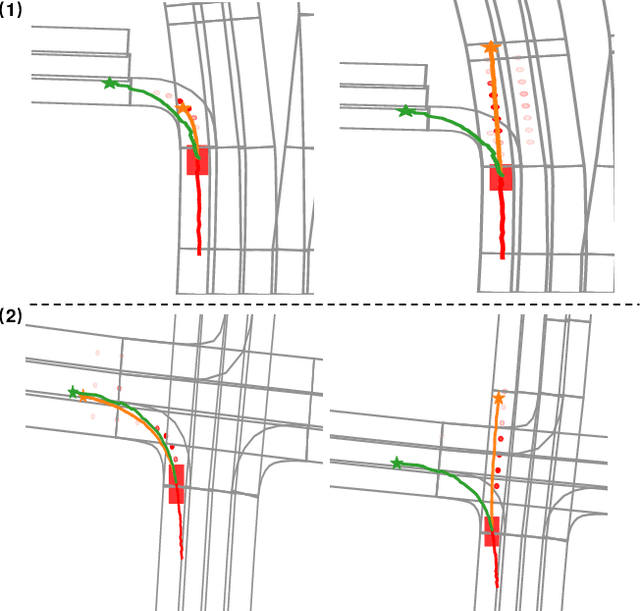
Predicting the behaviors of other agents on the road is critical for autonomous driving to ensure safety and efficiency. However, the challenging part is how to represent the social interactions between agents and output different possible trajectories with interpretability. In this paper, we introduce a neural prediction framework based on the Transformer structure to model the relationship among the interacting agents and extract the attention of the target agent on the map waypoints. Specifically, we organize the interacting agents into a graph and utilize the multi-head attention Transformer encoder to extract the relations between them. To address the multi-modality of motion prediction, we propose a multi-modal attention Transformer encoder, which modifies the multi-head attention mechanism to multi-modal attention, and each predicted trajectory is conditioned on an independent attention mode. The proposed model is validated on the Argoverse motion forecasting dataset and shows state-of-the-art prediction accuracy while maintaining a small model size and a simple training process. We also demonstrate that the multi-modal attention module can automatically identify different modes of the target agent's attention on the map, which improves the interpretability of the model.
Graph and Recurrent Neural Network-based Vehicle Trajectory Prediction For Highway Driving
Jul 08, 2021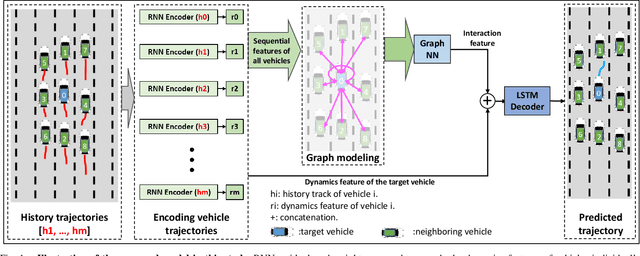
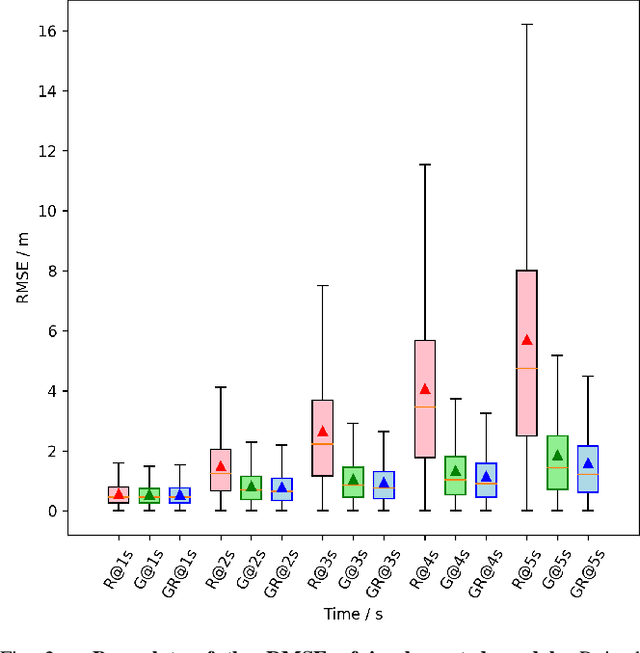
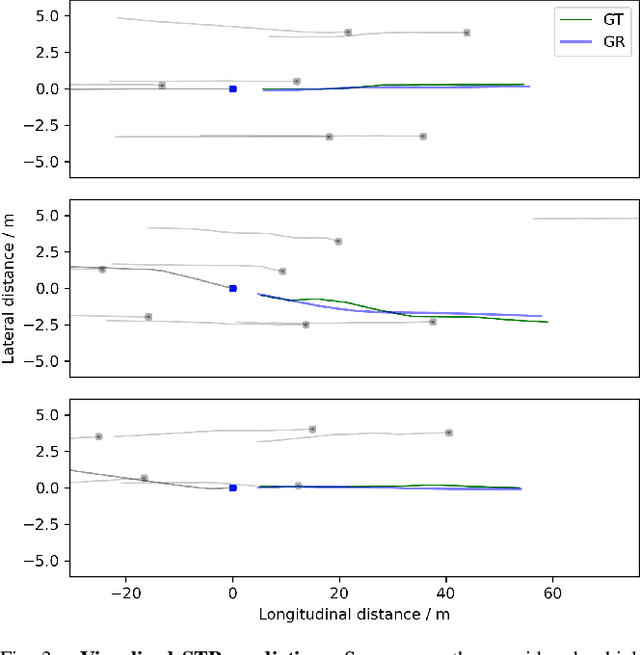
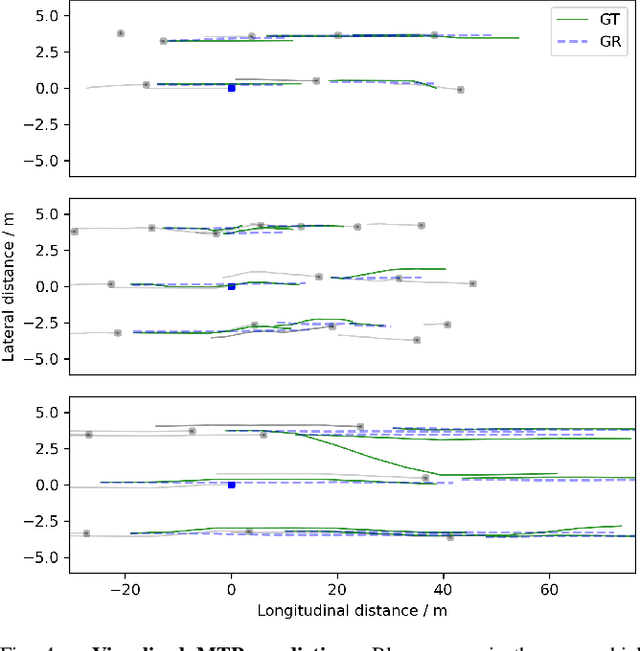
Integrating trajectory prediction to the decision-making and planning modules of modular autonomous driving systems is expected to improve the safety and efficiency of self-driving vehicles. However, a vehicle's future trajectory prediction is a challenging task since it is affected by the social interactive behaviors of neighboring vehicles, and the number of neighboring vehicles can vary in different situations. This work proposes a GNN-RNN based Encoder-Decoder network for interaction-aware trajectory prediction, where vehicles' dynamics features are extracted from their historical tracks using RNN, and the inter-vehicular interaction is represented by a directed graph and encoded using a GNN. The parallelism of GNN implies the proposed method's potential to predict multi-vehicular trajectories simultaneously. Evaluation on the dataset extracted from the NGSIM US-101 dataset shows that the proposed model is able to predict a target vehicle's trajectory in situations with a variable number of surrounding vehicles.
Heterogeneous Edge-Enhanced Graph Attention Network For Multi-Agent Trajectory Prediction
Jun 14, 2021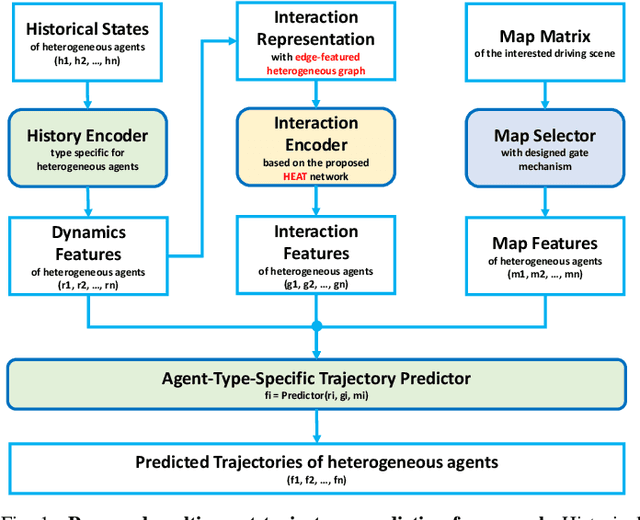
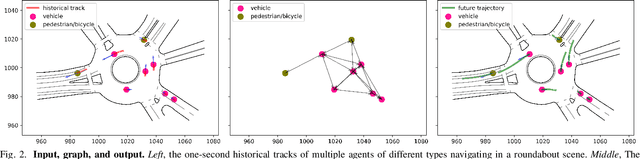
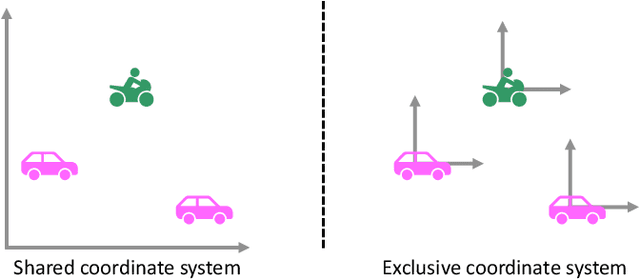
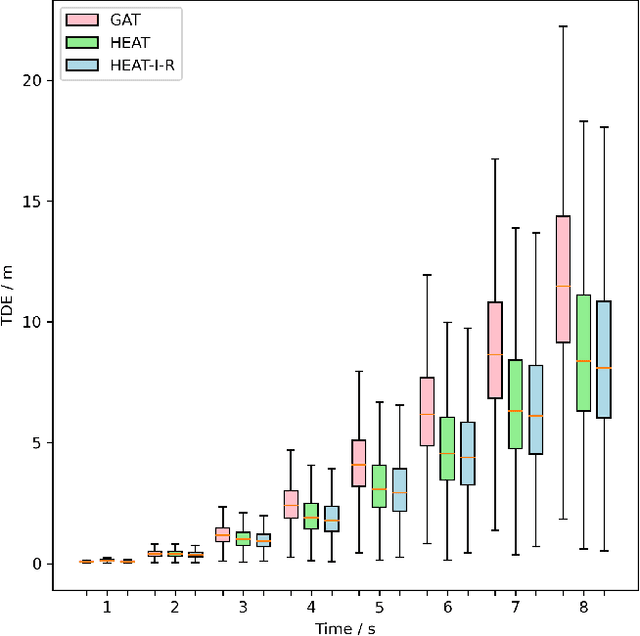
Simultaneous trajectory prediction for multiple heterogeneous traffic participants is essential for the safe and efficient operation of connected automated vehicles under complex driving situations in the real world. The multi-agent prediction task is challenging, as the motions of traffic participants are affected by many factors, including their individual dynamics, their interactions with surrounding agents, the traffic infrastructures, and the number and modalities of the target agents. To further advance the trajectory prediction techniques, in this work we propose a three-channel framework together with a novel Heterogeneous Edge-enhanced graph ATtention network (HEAT), which is able to deal with the heterogeneity of the target agents and traffic participants involved. Specifically, the agent's dynamics are extracted from their historical states using type-specific encoders. The inter-agent interactions are represented with a directed edge-featured heterogeneous graph, and then interaction features are extracted using the proposed HEAT network. Besides, the map features are shared across all agents by introducing a selective gate mechanism. And finally, the trajectories of multi-agent are executed simultaneously. Validations using both urban and highway driving datasets show that the proposed model can realize simultaneous trajectory predictions for multiple agents under complex traffic situations, and achieve state-of-the-art performance with respect to prediction accuracy, demonstrating its feasibility and effectiveness.
ReCoG: A Deep Learning Framework with Heterogeneous Graph for Interaction-Aware Trajectory Prediction
Dec 09, 2020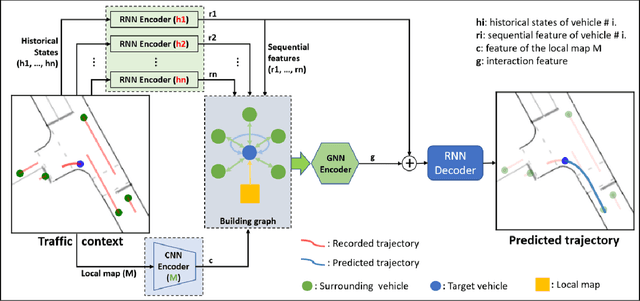
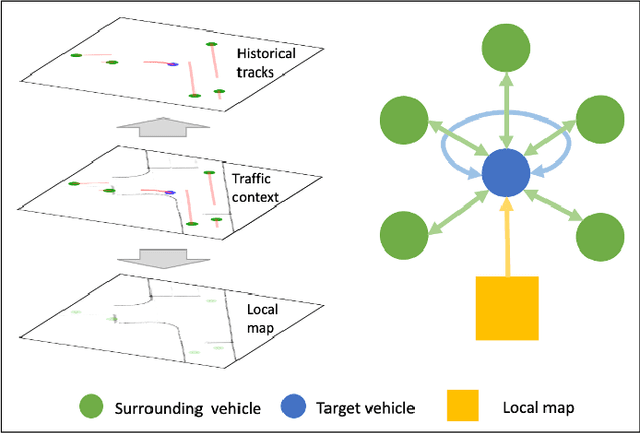
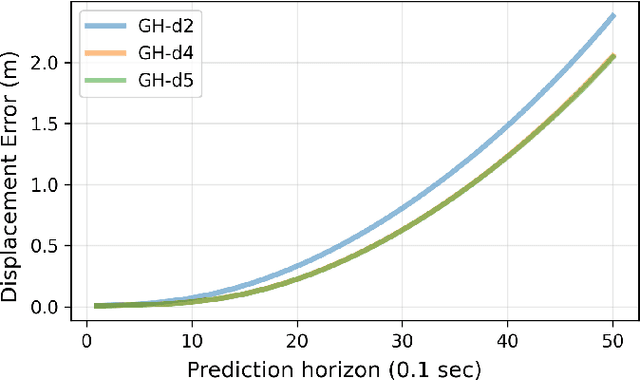
Predicting the future trajectory of surrounding vehicles is essential for the navigation of autonomous vehicles in complex real-world driving scenarios. It is challenging as a vehicle's motion is affected by many factors, including its surrounding infrastructures and vehicles. In this work, we develop the ReCoG (Recurrent Convolutional and Graph Neural Networks), which is a general scheme that represents vehicle interactions with infrastructure information as a heterogeneous graph and applies graph neural networks (GNNs) to model the high-level interactions for trajectory prediction. Nodes in the graph contain corresponding features, where a vehicle node contains its sequential feature encoded using Recurrent Neural Network (RNN), and an infrastructure node contains spatial feature encoded using Convolutional Neural Network (CNN). Then the ReCoG predicts the future trajectory of the target vehicle by jointly considering all of the features. Experiments are conducted by using the INTERACTION dataset. Experimental results show that the proposed ReCoG outperforms other state-of-the-art methods in terms of different types of displacement error, validating the feasibility and effectiveness of the developed approach.