 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMoT: A Unified Vision-Language-Action Model with Asynchronous Mixture-of-Transformers for End-to-End Autonomous Driving
Mar 16, 2026Integrating vision-language models (VLMs) into end-to-end (E2E) autonomous driving (AD) systems has shown promise in improving scene understanding. However, existing integration strategies suffer from several limitations: they either struggle to resolve distribution misalignment between reasoning and action spaces, underexploit the general reasoning capabilities of pretrained VLMs, or incur substantial inference latency during action policy generation, which degrades driving performance. To address these challenges, we propose \OURS in this work, an end-to-end AD framework that unifies reasoning and action generation within a single vision-language-action (VLA) model. Our approach leverages a mixture-of-transformer (MoT) architecture with joint attention sharing, which preserves the general reasoning capabilities of pre-trained VLMs while enabling efficient fast-slow inference through asynchronous execution at different task frequencies. Extensive experiments on multiple benchmarks, under both open- and closed-loop settings, demonstrate that \OURS achieves competitive performance compared to state-of-the-art methods. We further investigate the functional boundary of pre-trained VLMs in AD, examining when AD-tailored fine-tuning is necessary. Our results show that pre-trained VLMs can achieve competitive multi-task scene understanding performance through semantic prompting alone, while fine-tuning remains essential for action-level tasks such as decision-making and trajectory planning. We refer to \href{https://automot-website.github.io/}{Project Page} for the demonstration videos and qualitative results.
WiseAD: Knowledge Augmented End-to-End Autonomous Driving with Vision-Language Model
Dec 13, 2024



The emergence of general human knowledge and impressive logical reasoning capacity in rapidly progressed vision-language models (VLMs) have driven increasing interest in applying VLMs to high-level autonomous driving tasks, such as scene understanding and decision-making. However, an in-depth study on the relationship between knowledge proficiency, especially essential driving expertise, and closed-loop autonomous driving performance requires further exploration. In this paper, we investigate the effects of the depth and breadth of fundamental driving knowledge on closed-loop trajectory planning and introduce WiseAD, a specialized VLM tailored for end-to-end autonomous driving capable of driving reasoning, action justification, object recognition, risk analysis, driving suggestions, and trajectory planning across diverse scenarios. We employ joint training on driving knowledge and planning datasets, enabling the model to perform knowledge-aligned trajectory planning accordingly. Extensive experiments indicate that as the diversity of driving knowledge extends, critical accidents are notably reduced, contributing 11.9% and 12.4% improvements in the driving score and route completion on the Carla closed-loop evaluations, achieving state-of-the-art performance. Moreover, WiseAD also demonstrates remarkable performance in knowledge evaluations on both in-domain and out-of-domain datasets.
Hybrid-Prediction Integrated Planning for Autonomous Driving
Feb 04, 2024


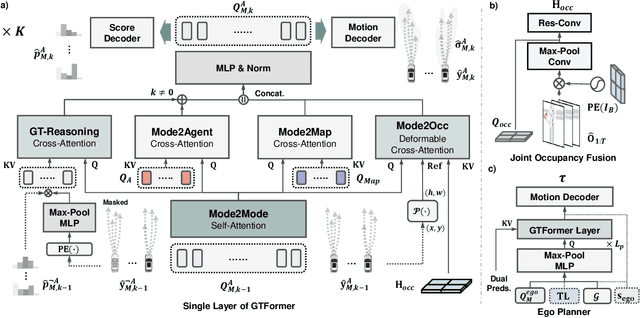
Autonomous driving systems require the ability to fully understand and predict the surrounding environment to make informed decisions in complex scenarios. Recent advancements in learning-based systems have highlighted the importance of integrating prediction and planning modules. However, this integration has brought forth three major challenges: inherent trade-offs by sole prediction, consistency between prediction patterns, and social coherence in prediction and planning. To address these challenges, we introduce a hybrid-prediction integrated planning (HPP) system, which possesses three novelly designed modules. First, we introduce marginal-conditioned occupancy prediction to align joint occupancy with agent-wise perceptions. Our proposed MS-OccFormer module achieves multi-stage alignment per occupancy forecasting with consistent awareness from agent-wise motion predictions. Second, we propose a game-theoretic motion predictor, GTFormer, to model the interactive future among individual agents with their joint predictive awareness. Third, hybrid prediction patterns are concurrently integrated with Ego Planner and optimized by prediction guidance. HPP achieves state-of-the-art performance on the nuScenes dataset, demonstrating superior accuracy and consistency for end-to-end paradigms in prediction and planning. Moreover, we test the long-term open-loop and closed-loop performance of HPP on the Waymo Open Motion Dataset and CARLA benchmark, surpassing other integrated prediction and planning pipelines with enhanced accuracy and compatibility.
Depth Map Denoising Network and Lightweight Fusion Network for Enhanced 3D Face Recognition
Jan 01, 2024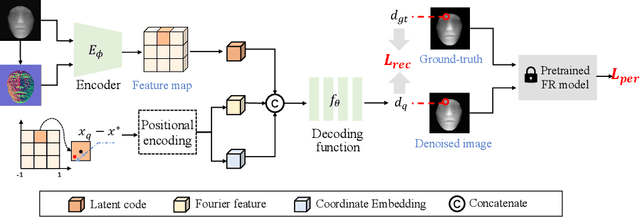
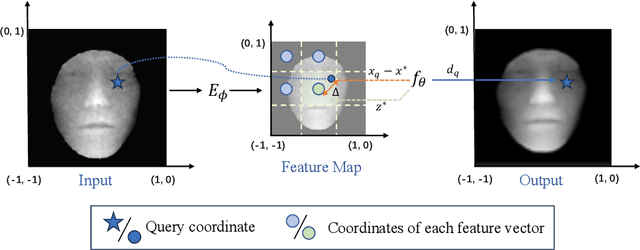
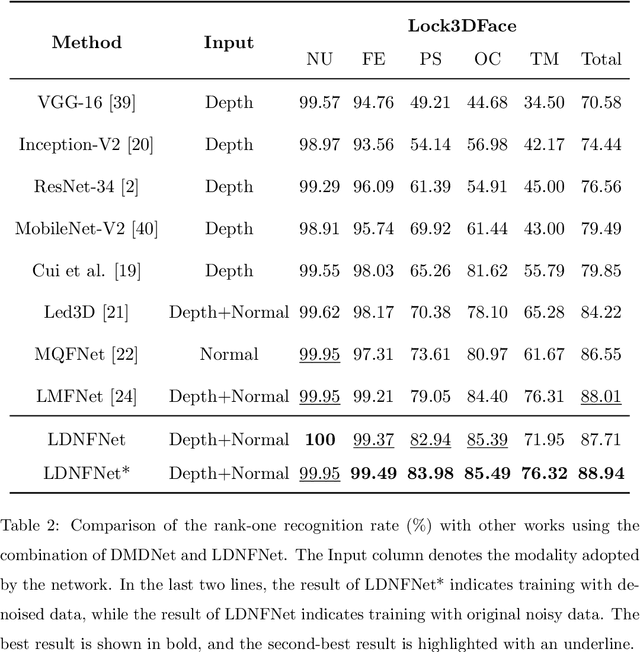
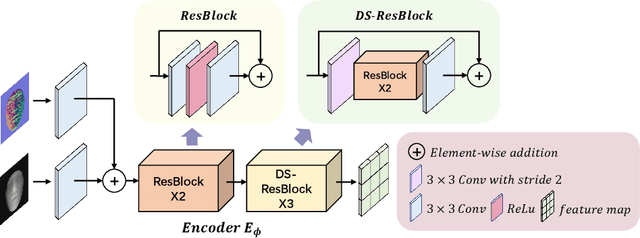
With the increasing availability of consumer depth sensors, 3D face recognition (FR) has attracted more and more attention. However, the data acquired by these sensors are often coarse and noisy, making them impractical to use directly. In this paper, we introduce an innovative Depth map denoising network (DMDNet) based on the Denoising Implicit Image Function (DIIF) to reduce noise and enhance the quality of facial depth images for low-quality 3D FR. After generating clean depth faces using DMDNet, we further design a powerful recognition network called Lightweight Depth and Normal Fusion network (LDNFNet), which incorporates a multi-branch fusion block to learn unique and complementary features between different modalities such as depth and normal images. Comprehensive experiments conducted on four distinct low-quality databases demonstrate the effectiveness and robustness of our proposed methods. Furthermore, when combining DMDNet and LDNFNet, we achieve state-of-the-art results on the Lock3DFace database.
Learning Interaction-aware Motion Prediction Model for Decision-making in Autonomous Driving
Feb 08, 2023



Predicting the behaviors of other road users is crucial to safe and intelligent decision-making for autonomous vehicles (AVs). However, most motion prediction models ignore the influence of the AV's actions and the planning module has to treat other agents as unalterable moving obstacles. To address this problem, this paper proposes an interaction-aware motion prediction model that is able to predict other agents' future trajectories according to the ego agent's future plan, i.e., their reactions to the ego's actions. Specifically, we employ Transformers to effectively encode the driving scene and incorporate the AV's plan in decoding the predicted trajectories. To train the model to accurately predict the reactions of other agents, we develop an online learning framework, where the ego agent explores the environment and collects other agents' reactions to itself. We validate the decision-making and learning framework in three highly interactive simulated driving scenarios. The results reveal that our decision-making method significantly outperforms the reinforcement learning methods in terms of data efficiency and performance. We also find that using the interaction-aware model can bring better performance than the non-interaction-aware model and the exploration process helps improve the success rate in testing.
Goal-guided Transformer-enabled Reinforcement Learning for Efficient Autonomous Navigation
Jan 01, 2023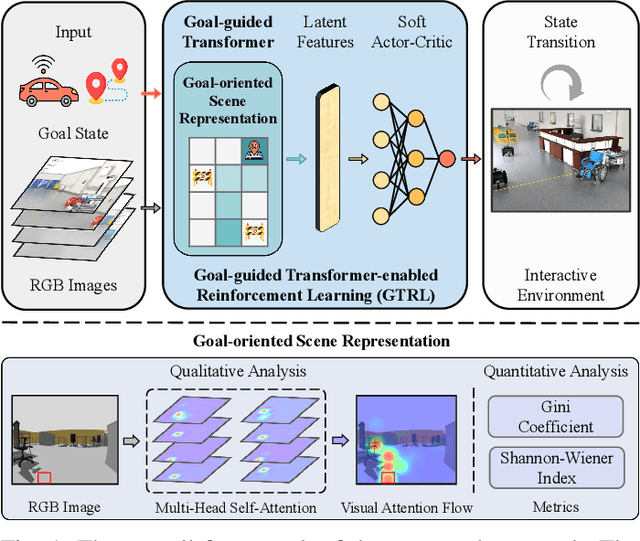

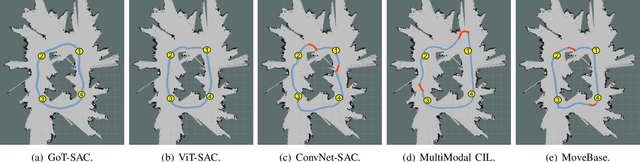
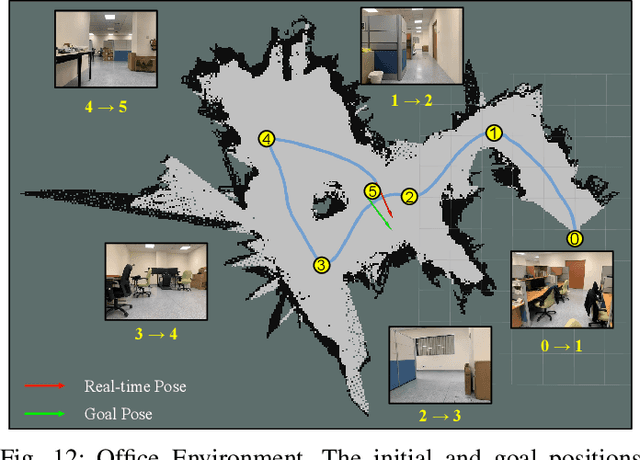
Despite some successful applications of goal-driven navigation, existing deep reinforcement learning-based approaches notoriously suffers from poor data efficiency issue. One of the reasons is that the goal information is decoupled from the perception module and directly introduced as a condition of decision-making, resulting in the goal-irrelevant features of the scene representation playing an adversary role during the learning process. In light of this, we present a novel Goal-guided Transformer-enabled reinforcement learning (GTRL) approach by considering the physical goal states as an input of the scene encoder for guiding the scene representation to couple with the goal information and realizing efficient autonomous navigation. More specifically, we propose a novel variant of the Vision Transformer as the backbone of the perception system, namely Goal-guided Transformer (GoT), and pre-train it with expert priors to boost the data efficiency. Subsequently, a reinforcement learning algorithm is instantiated for the decision-making system, taking the goal-oriented scene representation from the GoT as the input and generating decision commands. As a result, our approach motivates the scene representation to concentrate mainly on goal-relevant features, which substantially enhances the data efficiency of the DRL learning process, leading to superior navigation performance. Both simulation and real-world experimental results manifest the superiority of our approach in terms of data efficiency, performance, robustness, and sim-to-real generalization, compared with other state-of-art baselines. Demonstration videos are available at \colorb{https://youtu.be/93LGlGvaN0c.
Learning to Weight Samples for Dynamic Early-exiting Networks
Sep 17, 2022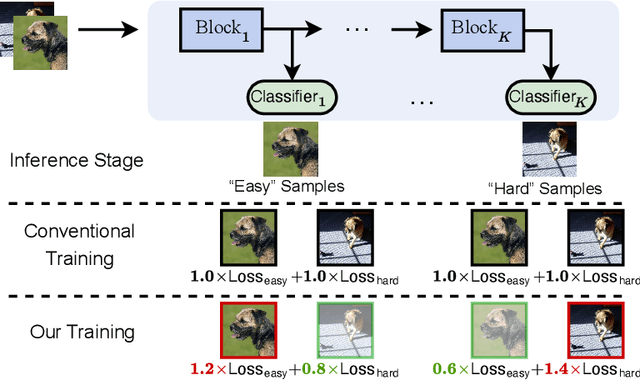
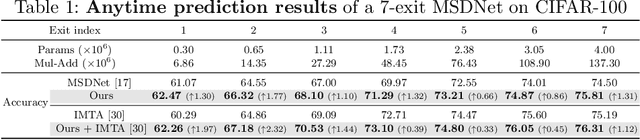

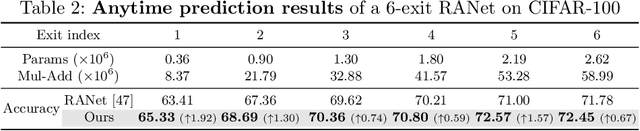
Early exiting is an effective paradigm for improving the inference efficiency of deep networks. By constructing classifiers with varying resource demands (the exits), such networks allow easy samples to be output at early exits, removing the need for executing deeper layers. While existing works mainly focus on the architectural design of multi-exit networks, the training strategies for such models are largely left unexplored. The current state-of-the-art models treat all samples the same during training. However, the early-exiting behavior during testing has been ignored, leading to a gap between training and testing. In this paper, we propose to bridge this gap by sample weighting. Intuitively, easy samples, which generally exit early in the network during inference, should contribute more to training early classifiers. The training of hard samples (mostly exit from deeper layers), however, should be emphasized by the late classifiers. Our work proposes to adopt a weight prediction network to weight the loss of different training samples at each exit. This weight prediction network and the backbone model are jointly optimized under a meta-learning framework with a novel optimization objective. By bringing the adaptive behavior during inference into the training phase, we show that the proposed weighting mechanism consistently improves the trade-off between classification accuracy and inference efficiency. Code is available at https://github.com/LeapLabTHU/L2W-DEN.
Safe Decision-making for Lane-change of Autonomous Vehicles via Human Demonstration-aided Reinforcement Learning
Jul 07, 2022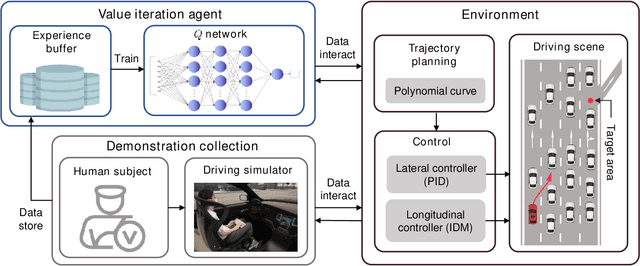

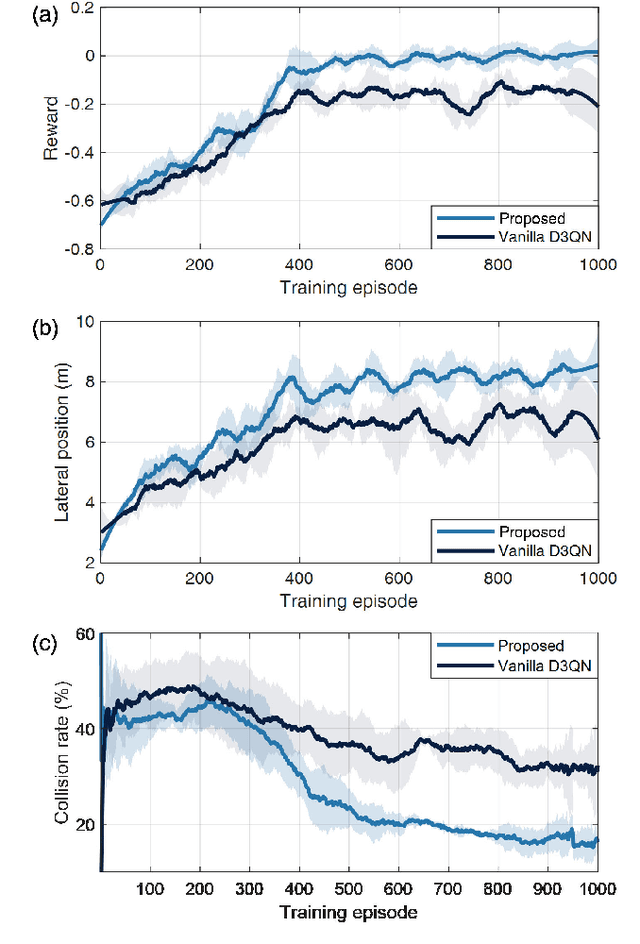
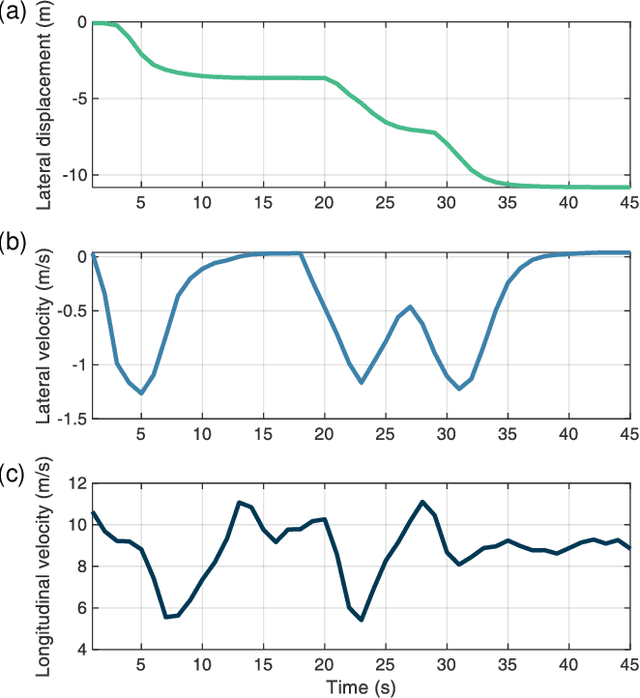
Decision-making is critical for lane change in autonomous driving. Reinforcement learning (RL) algorithms aim to identify the values of behaviors in various situations and thus they become a promising pathway to address the decision-making problem. However, poor runtime safety hinders RL-based decision-making strategies from complex driving tasks in practice. To address this problem, human demonstrations are incorporated into the RL-based decision-making strategy in this paper. Decisions made by human subjects in a driving simulator are treated as safe demonstrations, which are stored into the replay buffer and then utilized to enhance the training process of RL. A complex lane change task in an off-ramp scenario is established to examine the performance of the developed strategy. Simulation results suggest that human demonstrations can effectively improve the safety of decisions of RL. And the proposed strategy surpasses other existing learning-based decision-making strategies with respect to multiple driving performances.
Sampling Efficient Deep Reinforcement Learning through Preference-Guided Stochastic Exploration
Jun 20, 2022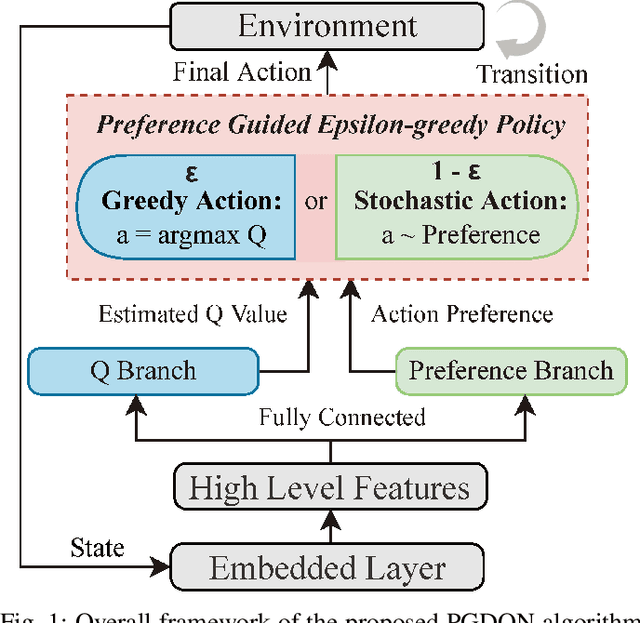
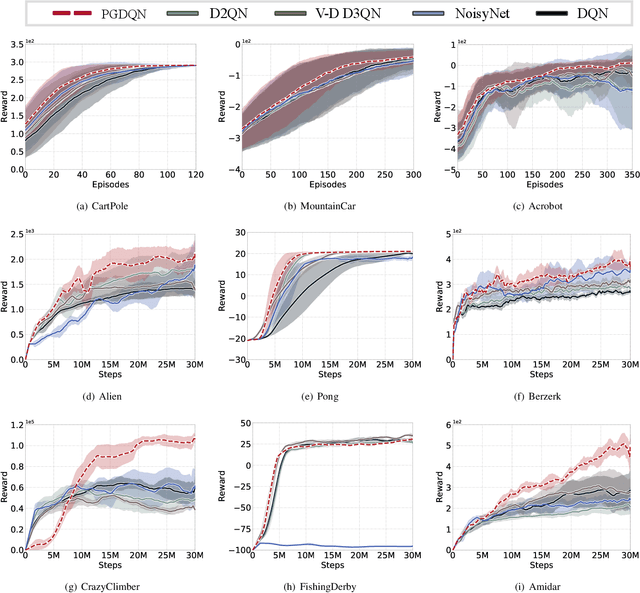
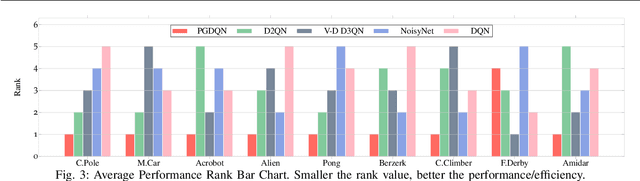
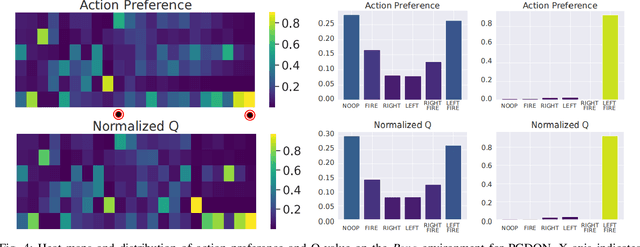
Massive practical works addressed by Deep Q-network (DQN) algorithm have indicated that stochastic policy, despite its simplicity, is the most frequently used exploration approach. However, most existing stochastic exploration approaches either explore new actions heuristically regardless of Q-values or inevitably introduce bias into the learning process to couple the sampling with Q-values. In this paper, we propose a novel preference-guided $\epsilon$-greedy exploration algorithm that can efficiently learn the action distribution in line with the landscape of Q-values for DQN without introducing additional bias. Specifically, we design a dual architecture consisting of two branches, one of which is a copy of DQN, namely the Q-branch. The other branch, which we call the preference branch, learns the action preference that the DQN implicit follows. We theoretically prove that the policy improvement theorem holds for the preference-guided $\epsilon$-greedy policy and experimentally show that the inferred action preference distribution aligns with the landscape of corresponding Q-values. Consequently, preference-guided $\epsilon$-greedy exploration motivates the DQN agent to take diverse actions, i.e., actions with larger Q-values can be sampled more frequently whereas actions with smaller Q-values still have a chance to be explored, thus encouraging the exploration. We assess the proposed method with four well-known DQN variants in nine different environments. Extensive results confirm the superiority of our proposed method in terms of performance and convergence speed. Index Terms- Preference-guided exploration, stochastic policy, data efficiency, deep reinforcement learning, deep Q-learning.
Glance and Focus Networks for Dynamic Visual Recognition
Jan 09, 2022
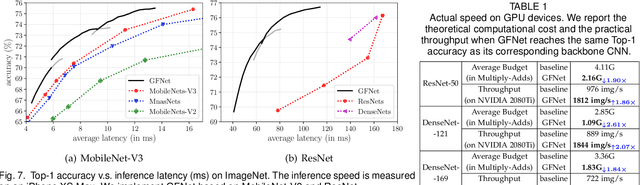
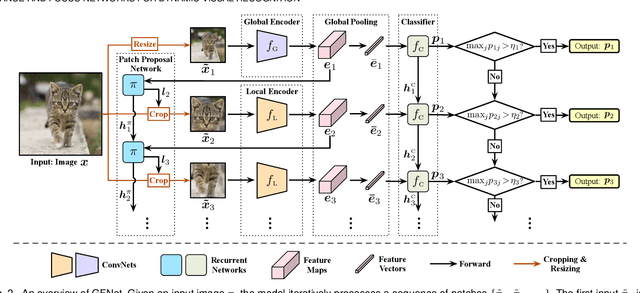

Spatial redundancy widely exists in visual recognition tasks, i.e., discriminative features in an image or video frame usually correspond to only a subset of pixels, while the remaining regions are irrelevant to the task at hand. Therefore, static models which process all the pixels with an equal amount of computation result in considerable redundancy in terms of time and space consumption. In this paper, we formulate the image recognition problem as a sequential coarse-to-fine feature learning process, mimicking the human visual system. Specifically, the proposed Glance and Focus Network (GFNet) first extracts a quick global representation of the input image at a low resolution scale, and then strategically attends to a series of salient (small) regions to learn finer features. The sequential process naturally facilitates adaptive inference at test time, as it can be terminated once the model is sufficiently confident about its prediction, avoiding further redundant computation. It is worth noting that the problem of locating discriminant regions in our model is formulated as a reinforcement learning task, thus requiring no additional manual annotations other than classification labels. GFNet is general and flexible as it is compatible with any off-the-shelf backbone models (such as MobileNets, EfficientNets and TSM), which can be conveniently deployed as the feature extractor. Extensive experiments on a variety of image classification and video recognition tasks and with various backbone models demonstrate the remarkable efficiency of our method. For example, it reduces the average latency of the highly efficient MobileNet-V3 on an iPhone XS Max by 1.3x without sacrificing accuracy. Code and pre-trained models are available at https://github.com/blackfeather-wang/GFNet-Pytorch.