 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Interaction-Aware Cooperative Control Strategy for Alleviating Mixed Traffic Congestion
Mar 04, 2026As Intelligent Transportation System (ITS) develops, Connected and Automated Vehicles (CAVs) are expected to significantly reduce traffic congestion through cooperative strategies, such as in bottleneck areas. However, the uncertainty and diversity in the behaviors of Human-Driven Vehicles (HDVs) in mixed traffic environments present major challenges for CAV cooperation. This paper proposes a Dual-Interaction-Aware Cooperative Control (DIACC) strategy that enhances both local and global interaction perception within the Multi-Agent Reinforcement Learning (MARL) framework for Connected and Automated Vehicles (CAVs) in mixed traffic bottleneck scenarios. The DIACC strategy consists of three key innovations: 1) A Decentralized Interaction-Adaptive Decision-Making (D-IADM) module that enhances actor's local interaction perception by distinguishing CAV-CAV cooperative interactions from CAV-HDV observational interactions. 2) A Centralized Interaction-Enhanced Critic (C-IEC) that improves critic's global traffic understanding through interaction-aware value estimation, providing more accurate guidance for policy updates. 3) A reward design that employs softmin aggregation with temperature annealing to prioritize interaction-intensive scenarios in mixed traffic. Additionally, a lightweight Proactive Safety-based Action Refinement (PSAR) module applies rule-based corrections to accelerate training convergence. Experimental results demonstrate that DIACC significantly improves traffic efficiency and adaptability compared to rule-based and benchmark MARL models.
CL-CoTNav: Closed-Loop Hierarchical Chain-of-Thought for Zero-Shot Object-Goal Navigation with Vision-Language Models
Apr 11, 2025Visual Object Goal Navigation (ObjectNav) requires a robot to locate a target object in an unseen environment using egocentric observations. However, decision-making policies often struggle to transfer to unseen environments and novel target objects, which is the core generalization problem. Traditional end-to-end learning methods exacerbate this issue, as they rely on memorizing spatial patterns rather than employing structured reasoning, limiting their ability to generalize effectively. In this letter, we introduce Closed-Loop Hierarchical Chain-of-Thought Navigation (CL-CoTNav), a vision-language model (VLM)-driven ObjectNav framework that integrates structured reasoning and closed-loop feedback into navigation decision-making. To enhance generalization, we fine-tune a VLM using multi-turn question-answering (QA) data derived from human demonstration trajectories. This structured dataset enables hierarchical Chain-of-Thought (H-CoT) prompting, systematically extracting compositional knowledge to refine perception and decision-making, inspired by the human cognitive process of locating a target object through iterative reasoning steps. Additionally, we propose a Closed-Loop H-CoT mechanism that incorporates detection and reasoning confidence scores into training. This adaptive weighting strategy guides the model to prioritize high-confidence data pairs, mitigating the impact of noisy inputs and enhancing robustness against hallucinated or incorrect reasoning. Extensive experiments in the AI Habitat environment demonstrate CL-CoTNav's superior generalization to unseen scenes and novel object categories. Our method consistently outperforms state-of-the-art approaches in navigation success rate (SR) and success weighted by path length (SPL) by 22.4\%. We release our datasets, models, and supplementary videos on our project page.
Terahertz channel modeling based on surface sensing characteristics
Apr 03, 2024



The dielectric properties of environmental surfaces, including walls, floors and the ground, etc., play a crucial role in shaping the accuracy of terahertz (THz) channel modeling, thereby directly impacting the effectiveness of communication systems. Traditionally, acquiring these properties has relied on methods such as terahertz time-domain spectroscopy (THz-TDS) or vector network analyzers (VNA), demanding rigorous sample preparation and entailing a significant expenditure of time. However, such measurements are not always feasible, particularly in novel and uncharacterized scenarios. In this work, we propose a new approach for channel modeling that leverages the inherent sensing capabilities of THz channels. By comparing the results obtained through channel sensing with that derived from THz-TDS measurements, we demonstrate the method's ability to yield dependable surface property information. The application of this approach in both a miniaturized cityscape scenario and an indoor environment has shown consistency with experimental measurements, thereby verifying its effectiveness in real-world settings.
Goal-guided Transformer-enabled Reinforcement Learning for Efficient Autonomous Navigation
Jan 01, 2023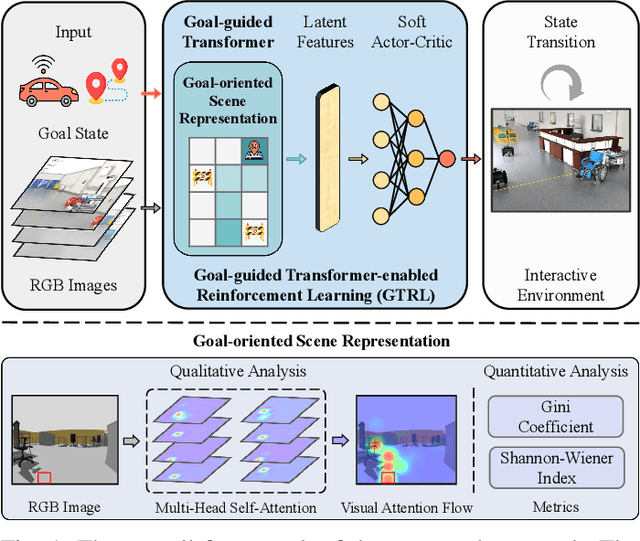

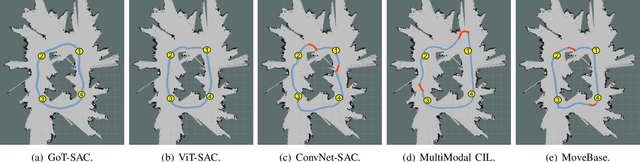
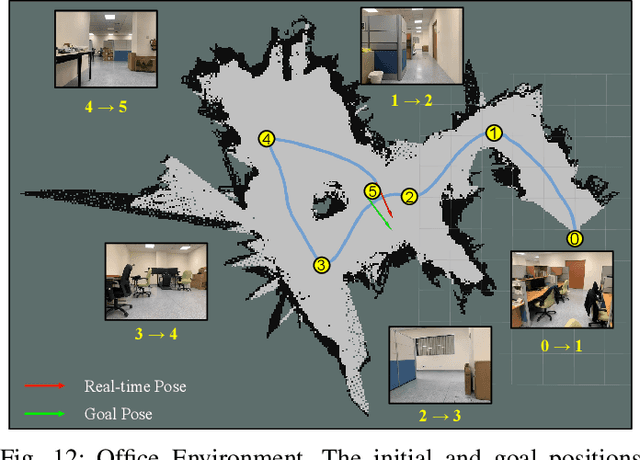
Despite some successful applications of goal-driven navigation, existing deep reinforcement learning-based approaches notoriously suffers from poor data efficiency issue. One of the reasons is that the goal information is decoupled from the perception module and directly introduced as a condition of decision-making, resulting in the goal-irrelevant features of the scene representation playing an adversary role during the learning process. In light of this, we present a novel Goal-guided Transformer-enabled reinforcement learning (GTRL) approach by considering the physical goal states as an input of the scene encoder for guiding the scene representation to couple with the goal information and realizing efficient autonomous navigation. More specifically, we propose a novel variant of the Vision Transformer as the backbone of the perception system, namely Goal-guided Transformer (GoT), and pre-train it with expert priors to boost the data efficiency. Subsequently, a reinforcement learning algorithm is instantiated for the decision-making system, taking the goal-oriented scene representation from the GoT as the input and generating decision commands. As a result, our approach motivates the scene representation to concentrate mainly on goal-relevant features, which substantially enhances the data efficiency of the DRL learning process, leading to superior navigation performance. Both simulation and real-world experimental results manifest the superiority of our approach in terms of data efficiency, performance, robustness, and sim-to-real generalization, compared with other state-of-art baselines. Demonstration videos are available at \colorb{https://youtu.be/93LGlGvaN0c.
Safe Decision-making for Lane-change of Autonomous Vehicles via Human Demonstration-aided Reinforcement Learning
Jul 07, 2022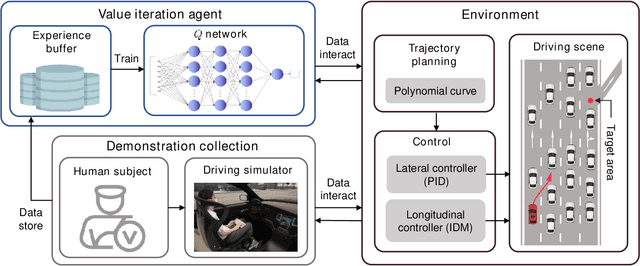

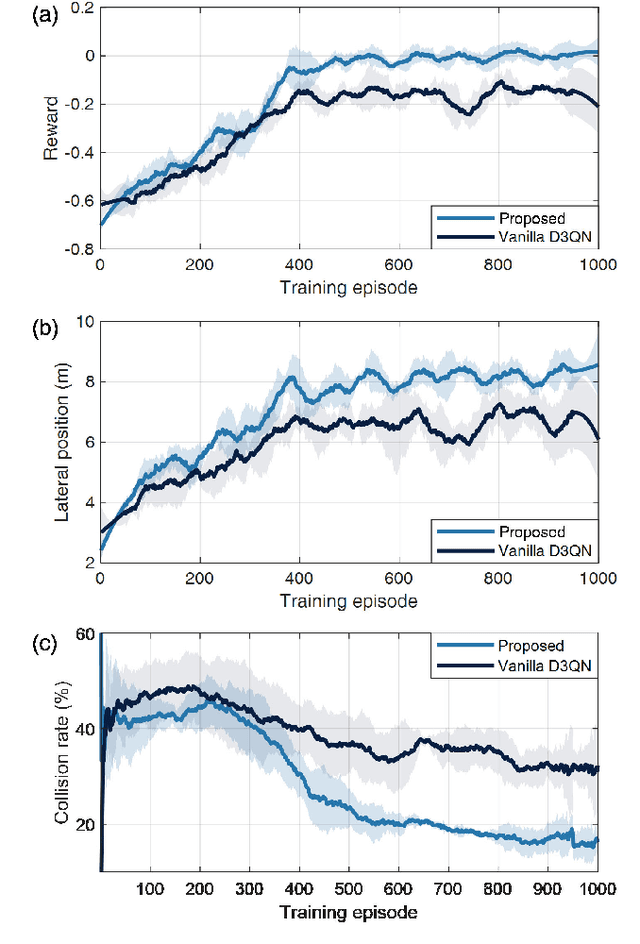
Decision-making is critical for lane change in autonomous driving. Reinforcement learning (RL) algorithms aim to identify the values of behaviors in various situations and thus they become a promising pathway to address the decision-making problem. However, poor runtime safety hinders RL-based decision-making strategies from complex driving tasks in practice. To address this problem, human demonstrations are incorporated into the RL-based decision-making strategy in this paper. Decisions made by human subjects in a driving simulator are treated as safe demonstrations, which are stored into the replay buffer and then utilized to enhance the training process of RL. A complex lane change task in an off-ramp scenario is established to examine the performance of the developed strategy. Simulation results suggest that human demonstrations can effectively improve the safety of decisions of RL. And the proposed strategy surpasses other existing learning-based decision-making strategies with respect to multiple driving performances.
Sampling Efficient Deep Reinforcement Learning through Preference-Guided Stochastic Exploration
Jun 20, 2022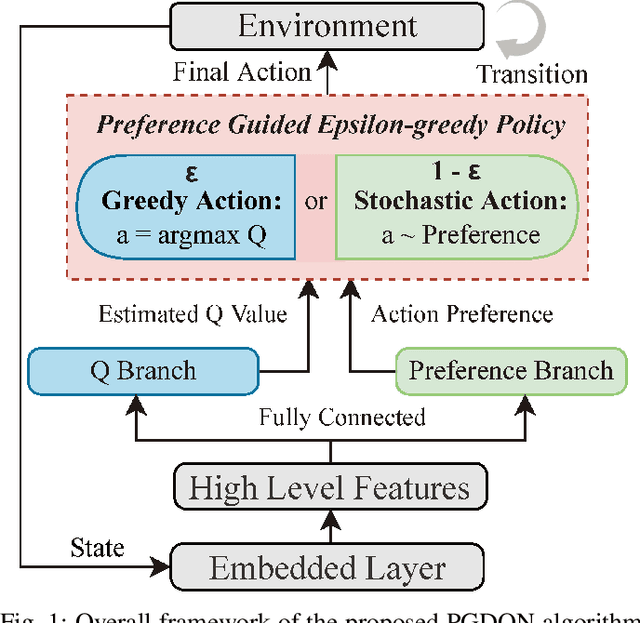
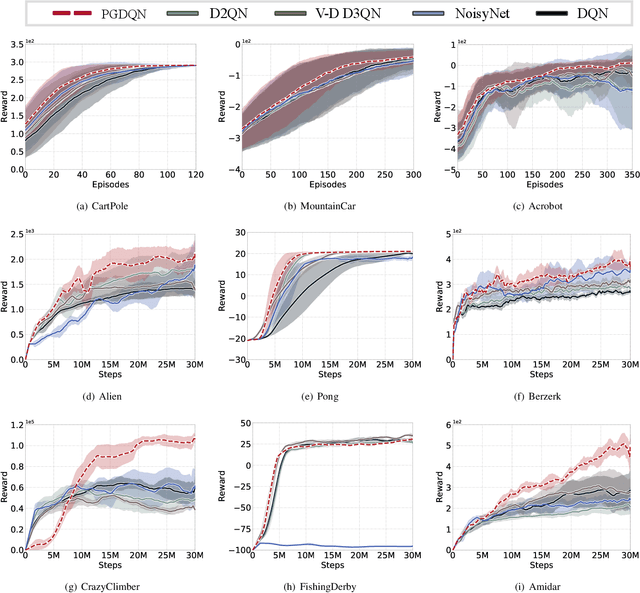
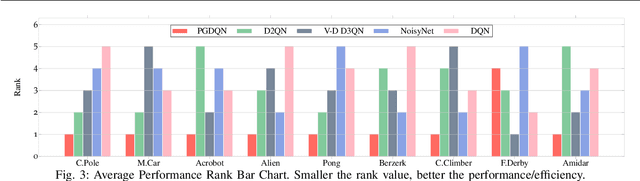
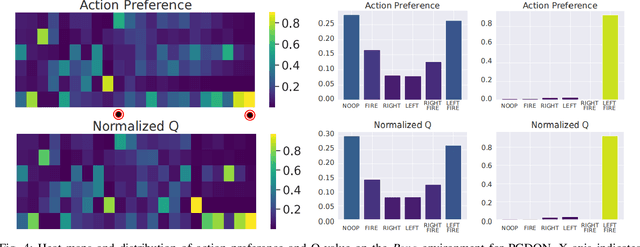
Massive practical works addressed by Deep Q-network (DQN) algorithm have indicated that stochastic policy, despite its simplicity, is the most frequently used exploration approach. However, most existing stochastic exploration approaches either explore new actions heuristically regardless of Q-values or inevitably introduce bias into the learning process to couple the sampling with Q-values. In this paper, we propose a novel preference-guided $\epsilon$-greedy exploration algorithm that can efficiently learn the action distribution in line with the landscape of Q-values for DQN without introducing additional bias. Specifically, we design a dual architecture consisting of two branches, one of which is a copy of DQN, namely the Q-branch. The other branch, which we call the preference branch, learns the action preference that the DQN implicit follows. We theoretically prove that the policy improvement theorem holds for the preference-guided $\epsilon$-greedy policy and experimentally show that the inferred action preference distribution aligns with the landscape of corresponding Q-values. Consequently, preference-guided $\epsilon$-greedy exploration motivates the DQN agent to take diverse actions, i.e., actions with larger Q-values can be sampled more frequently whereas actions with smaller Q-values still have a chance to be explored, thus encouraging the exploration. We assess the proposed method with four well-known DQN variants in nine different environments. Extensive results confirm the superiority of our proposed method in terms of performance and convergence speed. Index Terms- Preference-guided exploration, stochastic policy, data efficiency, deep reinforcement learning, deep Q-learning.