 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmPLe: Supporting Vision-Language Models via Adaptive-Debiased Ensemble Multi-Prompt Learning
Dec 20, 2025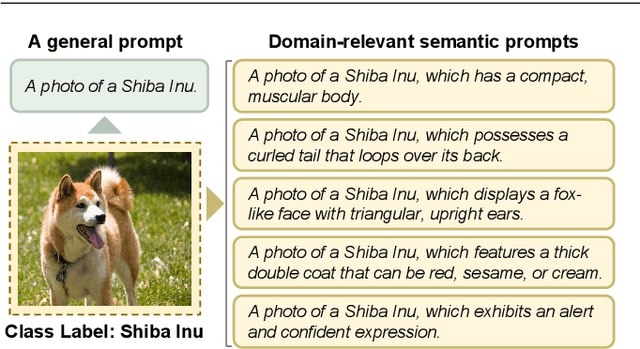

Multi-prompt learning methods have emerged as an effective approach for facilitating the rapid adaptation of vision-language models to downstream tasks with limited resources. Existing multi-prompt learning methods primarily focus on utilizing various meticulously designed prompts within a single foundation vision-language model to achieve superior performance. However, the overlooked model-prompt matching bias hinders the development of multi-prompt learning, i.e., the same prompt can convey different semantics across distinct vision-language models, such as CLIP-ViT-B/16 and CLIP-ViT-B/32, resulting in inconsistent predictions of identical prompt. To mitigate the impact of this bias on downstream tasks, we explore an ensemble learning approach to sufficiently aggregate the benefits of diverse predictions. Additionally, we further disclose the presence of sample-prompt matching bias, which originates from the prompt-irrelevant semantics encapsulated in the input samples. Thus, directly utilizing all information from the input samples for generating weights of ensemble learning can lead to suboptimal performance. In response, we extract prompt-relevant semantics from input samples by leveraging the guidance of the information theory-based analysis, adaptively calculating debiased ensemble weights. Overall, we propose Adaptive-Debiased Ensemble MultiPrompt Learning, abbreviated as AmPLe, to mitigate the two types of bias simultaneously. Extensive experiments on three representative tasks, i.e., generalization to novel classes, new target datasets, and unseen domain shifts, show that AmPLe can widely outperform existing methods. Theoretical validation from a causal perspective further supports the effectiveness of AmPLe.
Doubly Debiased Test-Time Prompt Tuning for Vision-Language Models
Nov 12, 2025Test-time prompt tuning for vision-language models has demonstrated impressive generalization capabilities under zero-shot settings. However, tuning the learnable prompts solely based on unlabeled test data may induce prompt optimization bias, ultimately leading to suboptimal performance on downstream tasks. In this work, we analyze the underlying causes of prompt optimization bias from both the model and data perspectives. In terms of the model, the entropy minimization objective typically focuses on reducing the entropy of model predictions while overlooking their correctness. This can result in overconfident yet incorrect outputs, thereby compromising the quality of prompt optimization. On the data side, prompts affected by optimization bias can introduce misalignment between visual and textual modalities, which further aggravates the prompt optimization bias. To this end, we propose a Doubly Debiased Test-Time Prompt Tuning method. Specifically, we first introduce a dynamic retrieval-augmented modulation module that retrieves high-confidence knowledge from a dynamic knowledge base using the test image feature as a query, and uses the retrieved knowledge to modulate the predictions. Guided by the refined predictions, we further develop a reliability-aware prompt optimization module that incorporates a confidence-based weighted ensemble and cross-modal consistency distillation to impose regularization constraints during prompt tuning. Extensive experiments across 15 benchmark datasets involving both natural distribution shifts and cross-datasets generalization demonstrate that our method outperforms baselines, validating its effectiveness in mitigating prompt optimization bias.
Interventional Imbalanced Multi-Modal Representation Learning via $β$-Generalization Front-Door Criterion
Jun 17, 2024



Multi-modal methods establish comprehensive superiority over uni-modal methods. However, the imbalanced contributions of different modalities to task-dependent predictions constantly degrade the discriminative performance of canonical multi-modal methods. Based on the contribution to task-dependent predictions, modalities can be identified as predominant and auxiliary modalities. Benchmark methods raise a tractable solution: augmenting the auxiliary modality with a minor contribution during training. However, our empirical explorations challenge the fundamental idea behind such behavior, and we further conclude that benchmark approaches suffer from certain defects: insufficient theoretical interpretability and limited exploration capability of discriminative knowledge. To this end, we revisit multi-modal representation learning from a causal perspective and build the Structural Causal Model. Following the empirical explorations, we determine to capture the true causality between the discriminative knowledge of predominant modality and predictive label while considering the auxiliary modality. Thus, we introduce the $\beta$-generalization front-door criterion. Furthermore, we propose a novel network for sufficiently exploring multi-modal discriminative knowledge. Rigorous theoretical analyses and various empirical evaluations are provided to support the effectiveness of the innate mechanism behind our proposed method.
Terahertz channel modeling based on surface sensing characteristics
Apr 03, 2024



The dielectric properties of environmental surfaces, including walls, floors and the ground, etc., play a crucial role in shaping the accuracy of terahertz (THz) channel modeling, thereby directly impacting the effectiveness of communication systems. Traditionally, acquiring these properties has relied on methods such as terahertz time-domain spectroscopy (THz-TDS) or vector network analyzers (VNA), demanding rigorous sample preparation and entailing a significant expenditure of time. However, such measurements are not always feasible, particularly in novel and uncharacterized scenarios. In this work, we propose a new approach for channel modeling that leverages the inherent sensing capabilities of THz channels. By comparing the results obtained through channel sensing with that derived from THz-TDS measurements, we demonstrate the method's ability to yield dependable surface property information. The application of this approach in both a miniaturized cityscape scenario and an indoor environment has shown consistency with experimental measurements, thereby verifying its effectiveness in real-world settings.
BayesPrompt: Prompting Large-Scale Pre-Trained Language Models on Few-shot Inference via Debiased Domain Abstraction
Jan 29, 2024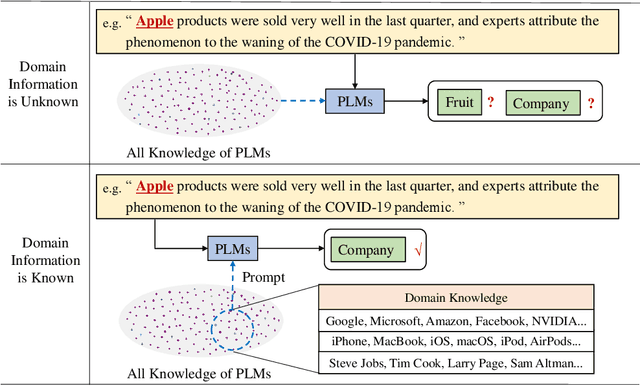
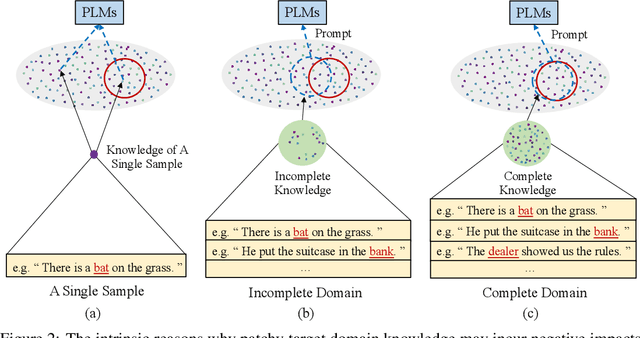
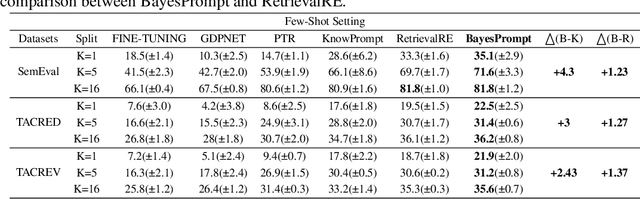
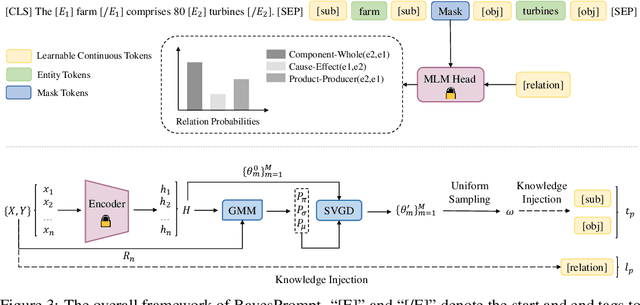
As a novel and effective fine-tuning paradigm based on large-scale pre-trained language models (PLMs), prompt-tuning aims to reduce the gap between downstream tasks and pre-training objectives. While prompt-tuning has yielded continuous advancements in various tasks, such an approach still remains a persistent defect: prompt-tuning methods fail to generalize to specific few-shot patterns. From the perspective of distribution analyses, we disclose that the intrinsic issues behind the phenomenon are the over-multitudinous conceptual knowledge contained in PLMs and the abridged knowledge for target downstream domains, which jointly result in that PLMs mis-locate the knowledge distributions corresponding to the target domains in the universal knowledge embedding space. To this end, we intuitively explore to approximate the unabridged target domains of downstream tasks in a debiased manner, and then abstract such domains to generate discriminative prompts, thereby providing the de-ambiguous guidance for PLMs. Guided by such an intuition, we propose a simple yet effective approach, namely BayesPrompt, to learn prompts that contain the domain discriminative information against the interference from domain-irrelevant knowledge. BayesPrompt primitively leverages known distributions to approximate the debiased factual distributions of target domains and further uniformly samples certain representative features from the approximated distributions to generate the ultimate prompts for PLMs. We provide theoretical insights with the connection to domain adaptation. Empirically, our method achieves state-of-the-art performance on benchmarks.
Neural-based Modeling for Performance Tuning of Spark Data Analytics
Jan 20, 2021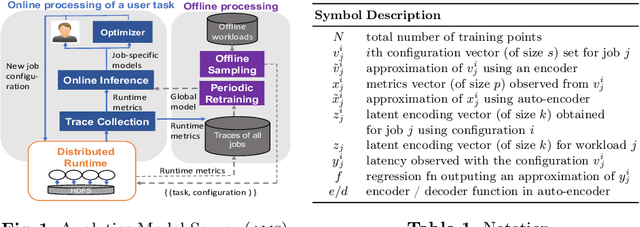
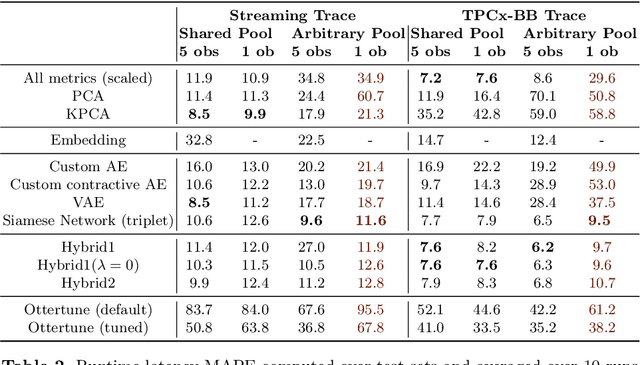
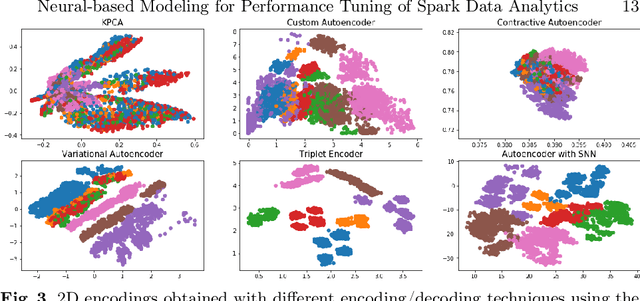
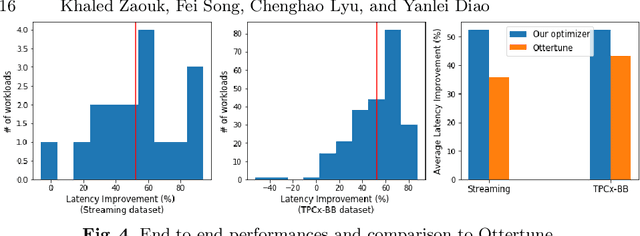
Cloud data analytics has become an integral part of enterprise business operations for data-driven insight discovery. Performance modeling of cloud data analytics is crucial for performance tuning and other critical operations in the cloud. Traditional modeling techniques fail to adapt to the high degree of diversity in workloads and system behaviors in this domain. In this paper, we bring recent Deep Learning techniques to bear on the process of automated performance modeling of cloud data analytics, with a focus on Spark data analytics as representative workloads. At the core of our work is the notion of learning workload embeddings (with a set of desired properties) to represent fundamental computational characteristics of different jobs, which enable performance prediction when used together with job configurations that control resource allocation and other system knobs. Our work provides an in-depth study of different modeling choices that suit our requirements. Results of extensive experiments reveal the strengths and limitations of different modeling methods, as well as superior performance of our best performing method over a state-of-the-art modeling tool for cloud analytics.
AnomalyBench: An Open Benchmark for Explainable Anomaly Detection
Oct 10, 2020
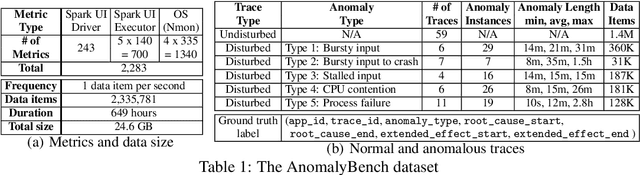
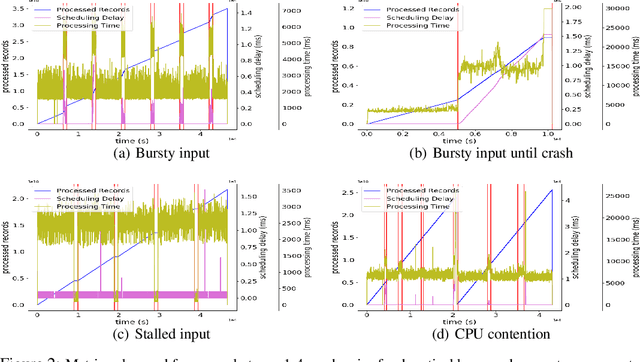

Access to high-quality data repositories and benchmarks have been instrumental in advancing the state of the art in many domains, as they provide the research community a common ground for training, testing, evaluating, comparing, and experimenting with novel machine learning models. Lack of such community resources for anomaly detection (AD) severely limits progress. In this report, we present AnomalyBench, the first comprehensive benchmark for explainable AD over high-dimensional (2000+) time series data. AnomalyBench has been systematically constructed based on real data traces from ~100 repeated executions of 10 large-scale stream processing jobs on a Spark cluster. 30+ of these executions were disturbed by introducing ~100 instances of different types of anomalous events (e.g., misbehaving inputs, resource contention, process failures). For each of these anomaly instances, ground truth labels for the root-cause interval as well as those for the effect interval are available, providing a means for supporting both AD tasks and explanation discovery (ED) tasks via root-cause analysis. We demonstrate the key design features and practical utility of AnomalyBench through an experimental study with three state-of-the-art semi-supervised AD techniques.
Probabilistic Topic and Syntax Modeling with Part-of-Speech LDA
Mar 12, 2013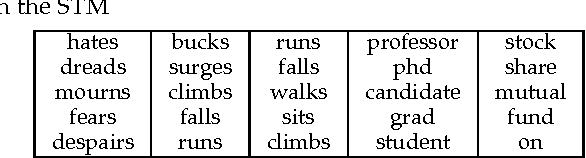
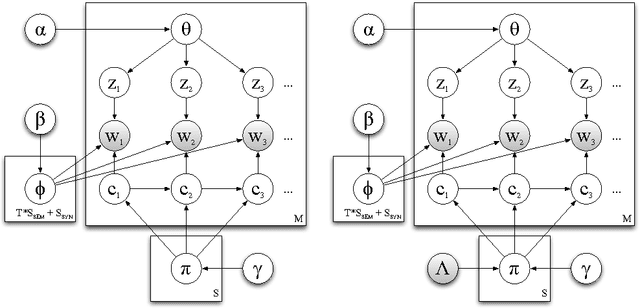
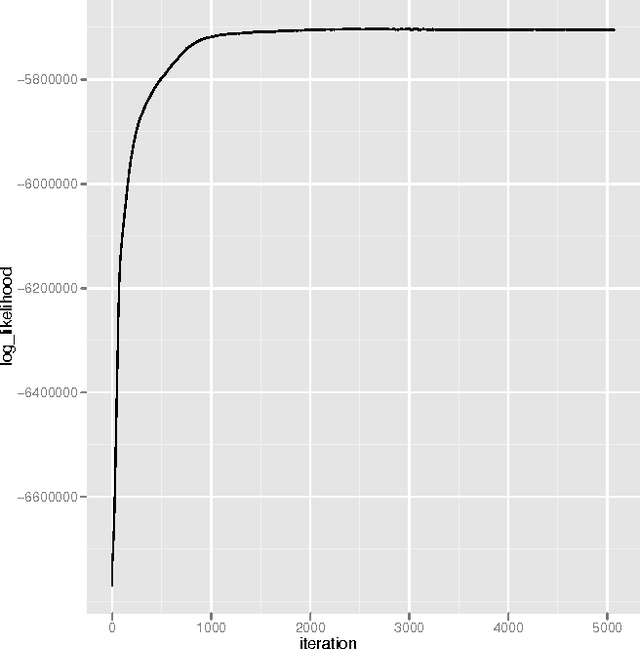
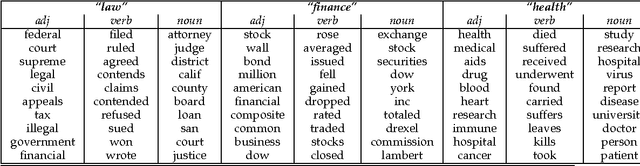
This article presents a probabilistic generative model for text based on semantic topics and syntactic classes called Part-of-Speech LDA (POSLDA). POSLDA simultaneously uncovers short-range syntactic patterns (syntax) and long-range semantic patterns (topics) that exist in document collections. This results in word distributions that are specific to both topics (sports, education, ...) and parts-of-speech (nouns, verbs, ...). For example, multinomial distributions over words are uncovered that can be understood as "nouns about weather" or "verbs about law". We describe the model and an approximate inference algorithm and then demonstrate the quality of the learned topics both qualitatively and quantitatively. Then, we discuss an NLP application where the output of POSLDA can lead to strong improvements in quality: unsupervised part-of-speech tagging. We describe algorithms for this task that make use of POSLDA-learned distributions that result in improved performance beyond the state of the art.