 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Multitask Prompted Training Enables Zero-Shot Task Generalization
Oct 15, 2021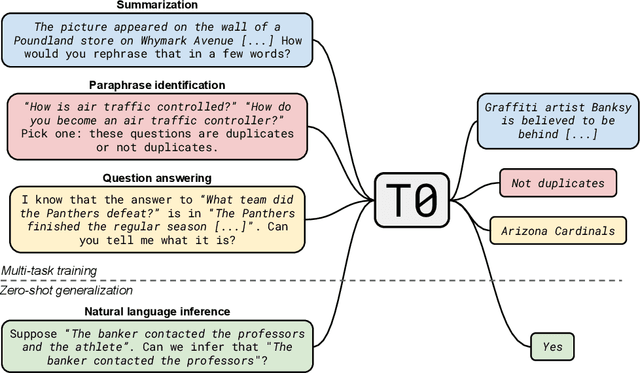

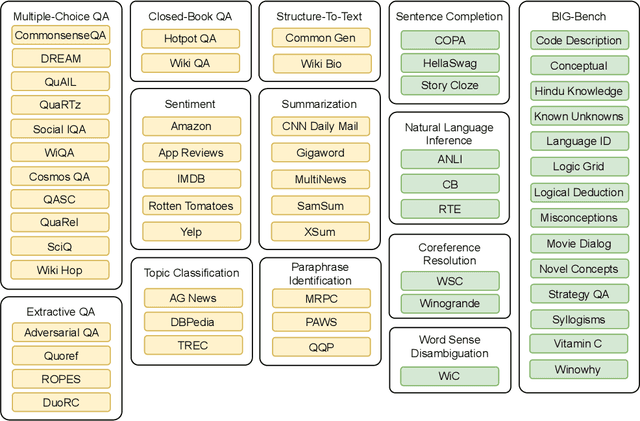

Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks. It has been hypothesized that this is a consequence of implicit multitask learning in language model training. Can zero-shot generalization instead be directly induced by explicit multitask learning? To test this question at scale, we develop a system for easily mapping general natural language tasks into a human-readable prompted form. We convert a large set of supervised datasets, each with multiple prompts using varying natural language. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. We fine-tune a pretrained encoder-decoder model on this multitask mixture covering a wide variety of tasks. The model attains strong zero-shot performance on several standard datasets, often outperforming models 16x its size. Further, our approach attains strong performance on a subset of tasks from the BIG-Bench benchmark, outperforming models 6x its size. All prompts and trained models are available at github.com/bigscience-workshop/promptsource/.
AnomalyBench: An Open Benchmark for Explainable Anomaly Detection
Oct 10, 2020
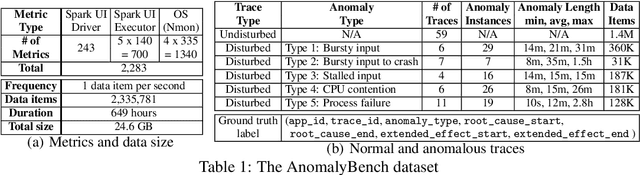
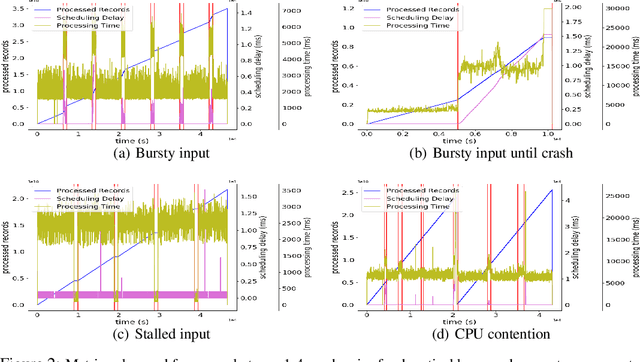

Access to high-quality data repositories and benchmarks have been instrumental in advancing the state of the art in many domains, as they provide the research community a common ground for training, testing, evaluating, comparing, and experimenting with novel machine learning models. Lack of such community resources for anomaly detection (AD) severely limits progress. In this report, we present AnomalyBench, the first comprehensive benchmark for explainable AD over high-dimensional (2000+) time series data. AnomalyBench has been systematically constructed based on real data traces from ~100 repeated executions of 10 large-scale stream processing jobs on a Spark cluster. 30+ of these executions were disturbed by introducing ~100 instances of different types of anomalous events (e.g., misbehaving inputs, resource contention, process failures). For each of these anomaly instances, ground truth labels for the root-cause interval as well as those for the effect interval are available, providing a means for supporting both AD tasks and explanation discovery (ED) tasks via root-cause analysis. We demonstrate the key design features and practical utility of AnomalyBench through an experimental study with three state-of-the-art semi-supervised AD techniques.