 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Between words and characters: A Brief History of Open-Vocabulary Modeling and Tokenization in NLP
Dec 20, 2021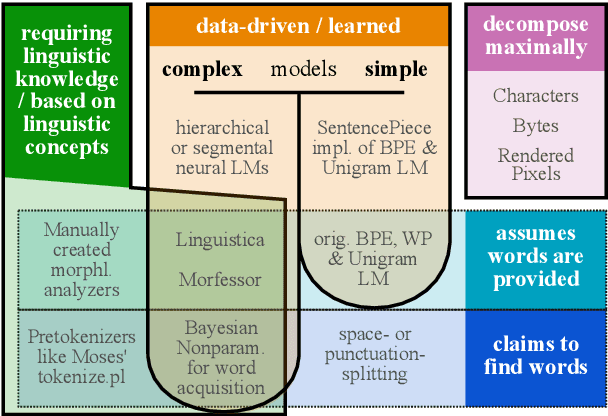
What are the units of text that we want to model? From bytes to multi-word expressions, text can be analyzed and generated at many granularities. Until recently, most natural language processing (NLP) models operated over words, treating those as discrete and atomic tokens, but starting with byte-pair encoding (BPE), subword-based approaches have become dominant in many areas, enabling small vocabularies while still allowing for fast inference. Is the end of the road character-level model or byte-level processing? In this survey, we connect several lines of work from the pre-neural and neural era, by showing how hybrid approaches of words and characters as well as subword-based approaches based on learned segmentation have been proposed and evaluated. We conclude that there is and likely will never be a silver bullet singular solution for all applications and that thinking seriously about tokenization remains important for many applications.
Multitask Prompted Training Enables Zero-Shot Task Generalization
Oct 15, 2021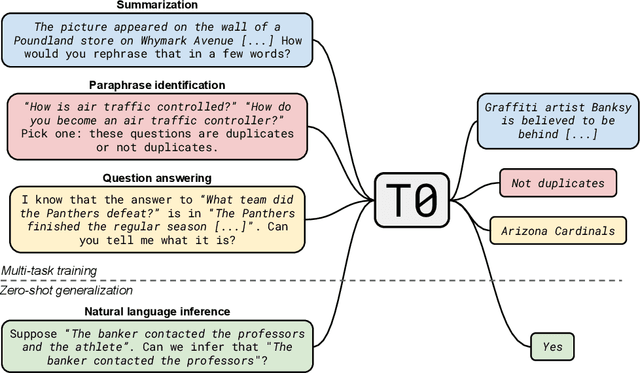

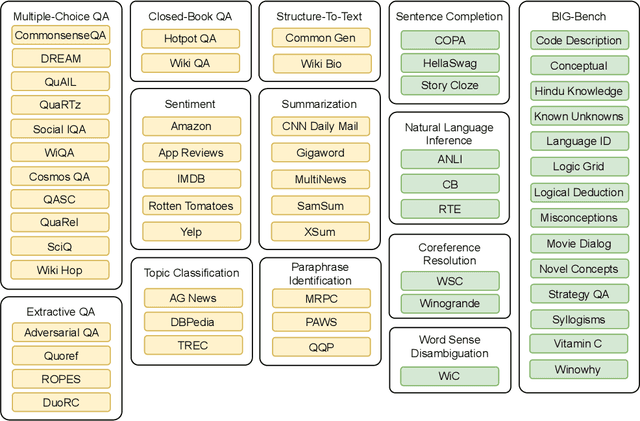

Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks. It has been hypothesized that this is a consequence of implicit multitask learning in language model training. Can zero-shot generalization instead be directly induced by explicit multitask learning? To test this question at scale, we develop a system for easily mapping general natural language tasks into a human-readable prompted form. We convert a large set of supervised datasets, each with multiple prompts using varying natural language. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. We fine-tune a pretrained encoder-decoder model on this multitask mixture covering a wide variety of tasks. The model attains strong zero-shot performance on several standard datasets, often outperforming models 16x its size. Further, our approach attains strong performance on a subset of tasks from the BIG-Bench benchmark, outperforming models 6x its size. All prompts and trained models are available at github.com/bigscience-workshop/promptsource/.
A*HAR: A New Benchmark towards Semi-supervised learning for Class-imbalanced Human Activity Recognition
Jan 13, 2021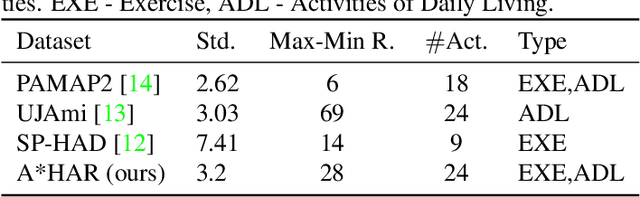
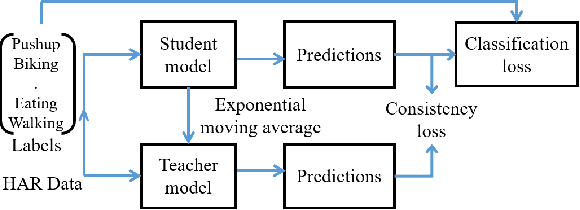
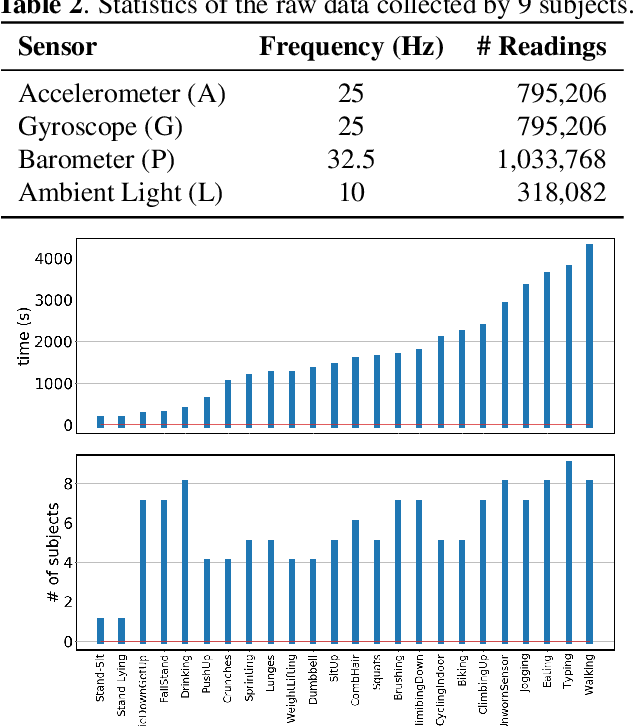
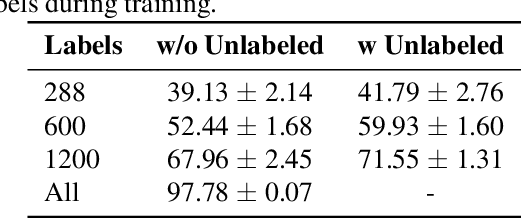
Despite the vast literature on Human Activity Recognition (HAR) with wearable inertial sensor data, it is perhaps surprising that there are few studies investigating semisupervised learning for HAR, particularly in a challenging scenario with class imbalance problem. In this work, we present a new benchmark, called A*HAR, towards semisupervised learning for class-imbalanced HAR. We evaluate state-of-the-art semi-supervised learning method on A*HAR, by combining Mean Teacher and Convolutional Neural Network. Interestingly, we find that Mean Teacher boosts the overall performance when training the classifier with fewer labelled samples and a large amount of unlabeled samples, but the classifier falls short in handling unbalanced activities. These findings lead to an interesting open problem, i.e., development of semi-supervised HAR algorithms that are class-imbalance aware without any prior knowledge on the class distribution for unlabeled samples. The dataset and benchmark evaluation are released at https://github.com/I2RDL2/ASTAR-HAR for future research.