 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Active Learning for Label-Efficient Training of Semantic Neural Radiance Field
Jul 23, 2025Neural Radiance Field (NeRF) models are implicit neural scene representation methods that offer unprecedented capabilities in novel view synthesis. Semantically-aware NeRFs not only capture the shape and radiance of a scene, but also encode semantic information of the scene. The training of semantically-aware NeRFs typically requires pixel-level class labels, which can be prohibitively expensive to collect. In this work, we explore active learning as a potential solution to alleviate the annotation burden. We investigate various design choices for active learning of semantically-aware NeRF, including selection granularity and selection strategies. We further propose a novel active learning strategy that takes into account 3D geometric constraints in sample selection. Our experiments demonstrate that active learning can effectively reduce the annotation cost of training semantically-aware NeRF, achieving more than 2X reduction in annotation cost compared to random sampling.
Can Large Language Models Improve Spectral Graph Neural Networks?
Jun 17, 2025Spectral Graph Neural Networks (SGNNs) have attracted significant attention due to their ability to approximate arbitrary filters. They typically rely on supervision from downstream tasks to adaptively learn appropriate filters. However, under label-scarce conditions, SGNNs may learn suboptimal filters, leading to degraded performance. Meanwhile, the remarkable success of Large Language Models (LLMs) has inspired growing interest in exploring their potential within the GNN domain. This naturally raises an important question: \textit{Can LLMs help overcome the limitations of SGNNs and enhance their performance?} In this paper, we propose a novel approach that leverages LLMs to estimate the homophily of a given graph. The estimated homophily is then used to adaptively guide the design of polynomial spectral filters, thereby improving the expressiveness and adaptability of SGNNs across diverse graph structures. Specifically, we introduce a lightweight pipeline in which the LLM generates homophily-aware priors, which are injected into the filter coefficients to better align with the underlying graph topology. Extensive experiments on benchmark datasets demonstrate that our LLM-driven SGNN framework consistently outperforms existing baselines under both homophilic and heterophilic settings, with minimal computational and monetary overhead.
Addressing Heterogeneity and Heterophily in Graphs: A Heterogeneous Heterophilic Spectral Graph Neural Network
Oct 17, 2024Graph Neural Networks (GNNs) have garnered significant scholarly attention for their powerful capabilities in modeling graph structures. Despite this, two primary challenges persist: heterogeneity and heterophily. Existing studies often address heterogeneous and heterophilic graphs separately, leaving a research gap in the understanding of heterogeneous heterophilic graphs-those that feature diverse node or relation types with dissimilar connected nodes. To address this gap, we investigate the application of spectral graph filters within heterogeneous graphs. Specifically, we propose a Heterogeneous Heterophilic Spectral Graph Neural Network (H2SGNN), which employs a dual-module approach: local independent filtering and global hybrid filtering. The local independent filtering module applies polynomial filters to each subgraph independently to adapt to different homophily, while the global hybrid filtering module captures interactions across different subgraphs. Extensive empirical evaluations on four real-world datasets demonstrate the superiority of H2SGNN compared to state-of-the-art methods.
A Survey and Evaluation of Adversarial Attacks for Object Detection
Aug 06, 2024Deep learning models excel in various computer vision tasks but are susceptible to adversarial examples-subtle perturbations in input data that lead to incorrect predictions. This vulnerability poses significant risks in safety-critical applications such as autonomous vehicles, security surveillance, and aircraft health monitoring. While numerous surveys focus on adversarial attacks in image classification, the literature on such attacks in object detection is limited. This paper offers a comprehensive taxonomy of adversarial attacks specific to object detection, reviews existing adversarial robustness evaluation metrics, and systematically assesses open-source attack methods and model robustness. Key observations are provided to enhance the understanding of attack effectiveness and corresponding countermeasures. Additionally, we identify crucial research challenges to guide future efforts in securing automated object detection systems.
Improving Expressive Power of Spectral Graph Neural Networks with Eigenvalue Correction
Jan 28, 2024In recent years, spectral graph neural networks, characterized by polynomial filters, have garnered increasing attention and have achieved remarkable performance in tasks such as node classification. These models typically assume that eigenvalues for the normalized Laplacian matrix are distinct from each other, thus expecting a polynomial filter to have a high fitting ability. However, this paper empirically observes that normalized Laplacian matrices frequently possess repeated eigenvalues. Moreover, we theoretically establish that the number of distinguishable eigenvalues plays a pivotal role in determining the expressive power of spectral graph neural networks. In light of this observation, we propose an eigenvalue correction strategy that can free polynomial filters from the constraints of repeated eigenvalue inputs. Concretely, the proposed eigenvalue correction strategy enhances the uniform distribution of eigenvalues, thus mitigating repeated eigenvalues, and improving the fitting capacity and expressive power of polynomial filters. Extensive experimental results on both synthetic and real-world datasets demonstrate the superiority of our method.
SemiCurv: Semi-Supervised Curvilinear Structure Segmentation
May 19, 2022
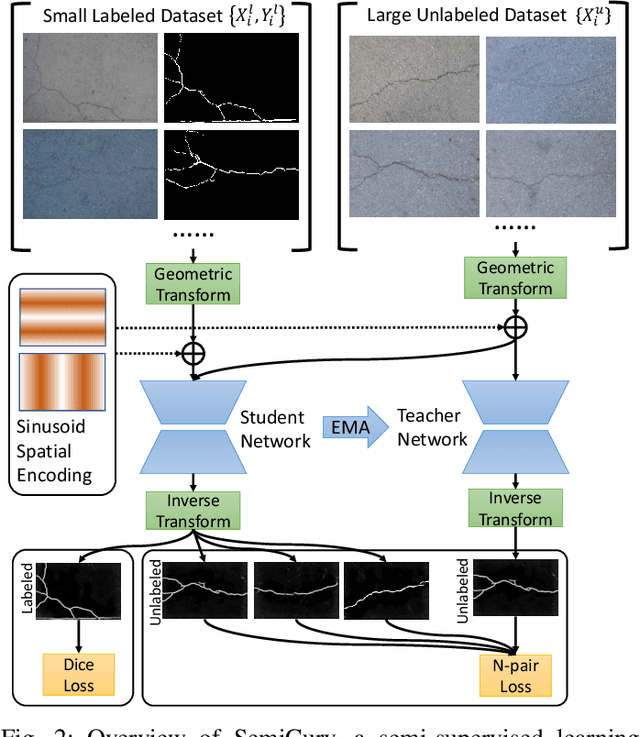
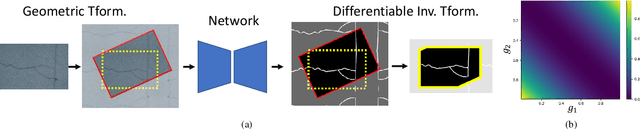
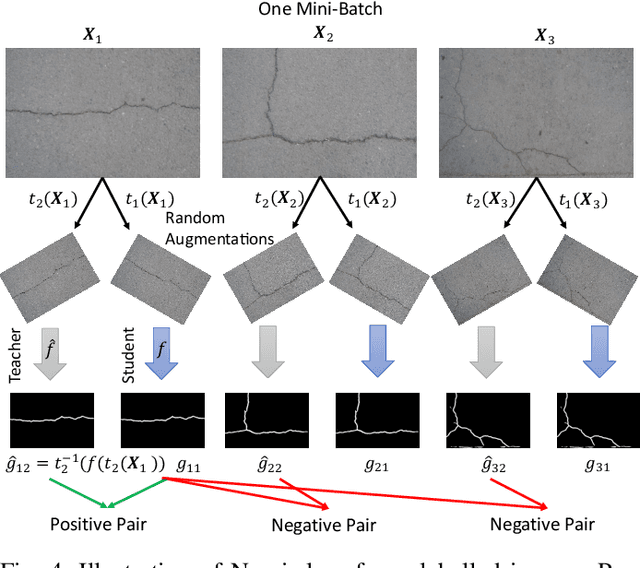
Recent work on curvilinear structure segmentation has mostly focused on backbone network design and loss engineering. The challenge of collecting labelled data, an expensive and labor intensive process, has been overlooked. While labelled data is expensive to obtain, unlabelled data is often readily available. In this work, we propose SemiCurv, a semi-supervised learning (SSL) framework for curvilinear structure segmentation that is able to utilize such unlabelled data to reduce the labelling burden. Our framework addresses two key challenges in formulating curvilinear segmentation in a semi-supervised manner. First, to fully exploit the power of consistency based SSL, we introduce a geometric transformation as strong data augmentation and then align segmentation predictions via a differentiable inverse transformation to enable the computation of pixel-wise consistency. Second, the traditional mean square error (MSE) on unlabelled data is prone to collapsed predictions and this issue exacerbates with severe class imbalance (significantly more background pixels). We propose a N-pair consistency loss to avoid trivial predictions on unlabelled data. We evaluate SemiCurv on six curvilinear segmentation datasets, and find that with no more than 5% of the labelled data, it achieves close to 95% of the performance relative to its fully supervised counterpart.
Revisiting Pretraining for Semi-Supervised Learning in the Low-Label Regime
May 06, 2022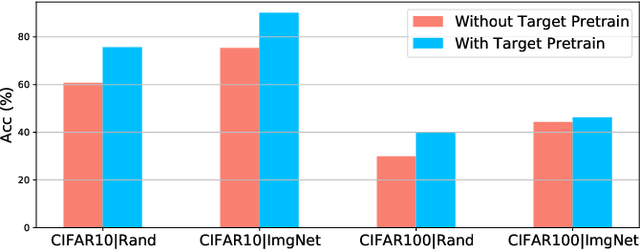
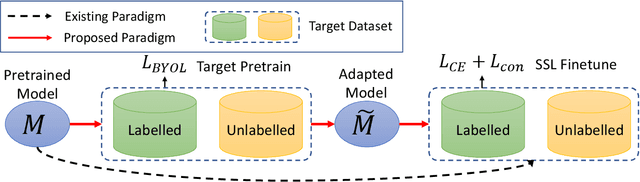
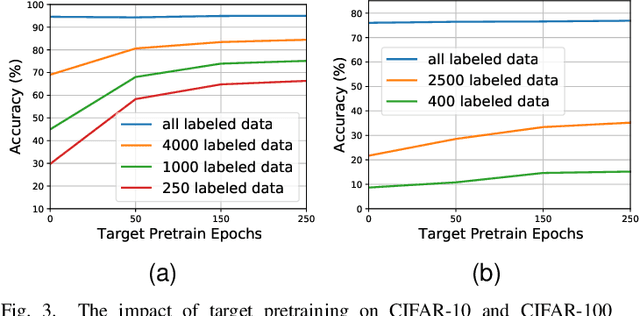
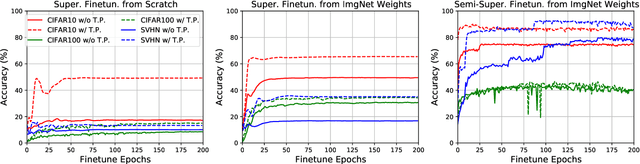
Semi-supervised learning (SSL) addresses the lack of labeled data by exploiting large unlabeled data through pseudolabeling. However, in the extremely low-label regime, pseudo labels could be incorrect, a.k.a. the confirmation bias, and the pseudo labels will in turn harm the network training. Recent studies combined finetuning (FT) from pretrained weights with SSL to mitigate the challenges and claimed superior results in the low-label regime. In this work, we first show that the better pretrained weights brought in by FT account for the state-of-the-art performance, and importantly that they are universally helpful to off-the-shelf semi-supervised learners. We further argue that direct finetuning from pretrained weights is suboptimal due to covariate shift and propose a contrastive target pretraining step to adapt model weights towards target dataset. We carried out extensive experiments on both classification and segmentation tasks by doing target pretraining then followed by semi-supervised finetuning. The promising results validate the efficacy of target pretraining for SSL, in particular in the low-label regime.
A*HAR: A New Benchmark towards Semi-supervised learning for Class-imbalanced Human Activity Recognition
Jan 13, 2021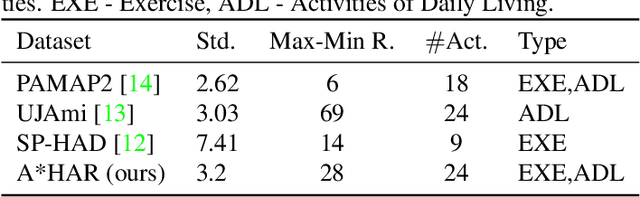
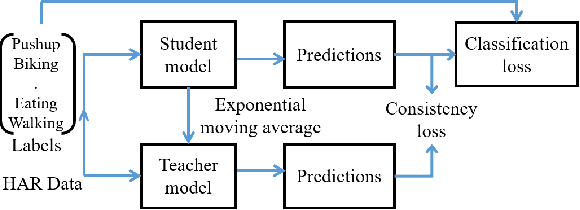
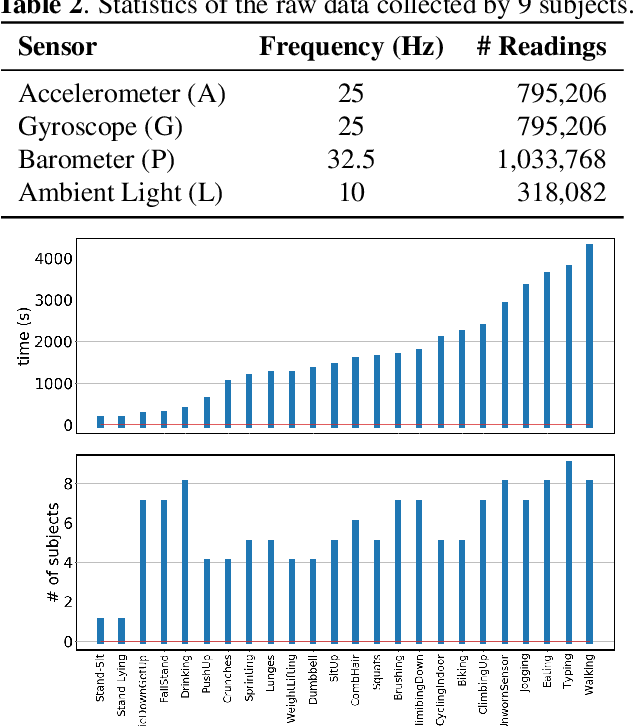
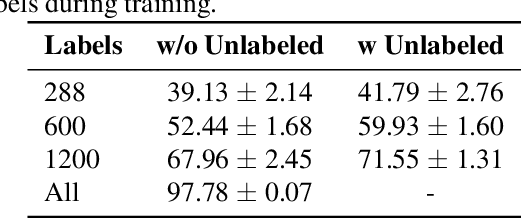
Despite the vast literature on Human Activity Recognition (HAR) with wearable inertial sensor data, it is perhaps surprising that there are few studies investigating semisupervised learning for HAR, particularly in a challenging scenario with class imbalance problem. In this work, we present a new benchmark, called A*HAR, towards semisupervised learning for class-imbalanced HAR. We evaluate state-of-the-art semi-supervised learning method on A*HAR, by combining Mean Teacher and Convolutional Neural Network. Interestingly, we find that Mean Teacher boosts the overall performance when training the classifier with fewer labelled samples and a large amount of unlabeled samples, but the classifier falls short in handling unbalanced activities. These findings lead to an interesting open problem, i.e., development of semi-supervised HAR algorithms that are class-imbalance aware without any prior knowledge on the class distribution for unlabeled samples. The dataset and benchmark evaluation are released at https://github.com/I2RDL2/ASTAR-HAR for future research.