 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBox-Level Class-Balanced Sampling for Active Object Detection
Aug 25, 2025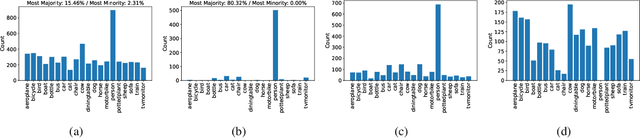
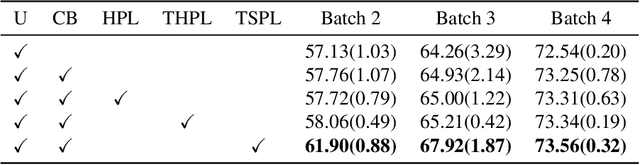

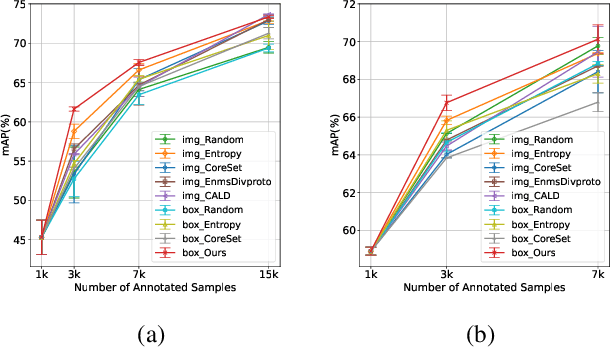
Training deep object detectors demands expensive bounding box annotation. Active learning (AL) is a promising technique to alleviate the annotation burden. Performing AL at box-level for object detection, i.e., selecting the most informative boxes to label and supplementing the sparsely-labelled image with pseudo labels, has been shown to be more cost-effective than selecting and labelling the entire image. In box-level AL for object detection, we observe that models at early stage can only perform well on majority classes, making the pseudo labels severely class-imbalanced. We propose a class-balanced sampling strategy to select more objects from minority classes for labelling, so as to make the final training data, \ie, ground truth labels obtained by AL and pseudo labels, more class-balanced to train a better model. We also propose a task-aware soft pseudo labelling strategy to increase the accuracy of pseudo labels. We evaluate our method on public benchmarking datasets and show that our method achieves state-of-the-art performance.
Exploring Active Learning for Label-Efficient Training of Semantic Neural Radiance Field
Jul 23, 2025Neural Radiance Field (NeRF) models are implicit neural scene representation methods that offer unprecedented capabilities in novel view synthesis. Semantically-aware NeRFs not only capture the shape and radiance of a scene, but also encode semantic information of the scene. The training of semantically-aware NeRFs typically requires pixel-level class labels, which can be prohibitively expensive to collect. In this work, we explore active learning as a potential solution to alleviate the annotation burden. We investigate various design choices for active learning of semantically-aware NeRF, including selection granularity and selection strategies. We further propose a novel active learning strategy that takes into account 3D geometric constraints in sample selection. Our experiments demonstrate that active learning can effectively reduce the annotation cost of training semantically-aware NeRF, achieving more than 2X reduction in annotation cost compared to random sampling.
Exploring Spatial Diversity for Region-based Active Learning
Jul 23, 2025State-of-the-art methods for semantic segmentation are based on deep neural networks trained on large-scale labeled datasets. Acquiring such datasets would incur large annotation costs, especially for dense pixel-level prediction tasks like semantic segmentation. We consider region-based active learning as a strategy to reduce annotation costs while maintaining high performance. In this setting, batches of informative image regions instead of entire images are selected for labeling. Importantly, we propose that enforcing local spatial diversity is beneficial for active learning in this case, and to incorporate spatial diversity along with the traditional active selection criterion, e.g., data sample uncertainty, in a unified optimization framework for region-based active learning. We apply this framework to the Cityscapes and PASCAL VOC datasets and demonstrate that the inclusion of spatial diversity effectively improves the performance of uncertainty-based and feature diversity-based active learning methods. Our framework achieves $95\%$ performance of fully supervised methods with only $5-9\%$ of the labeled pixels, outperforming all state-of-the-art region-based active learning methods for semantic segmentation.
Exploring Active Learning for Semiconductor Defect Segmentation
Jul 23, 2025The development of X-Ray microscopy (XRM) technology has enabled non-destructive inspection of semiconductor structures for defect identification. Deep learning is widely used as the state-of-the-art approach to perform visual analysis tasks. However, deep learning based models require large amount of annotated data to train. This can be time-consuming and expensive to obtain especially for dense prediction tasks like semantic segmentation. In this work, we explore active learning (AL) as a potential solution to alleviate the annotation burden. We identify two unique challenges when applying AL on semiconductor XRM scans: large domain shift and severe class-imbalance. To address these challenges, we propose to perform contrastive pretraining on the unlabelled data to obtain the initialization weights for each AL cycle, and a rareness-aware acquisition function that favors the selection of samples containing rare classes. We evaluate our method on a semiconductor dataset that is compiled from XRM scans of high bandwidth memory structures composed of logic and memory dies, and demonstrate that our method achieves state-of-the-art performance.
Exploring Diversity-based Active Learning for 3D Object Detection in Autonomous Driving
May 16, 2022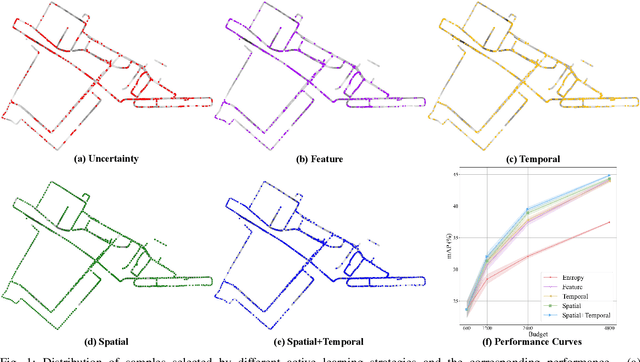
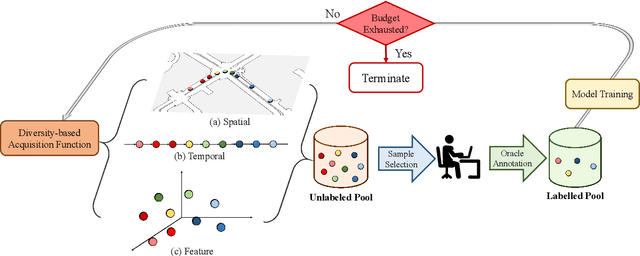
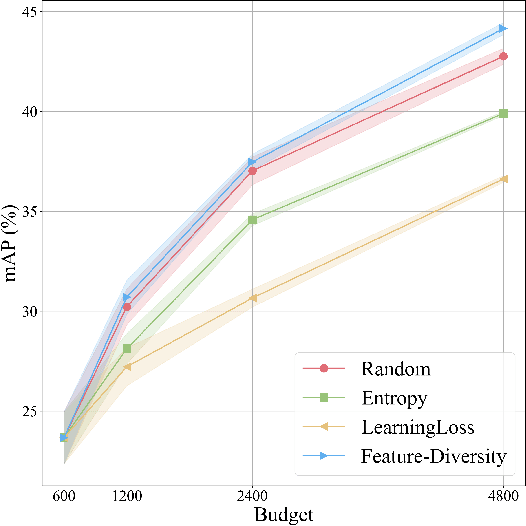
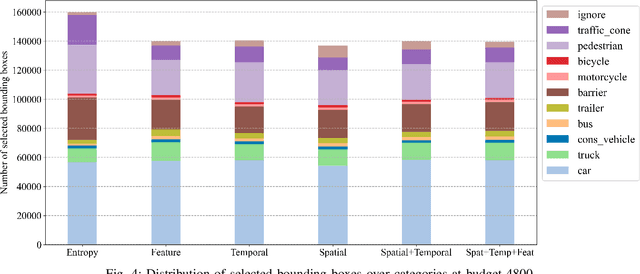
3D object detection has recently received much attention due to its great potential in autonomous vehicle (AV). The success of deep learning based object detectors relies on the availability of large-scale annotated datasets, which is time-consuming and expensive to compile, especially for 3D bounding box annotation. In this work, we investigate diversity-based active learning (AL) as a potential solution to alleviate the annotation burden. Given limited annotation budget, only the most informative frames and objects are automatically selected for human to annotate. Technically, we take the advantage of the multimodal information provided in an AV dataset, and propose a novel acquisition function that enforces spatial and temporal diversity in the selected samples. We benchmark the proposed method against other AL strategies under realistic annotation cost measurement, where the realistic costs for annotating a frame and a 3D bounding box are both taken into consideration. We demonstrate the effectiveness of the proposed method on the nuScenes dataset and show that it outperforms existing AL strategies significantly.
Revisiting Pretraining for Semi-Supervised Learning in the Low-Label Regime
May 06, 2022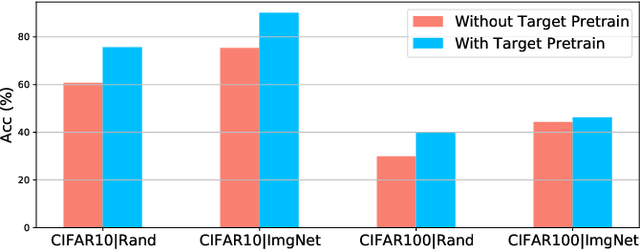
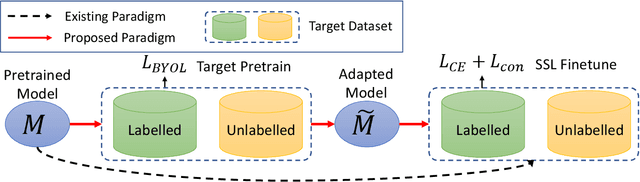
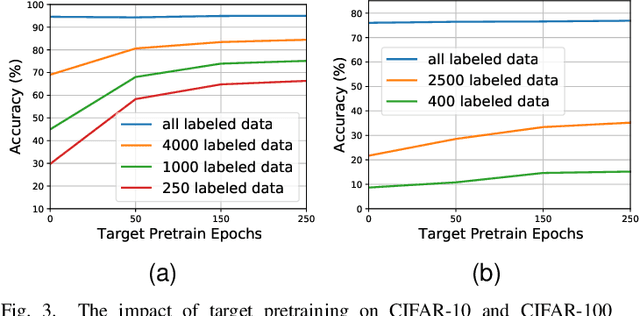
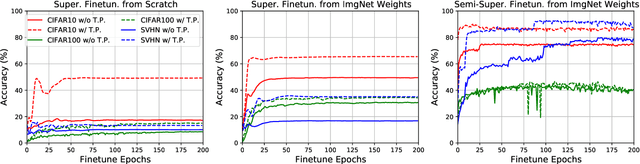
Semi-supervised learning (SSL) addresses the lack of labeled data by exploiting large unlabeled data through pseudolabeling. However, in the extremely low-label regime, pseudo labels could be incorrect, a.k.a. the confirmation bias, and the pseudo labels will in turn harm the network training. Recent studies combined finetuning (FT) from pretrained weights with SSL to mitigate the challenges and claimed superior results in the low-label regime. In this work, we first show that the better pretrained weights brought in by FT account for the state-of-the-art performance, and importantly that they are universally helpful to off-the-shelf semi-supervised learners. We further argue that direct finetuning from pretrained weights is suboptimal due to covariate shift and propose a contrastive target pretraining step to adapt model weights towards target dataset. We carried out extensive experiments on both classification and segmentation tasks by doing target pretraining then followed by semi-supervised finetuning. The promising results validate the efficacy of target pretraining for SSL, in particular in the low-label regime.
Label-Efficient Point Cloud Semantic Segmentation: An Active Learning Approach
Jan 18, 2021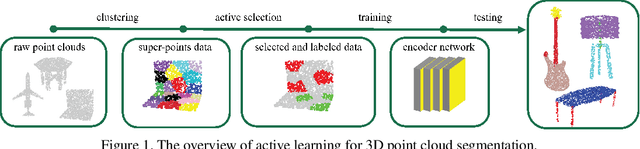

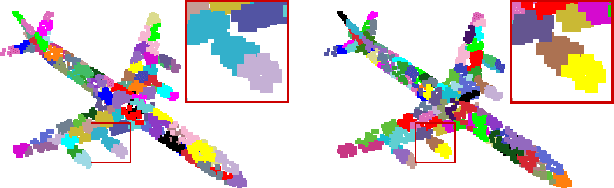

Semantic segmentation of 3D point clouds relies on training deep models with a large amount of labeled data. However, labeling 3D point clouds is expensive, thus smart approach towards data annotation, a.k.a. active learning is essential to label-efficient point cloud segmentation. In this work, we first propose a more realistic annotation counting scheme so that a fair benchmark is possible. To better exploit labeling budget, we adopt a super-point based active learning strategy where we make use of manifold defined on the point cloud geometry. We further propose active learning strategy to encourage shape level diversity and local spatial consistency constraint. Experiments on two benchmark datasets demonstrate the efficacy of our proposed active learning strategy for label-efficient semantic segmentation of point clouds. Notably, we achieve significant improvement at all levels of annotation budgets and outperform the state-of-the-art methods under the same level of annotation cost.
TEA-DNN: the Quest for Time-Energy-Accuracy Co-optimized Deep Neural Networks
Nov 29, 2018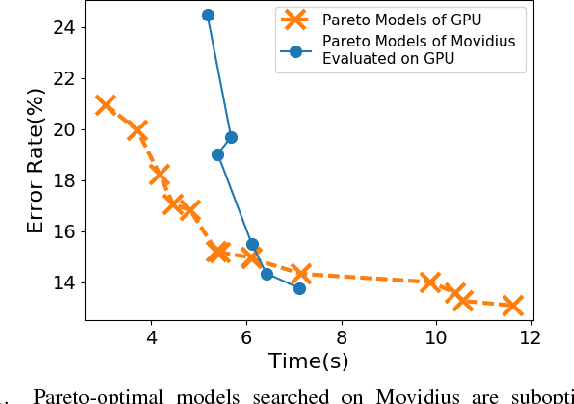
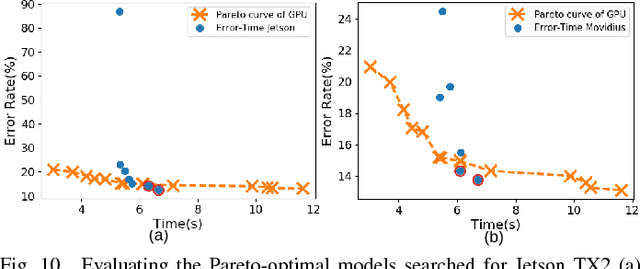
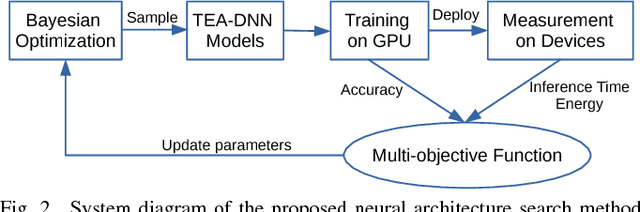
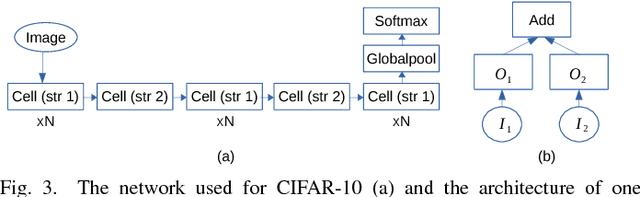
Embedded deep learning platforms have witnessed two simultaneous improvements. First, the accuracy of convolutional neural networks (CNNs) has been significantly improved through the use of automated neural-architecture search (NAS) algorithms to determine CNN structure. Second, there has been increasing interest in developing application-specific platforms for CNNs that provide improved inference performance and energy consumption as compared to GPUs. Embedded deep learning platforms differ in the amount of compute resources and memory-access bandwidth, which would affect performance and energy consumption of CNNs. It is therefore critical to consider the available hardware resources in the network architecture search. To this end, we introduce TEA-DNN, a NAS algorithm targeting multi-objective optimization of execution time, energy consumption, and classification accuracy of CNN workloads on embedded architectures. TEA-DNN leverages energy and execution time measurements on embedded hardware when exploring the Pareto-optimal curves across accuracy, execution time, and energy consumption and does not require additional effort to model the underlying hardware. We apply TEA-DNN for image classification on actual embedded platforms (NVIDIA Jetson TX2 and Intel Movidius Neural Compute Stick). We highlight the Pareto-optimal operating points that emphasize the necessity to explicitly consider hardware characteristics in the search process. To the best of our knowledge, this is the most comprehensive study of Pareto-optimal models across a range of hardware platforms using actual measurements on hardware to obtain objective values.