 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUT-DLA: Lookup Table as Efficient Extreme Low-Bit Deep Learning Accelerator
Jan 18, 2025The emergence of neural network capabilities invariably leads to a significant surge in computational demands due to expanding model sizes and increased computational complexity. To reduce model size and lower inference costs, recent research has focused on simplifying models and designing hardware accelerators using low-bit quantization. However, due to numerical representation limits, scalar quantization cannot reduce bit width lower than 1-bit, diminishing its benefits. To break through these limitations, we introduce LUT-DLA, a Look-Up Table (LUT) Deep Learning Accelerator Framework that utilizes vector quantization to convert neural network models into LUTs, achieving extreme low-bit quantization. The LUT-DLA framework facilitates efficient and cost-effective hardware accelerator designs and supports the LUTBoost algorithm, which helps to transform various DNN models into LUT-based models via multistage training, drastically cutting both computational and hardware overhead. Additionally, through co-design space exploration, LUT-DLA assesses the impact of various model and hardware parameters to fine-tune hardware configurations for different application scenarios, optimizing performance and efficiency. Our comprehensive experiments show that LUT-DLA achieves improvements in power efficiency and area efficiency with gains of $1.4$~$7.0\times$ and $1.5$~$146.1\times$, respectively, while maintaining only a modest accuracy drop. For CNNs, accuracy decreases by $0.1\%$~$3.1\%$ using the $L_2$ distance similarity, $0.1\%$~$3.4\%$ with the $L_1$ distance similarity, and $0.1\%$~$3.8\%$ when employing the Chebyshev distance similarity. For transformer-based models, the accuracy drop ranges from $1.4\%$ to $3.0\%$.
TEA-DNN: the Quest for Time-Energy-Accuracy Co-optimized Deep Neural Networks
Nov 29, 2018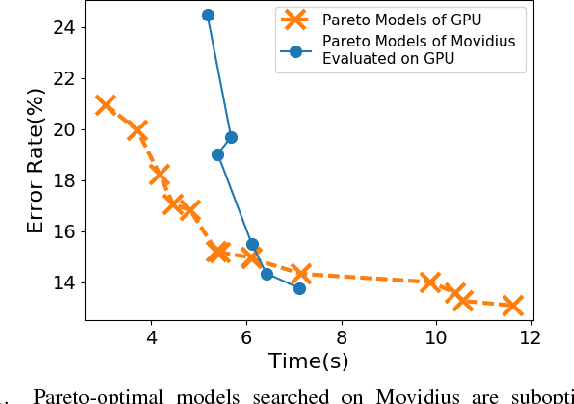
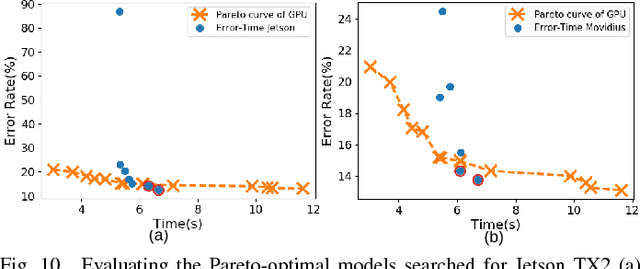
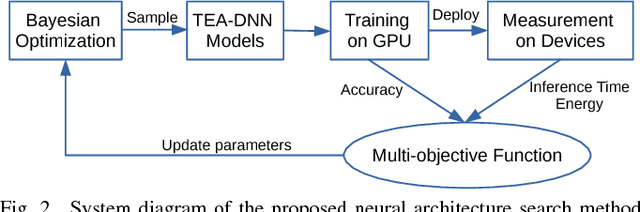
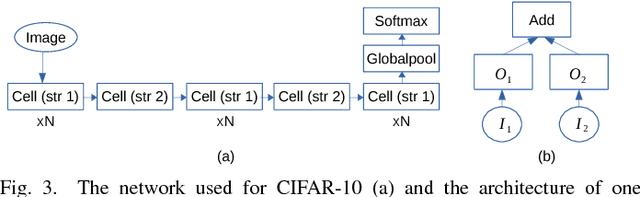
Embedded deep learning platforms have witnessed two simultaneous improvements. First, the accuracy of convolutional neural networks (CNNs) has been significantly improved through the use of automated neural-architecture search (NAS) algorithms to determine CNN structure. Second, there has been increasing interest in developing application-specific platforms for CNNs that provide improved inference performance and energy consumption as compared to GPUs. Embedded deep learning platforms differ in the amount of compute resources and memory-access bandwidth, which would affect performance and energy consumption of CNNs. It is therefore critical to consider the available hardware resources in the network architecture search. To this end, we introduce TEA-DNN, a NAS algorithm targeting multi-objective optimization of execution time, energy consumption, and classification accuracy of CNN workloads on embedded architectures. TEA-DNN leverages energy and execution time measurements on embedded hardware when exploring the Pareto-optimal curves across accuracy, execution time, and energy consumption and does not require additional effort to model the underlying hardware. We apply TEA-DNN for image classification on actual embedded platforms (NVIDIA Jetson TX2 and Intel Movidius Neural Compute Stick). We highlight the Pareto-optimal operating points that emphasize the necessity to explicitly consider hardware characteristics in the search process. To the best of our knowledge, this is the most comprehensive study of Pareto-optimal models across a range of hardware platforms using actual measurements on hardware to obtain objective values.