 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Active Learning for Semiconductor Defect Segmentation
Jul 23, 2025The development of X-Ray microscopy (XRM) technology has enabled non-destructive inspection of semiconductor structures for defect identification. Deep learning is widely used as the state-of-the-art approach to perform visual analysis tasks. However, deep learning based models require large amount of annotated data to train. This can be time-consuming and expensive to obtain especially for dense prediction tasks like semantic segmentation. In this work, we explore active learning (AL) as a potential solution to alleviate the annotation burden. We identify two unique challenges when applying AL on semiconductor XRM scans: large domain shift and severe class-imbalance. To address these challenges, we propose to perform contrastive pretraining on the unlabelled data to obtain the initialization weights for each AL cycle, and a rareness-aware acquisition function that favors the selection of samples containing rare classes. We evaluate our method on a semiconductor dataset that is compiled from XRM scans of high bandwidth memory structures composed of logic and memory dies, and demonstrate that our method achieves state-of-the-art performance.
Exploring Spatial Diversity for Region-based Active Learning
Jul 23, 2025State-of-the-art methods for semantic segmentation are based on deep neural networks trained on large-scale labeled datasets. Acquiring such datasets would incur large annotation costs, especially for dense pixel-level prediction tasks like semantic segmentation. We consider region-based active learning as a strategy to reduce annotation costs while maintaining high performance. In this setting, batches of informative image regions instead of entire images are selected for labeling. Importantly, we propose that enforcing local spatial diversity is beneficial for active learning in this case, and to incorporate spatial diversity along with the traditional active selection criterion, e.g., data sample uncertainty, in a unified optimization framework for region-based active learning. We apply this framework to the Cityscapes and PASCAL VOC datasets and demonstrate that the inclusion of spatial diversity effectively improves the performance of uncertainty-based and feature diversity-based active learning methods. Our framework achieves $95\%$ performance of fully supervised methods with only $5-9\%$ of the labeled pixels, outperforming all state-of-the-art region-based active learning methods for semantic segmentation.
AC-Refiner: Efficient Arithmetic Circuit Optimization Using Conditional Diffusion Models
Jul 03, 2025Arithmetic circuits, such as adders and multipliers, are fundamental components of digital systems, directly impacting the performance, power efficiency, and area footprint. However, optimizing these circuits remains challenging due to the vast design space and complex physical constraints. While recent deep learning-based approaches have shown promise, they struggle to consistently explore high-potential design variants, limiting their optimization efficiency. To address this challenge, we propose AC-Refiner, a novel arithmetic circuit optimization framework leveraging conditional diffusion models. Our key insight is to reframe arithmetic circuit synthesis as a conditional image generation task. By carefully conditioning the denoising diffusion process on target quality-of-results (QoRs), AC-Refiner consistently produces high-quality circuit designs. Furthermore, the explored designs are used to fine-tune the diffusion model, which focuses the exploration near the Pareto frontier. Experimental results demonstrate that AC-Refiner generates designs with superior Pareto optimality, outperforming state-of-the-art baselines. The performance gain is further validated by integrating AC-Refiner into practical applications.
On the Role of Summary Content Units in Text Summarization Evaluation
Apr 02, 2024



At the heart of the Pyramid evaluation method for text summarization lie human written summary content units (SCUs). These SCUs are concise sentences that decompose a summary into small facts. Such SCUs can be used to judge the quality of a candidate summary, possibly partially automated via natural language inference (NLI) systems. Interestingly, with the aim to fully automate the Pyramid evaluation, Zhang and Bansal (2021) show that SCUs can be approximated by automatically generated semantic role triplets (STUs). However, several questions currently lack answers, in particular: i) Are there other ways of approximating SCUs that can offer advantages? ii) Under which conditions are SCUs (or their approximations) offering the most value? In this work, we examine two novel strategies to approximate SCUs: generating SCU approximations from AMR meaning representations (SMUs) and from large language models (SGUs), respectively. We find that while STUs and SMUs are competitive, the best approximation quality is achieved by SGUs. We also show through a simple sentence-decomposition baseline (SSUs) that SCUs (and their approximations) offer the most value when ranking short summaries, but may not help as much when ranking systems or longer summaries.
Needle in a Haystack: An Analysis of Finding Qualified Workers on MTurk for Summarization
Dec 28, 2022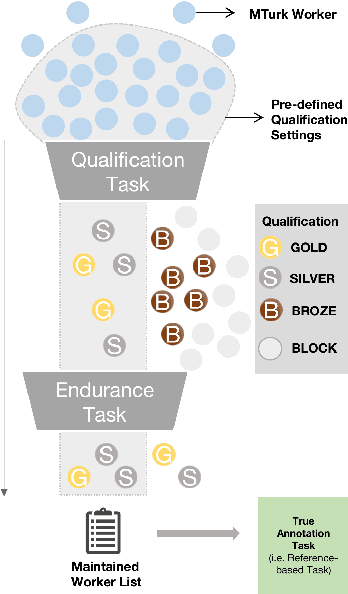


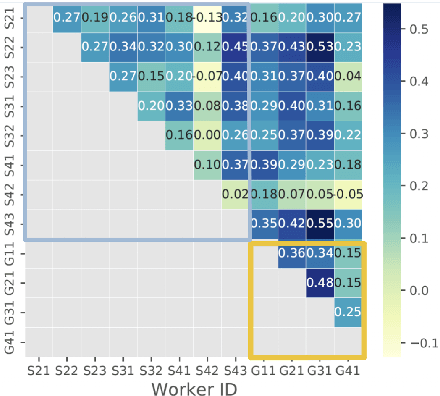
The acquisition of high-quality human annotations through crowdsourcing platforms like Amazon Mechanical Turk (MTurk) is more challenging than expected. The annotation quality might be affected by various aspects like annotation instructions, Human Intelligence Task (HIT) design, and wages paid to annotators, etc. To avoid potentially low-quality annotations which could mislead the evaluation of automatic summarization system outputs, we investigate the recruitment of high-quality MTurk workers via a three-step qualification pipeline. We show that we can successfully filter out bad workers before they carry out the evaluations and obtain high-quality annotations while optimizing the use of resources. This paper can serve as basis for the recruitment of qualified annotators in other challenging annotation tasks.