 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Semantic Cloaking for Jailbreak Attacks on Large Language Models
Mar 17, 2026Modern LLMs employ safety mechanisms that extend beyond surface-level input filtering to latent semantic representations and generation-time reasoning, enabling them to recover obfuscated malicious intent during inference and refuse accordingly, and rendering many surface-level obfuscation jailbreak attacks ineffective. We propose Structured Semantic Cloaking (S2C), a novel multi-dimensional jailbreak attack framework that manipulates how malicious semantic intent is reconstructed during model inference. S2C strategically distributes and reshapes semantic cues such that full intent consolidation requires multi-step inference and long-range co-reference resolution within deeper latent representations. The framework comprises three complementary mechanisms: (1) Contextual Reframing, which embeds the request within a plausible high-stakes scenario to bias the model toward compliance; (2) Content Fragmentation, which disperses the semantic signature of the request across disjoint prompt segments; and (3) Clue-Guided Camouflage, which disguises residual semantic cues while embedding recoverable markers that guide output generation. By delaying and restructuring semantic consolidation, S2C degrades safety triggers that depend on coherent or explicitly reconstructed malicious intent at decoding time, while preserving sufficient instruction recoverability for functional output generation. We evaluate S2C across multiple open-source and proprietary LLMs using HarmBench and JBB-Behaviors, where it improves Attack Success Rate (ASR) by 12.4% and 9.7%, respectively, over the current SOTA. Notably, S2C achieves substantial gains on GPT-5-mini, outperforming the strongest baseline by 26% on JBB-Behaviors. We also analyse which combinations perform best against broad families of models, and characterise the trade-off between the extent of obfuscation versus input recoverability on jailbreak success.
GAPNet: A Lightweight Framework for Image and Video Salient Object Detection via Granularity-Aware Paradigm
Aug 11, 2025Recent salient object detection (SOD) models predominantly rely on heavyweight backbones, incurring substantial computational cost and hindering their practical application in various real-world settings, particularly on edge devices. This paper presents GAPNet, a lightweight network built on the granularity-aware paradigm for both image and video SOD. We assign saliency maps of different granularities to supervise the multi-scale decoder side-outputs: coarse object locations for high-level outputs and fine-grained object boundaries for low-level outputs. Specifically, our decoder is built with granularity-aware connections which fuse high-level features of low granularity and low-level features of high granularity, respectively. To support these connections, we design granular pyramid convolution (GPC) and cross-scale attention (CSA) modules for efficient fusion of low-scale and high-scale features, respectively. On top of the encoder, a self-attention module is built to learn global information, enabling accurate object localization with negligible computational cost. Unlike traditional U-Net-based approaches, our proposed method optimizes feature utilization and semantic interpretation while applying appropriate supervision at each processing stage. Extensive experiments show that the proposed method achieves a new state-of-the-art performance among lightweight image and video SOD models. Code is available at https://github.com/yuhuan-wu/GAPNet.
Memory-Augmented Dual-Decoder Networks for Multi-Class Unsupervised Anomaly Detection
Apr 21, 2025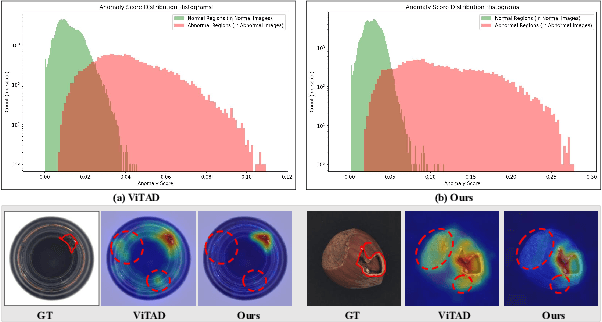
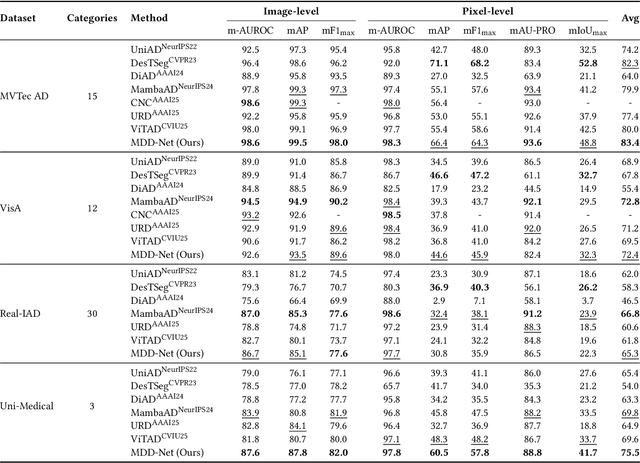
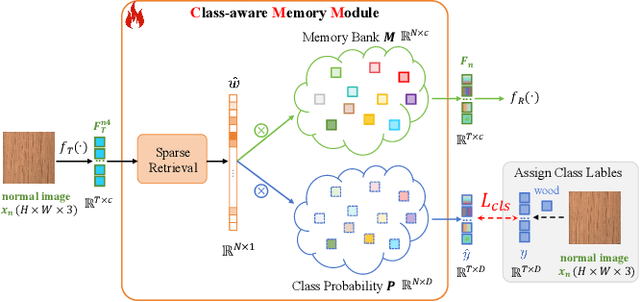
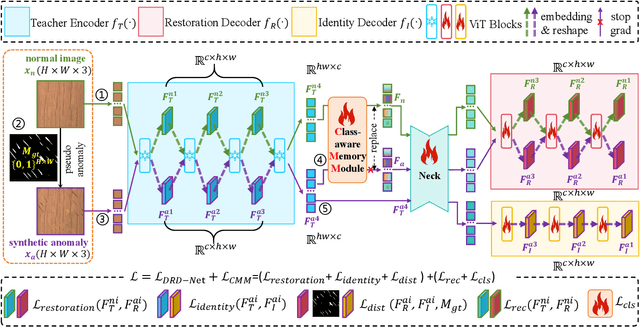
Recent advances in unsupervised anomaly detection (UAD) have shifted from single-class to multi-class scenarios. In such complex contexts, the increasing pattern diversity has brought two challenges to reconstruction-based approaches: (1) over-generalization: anomalies that are subtle or share compositional similarities with normal patterns may be reconstructed with high fidelity, making them difficult to distinguish from normal instances; and (2) insufficient normality reconstruction: complex normal features, such as intricate textures or fine-grained structures, may not be faithfully reconstructed due to the model's limited representational capacity, resulting in false positives. Existing methods typically focus on addressing the former, which unintentionally exacerbate the latter, resulting in inadequate representation of intricate normal patterns. To concurrently address these two challenges, we propose a Memory-augmented Dual-Decoder Networks (MDD-Net). This network includes two critical components: a Dual-Decoder Reverse Distillation Network (DRD-Net) and a Class-aware Memory Module (CMM). Specifically, the DRD-Net incorporates a restoration decoder designed to recover normal features from synthetic abnormal inputs and an identity decoder to reconstruct features that maintain the anomalous semantics. By exploiting the discrepancy between features produced by two decoders, our approach refines anomaly scores beyond the conventional encoder-decoder comparison paradigm, effectively reducing false positives and enhancing localization accuracy. Furthermore, the CMM explicitly encodes and preserves class-specific normal prototypes, actively steering the network away from anomaly reconstruction. Comprehensive experimental results across several benchmarks demonstrate the superior performance of our MDD-Net framework over current SoTA approaches in multi-class UAD tasks.
Vision-Amplified Semantic Entropy for Hallucination Detection in Medical Visual Question Answering
Mar 26, 2025Multimodal large language models (MLLMs) have demonstrated significant potential in medical Visual Question Answering (VQA). Yet, they remain prone to hallucinations-incorrect responses that contradict input images, posing substantial risks in clinical decision-making. Detecting these hallucinations is essential for establishing trust in MLLMs among clinicians and patients, thereby enabling their real-world adoption. Current hallucination detection methods, especially semantic entropy (SE), have demonstrated promising hallucination detection capacity for LLMs. However, adapting SE to medical MLLMs by incorporating visual perturbations presents a dilemma. Weak perturbations preserve image content and ensure clinical validity, but may be overlooked by medical MLLMs, which tend to over rely on language priors. In contrast, strong perturbations can distort essential diagnostic features, compromising clinical interpretation. To address this issue, we propose Vision Amplified Semantic Entropy (VASE), which incorporates weak image transformations and amplifies the impact of visual input, to improve hallucination detection in medical VQA. We first estimate the semantic predictive distribution under weak visual transformations to preserve clinical validity, and then amplify visual influence by contrasting this distribution with that derived from a distorted image. The entropy of the resulting distribution is estimated as VASE. Experiments on two medical open-ended VQA datasets demonstrate that VASE consistently outperforms existing hallucination detection methods.
Global Challenge for Safe and Secure LLMs Track 1
Nov 21, 2024


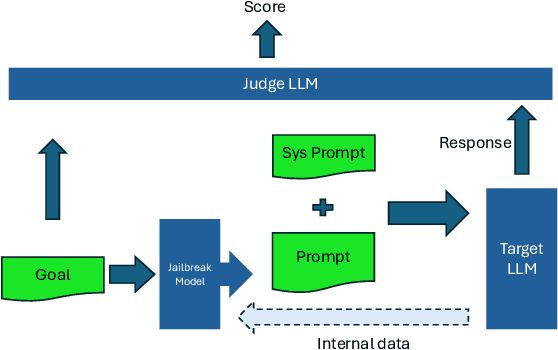
This paper introduces the Global Challenge for Safe and Secure Large Language Models (LLMs), a pioneering initiative organized by AI Singapore (AISG) and the CyberSG R&D Programme Office (CRPO) to foster the development of advanced defense mechanisms against automated jailbreaking attacks. With the increasing integration of LLMs in critical sectors such as healthcare, finance, and public administration, ensuring these models are resilient to adversarial attacks is vital for preventing misuse and upholding ethical standards. This competition focused on two distinct tracks designed to evaluate and enhance the robustness of LLM security frameworks. Track 1 tasked participants with developing automated methods to probe LLM vulnerabilities by eliciting undesirable responses, effectively testing the limits of existing safety protocols within LLMs. Participants were challenged to devise techniques that could bypass content safeguards across a diverse array of scenarios, from offensive language to misinformation and illegal activities. Through this process, Track 1 aimed to deepen the understanding of LLM vulnerabilities and provide insights for creating more resilient models.
A Survey and Evaluation of Adversarial Attacks for Object Detection
Aug 06, 2024Deep learning models excel in various computer vision tasks but are susceptible to adversarial examples-subtle perturbations in input data that lead to incorrect predictions. This vulnerability poses significant risks in safety-critical applications such as autonomous vehicles, security surveillance, and aircraft health monitoring. While numerous surveys focus on adversarial attacks in image classification, the literature on such attacks in object detection is limited. This paper offers a comprehensive taxonomy of adversarial attacks specific to object detection, reviews existing adversarial robustness evaluation metrics, and systematically assesses open-source attack methods and model robustness. Key observations are provided to enhance the understanding of attack effectiveness and corresponding countermeasures. Additionally, we identify crucial research challenges to guide future efforts in securing automated object detection systems.
Low-Resolution Self-Attention for Semantic Segmentation
Oct 08, 2023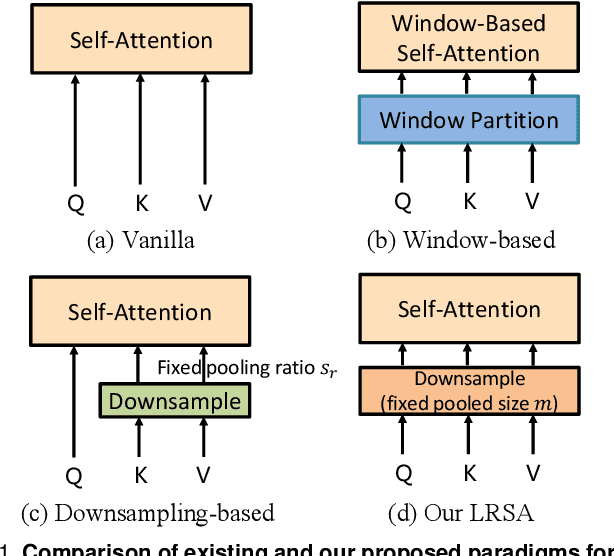
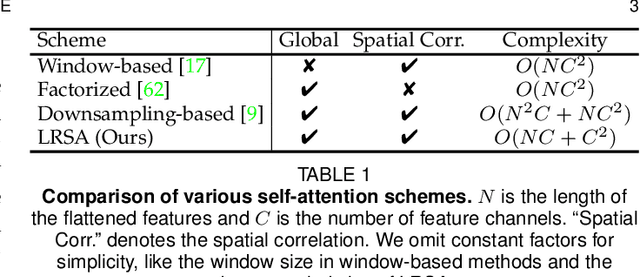
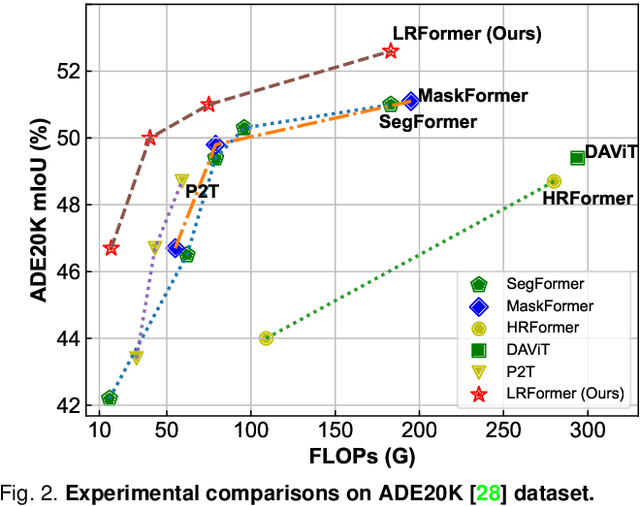

Semantic segmentation tasks naturally require high-resolution information for pixel-wise segmentation and global context information for class prediction. While existing vision transformers demonstrate promising performance, they often utilize high resolution context modeling, resulting in a computational bottleneck. In this work, we challenge conventional wisdom and introduce the Low-Resolution Self-Attention (LRSA) mechanism to capture global context at a significantly reduced computational cost. Our approach involves computing self-attention in a fixed low-resolution space regardless of the input image's resolution, with additional 3x3 depth-wise convolutions to capture fine details in the high-resolution space. We demonstrate the effectiveness of our LRSA approach by building the LRFormer, a vision transformer with an encoder-decoder structure. Extensive experiments on the ADE20K, COCO-Stuff, and Cityscapes datasets demonstrate that LRFormer outperforms state-of-the-art models. The code will be made available at https://github.com/yuhuan-wu/LRFormer.
Efficient Sharpness-aware Minimization for Improved Training of Neural Networks
Oct 07, 2021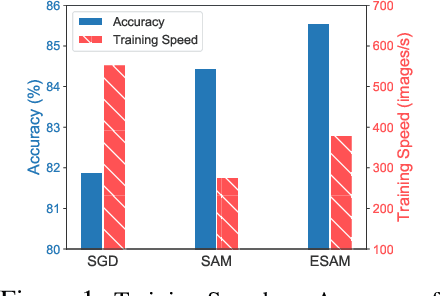
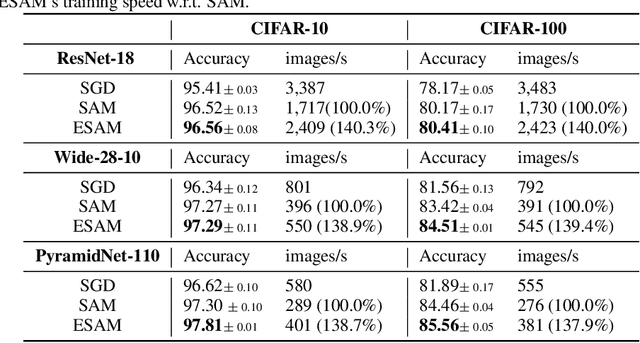
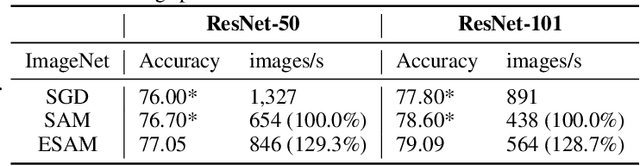
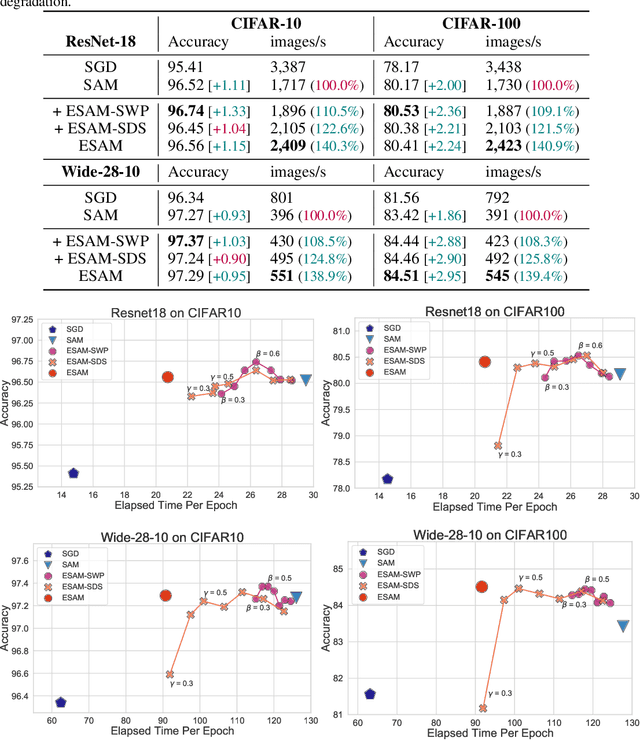
Overparametrized Deep Neural Networks (DNNs) often achieve astounding performances, but may potentially result in severe generalization error. Recently, the relation between the sharpness of the loss landscape and the generalization error has been established by Foret et al. (2020), in which the Sharpness Aware Minimizer (SAM) was proposed to mitigate the degradation of the generalization. Unfortunately, SAM s computational cost is roughly double that of base optimizers, such as Stochastic Gradient Descent (SGD). This paper thus proposes Efficient Sharpness Aware Minimizer (ESAM), which boosts SAM s efficiency at no cost to its generalization performance. ESAM includes two novel and efficient training strategies-StochasticWeight Perturbation and Sharpness-Sensitive Data Selection. In the former, the sharpness measure is approximated by perturbing a stochastically chosen set of weights in each iteration; in the latter, the SAM loss is optimized using only a judiciously selected subset of data that is sensitive to the sharpness. We provide theoretical explanations as to why these strategies perform well. We also show, via extensive experiments on the CIFAR and ImageNet datasets, that ESAM enhances the efficiency over SAM from requiring 100% extra computations to 40% vis-a-vis base optimizers, while test accuracies are preserved or even improved.
Parallel Attention Network with Sequence Matching for Video Grounding
May 18, 2021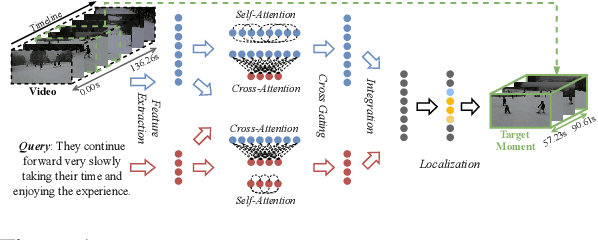
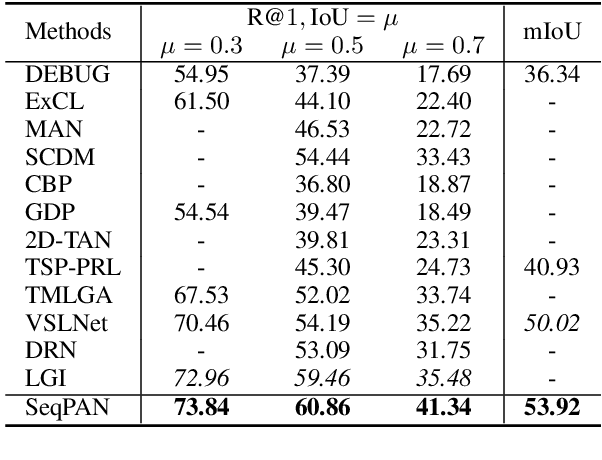

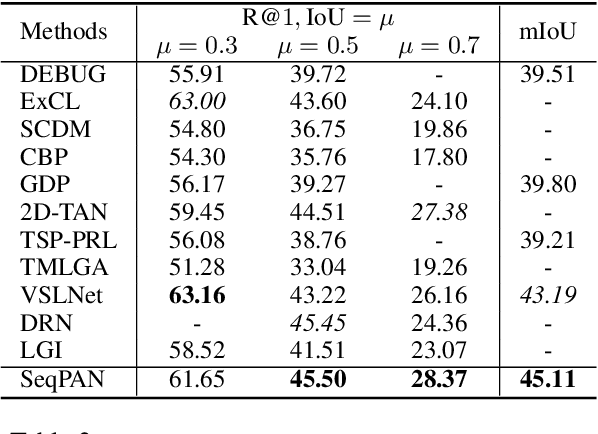
Given a video, video grounding aims to retrieve a temporal moment that semantically corresponds to a language query. In this work, we propose a Parallel Attention Network with Sequence matching (SeqPAN) to address the challenges in this task: multi-modal representation learning, and target moment boundary prediction. We design a self-guided parallel attention module to effectively capture self-modal contexts and cross-modal attentive information between video and text. Inspired by sequence labeling tasks in natural language processing, we split the ground truth moment into begin, inside, and end regions. We then propose a sequence matching strategy to guide start/end boundary predictions using region labels. Experimental results on three datasets show that SeqPAN is superior to state-of-the-art methods. Furthermore, the effectiveness of the self-guided parallel attention module and the sequence matching module is verified.
Video Corpus Moment Retrieval with Contrastive Learning
May 13, 2021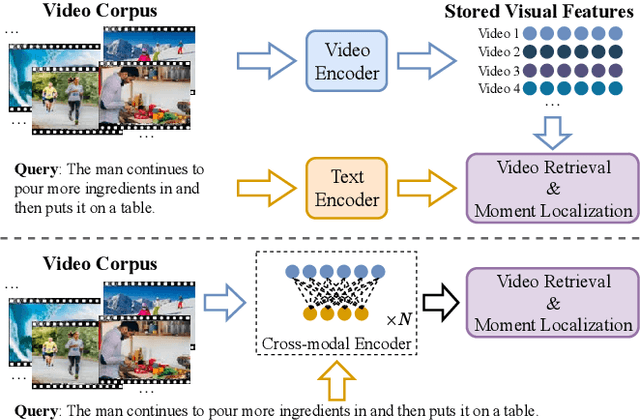
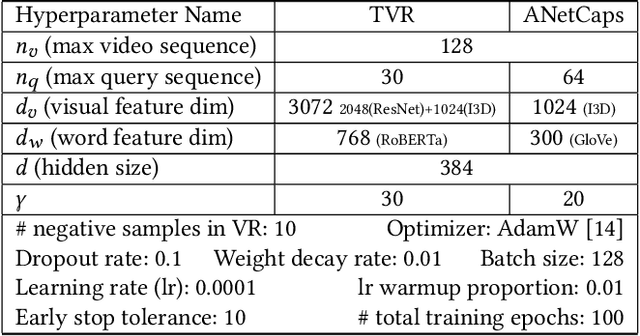
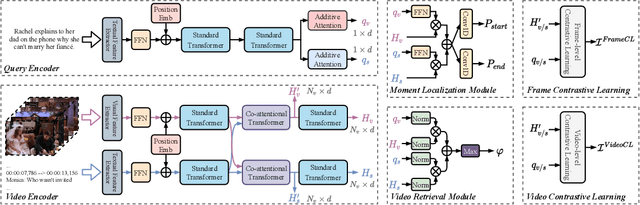
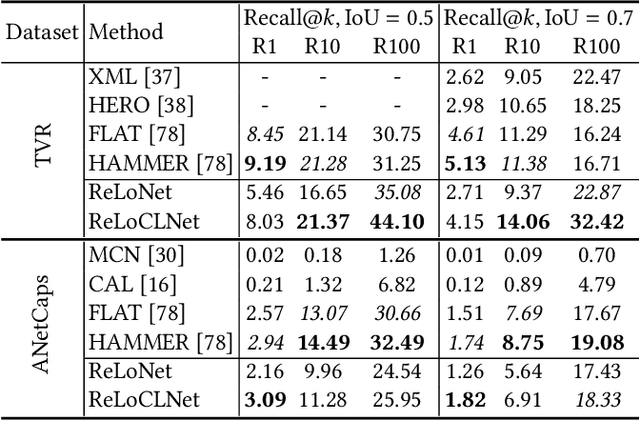
Given a collection of untrimmed and unsegmented videos, video corpus moment retrieval (VCMR) is to retrieve a temporal moment (i.e., a fraction of a video) that semantically corresponds to a given text query. As video and text are from two distinct feature spaces, there are two general approaches to address VCMR: (i) to separately encode each modality representations, then align the two modality representations for query processing, and (ii) to adopt fine-grained cross-modal interaction to learn multi-modal representations for query processing. While the second approach often leads to better retrieval accuracy, the first approach is far more efficient. In this paper, we propose a Retrieval and Localization Network with Contrastive Learning (ReLoCLNet) for VCMR. We adopt the first approach and introduce two contrastive learning objectives to refine video encoder and text encoder to learn video and text representations separately but with better alignment for VCMR. The video contrastive learning (VideoCL) is to maximize mutual information between query and candidate video at video-level. The frame contrastive learning (FrameCL) aims to highlight the moment region corresponds to the query at frame-level, within a video. Experimental results show that, although ReLoCLNet encodes text and video separately for efficiency, its retrieval accuracy is comparable with baselines adopting cross-modal interaction learning.