 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Efficient Semantic Segmentation: Learning Offsets for Better Spatial and Class Feature Alignment
Aug 12, 2025Semantic segmentation is fundamental to vision systems requiring pixel-level scene understanding, yet deploying it on resource-constrained devices demands efficient architectures. Although existing methods achieve real-time inference through lightweight designs, we reveal their inherent limitation: misalignment between class representations and image features caused by a per-pixel classification paradigm. With experimental analysis, we find that this paradigm results in a highly challenging assumption for efficient scenarios: Image pixel features should not vary for the same category in different images. To address this dilemma, we propose a coupled dual-branch offset learning paradigm that explicitly learns feature and class offsets to dynamically refine both class representations and spatial image features. Based on the proposed paradigm, we construct an efficient semantic segmentation network, OffSeg. Notably, the offset learning paradigm can be adopted to existing methods with no additional architectural changes. Extensive experiments on four datasets, including ADE20K, Cityscapes, COCO-Stuff-164K, and Pascal Context, demonstrate consistent improvements with negligible parameters. For instance, on the ADE20K dataset, our proposed offset learning paradigm improves SegFormer-B0, SegNeXt-T, and Mask2Former-Tiny by 2.7%, 1.9%, and 2.6% mIoU, respectively, with only 0.1-0.2M additional parameters required.
Low-Resolution Self-Attention for Semantic Segmentation
Oct 08, 2023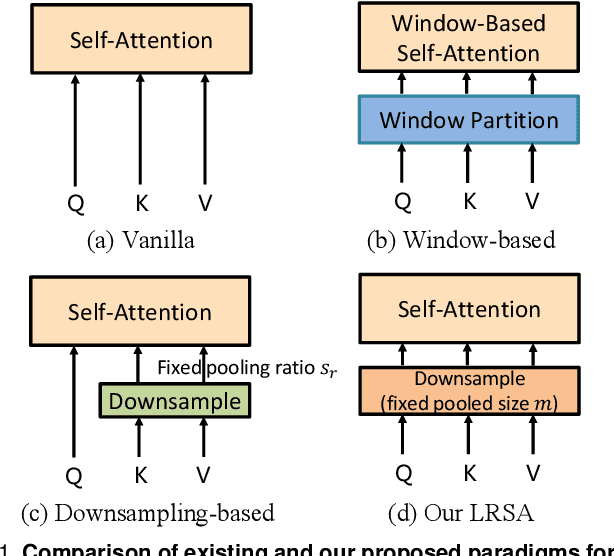
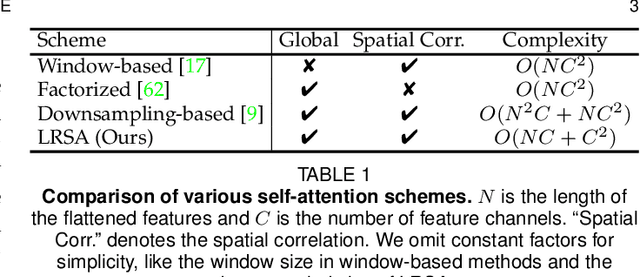
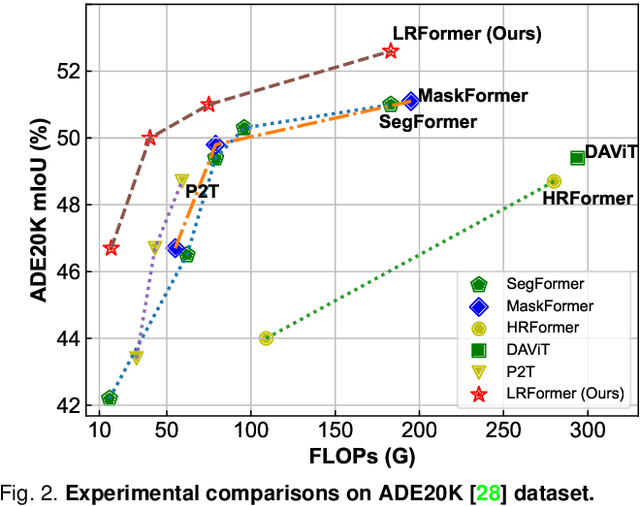

Semantic segmentation tasks naturally require high-resolution information for pixel-wise segmentation and global context information for class prediction. While existing vision transformers demonstrate promising performance, they often utilize high resolution context modeling, resulting in a computational bottleneck. In this work, we challenge conventional wisdom and introduce the Low-Resolution Self-Attention (LRSA) mechanism to capture global context at a significantly reduced computational cost. Our approach involves computing self-attention in a fixed low-resolution space regardless of the input image's resolution, with additional 3x3 depth-wise convolutions to capture fine details in the high-resolution space. We demonstrate the effectiveness of our LRSA approach by building the LRFormer, a vision transformer with an encoder-decoder structure. Extensive experiments on the ADE20K, COCO-Stuff, and Cityscapes datasets demonstrate that LRFormer outperforms state-of-the-art models. The code will be made available at https://github.com/yuhuan-wu/LRFormer.
Revisiting Computer-Aided Tuberculosis Diagnosis
Jul 06, 2023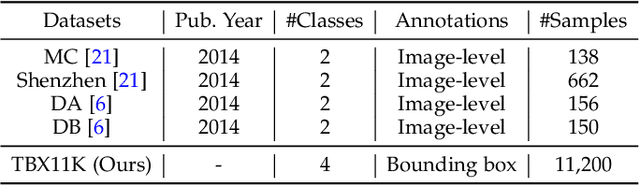
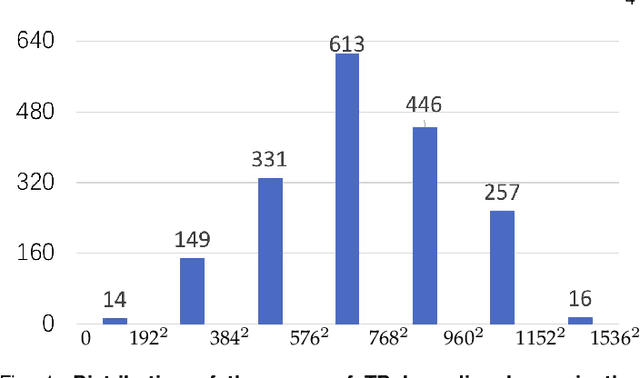
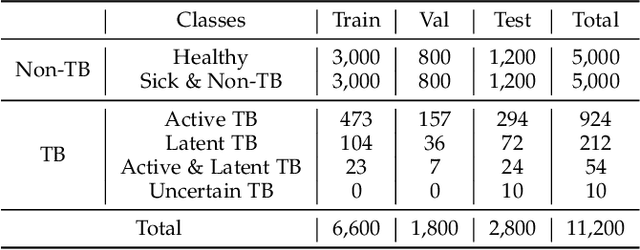
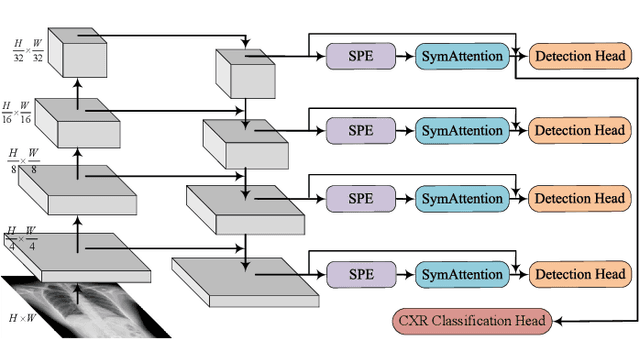
Tuberculosis (TB) is a major global health threat, causing millions of deaths annually. Although early diagnosis and treatment can greatly improve the chances of survival, it remains a major challenge, especially in developing countries. Recently, computer-aided tuberculosis diagnosis (CTD) using deep learning has shown promise, but progress is hindered by limited training data. To address this, we establish a large-scale dataset, namely the Tuberculosis X-ray (TBX11K) dataset, which contains 11,200 chest X-ray (CXR) images with corresponding bounding box annotations for TB areas. This dataset enables the training of sophisticated detectors for high-quality CTD. Furthermore, we propose a strong baseline, SymFormer, for simultaneous CXR image classification and TB infection area detection. SymFormer incorporates Symmetric Search Attention (SymAttention) to tackle the bilateral symmetry property of CXR images for learning discriminative features. Since CXR images may not strictly adhere to the bilateral symmetry property, we also propose Symmetric Positional Encoding (SPE) to facilitate SymAttention through feature recalibration. To promote future research on CTD, we build a benchmark by introducing evaluation metrics, evaluating baseline models reformed from existing detectors, and running an online challenge. Experiments show that SymFormer achieves state-of-the-art performance on the TBX11K dataset. The data, code, and models will be released.