 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedQ-Bench: Evaluating and Exploring Medical Image Quality Assessment Abilities in MLLMs
Oct 02, 2025
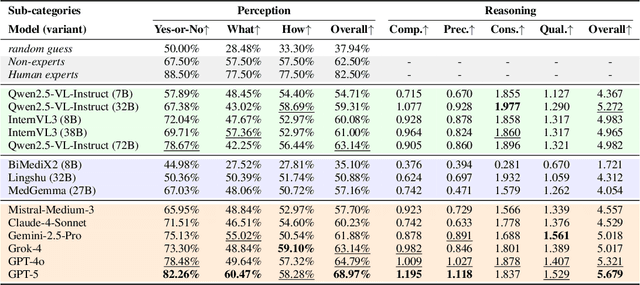
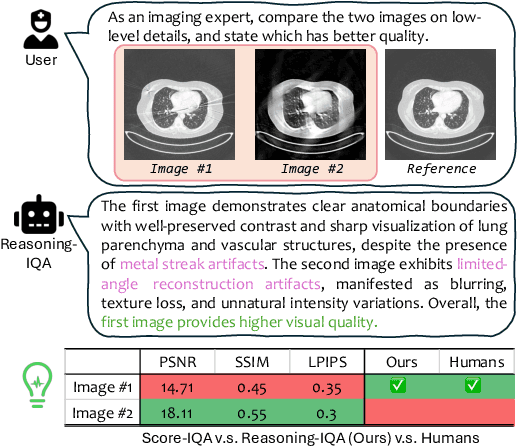

Medical Image Quality Assessment (IQA) serves as the first-mile safety gate for clinical AI, yet existing approaches remain constrained by scalar, score-based metrics and fail to reflect the descriptive, human-like reasoning process central to expert evaluation. To address this gap, we introduce MedQ-Bench, a comprehensive benchmark that establishes a perception-reasoning paradigm for language-based evaluation of medical image quality with Multi-modal Large Language Models (MLLMs). MedQ-Bench defines two complementary tasks: (1) MedQ-Perception, which probes low-level perceptual capability via human-curated questions on fundamental visual attributes; and (2) MedQ-Reasoning, encompassing both no-reference and comparison reasoning tasks, aligning model evaluation with human-like reasoning on image quality. The benchmark spans five imaging modalities and over forty quality attributes, totaling 2,600 perceptual queries and 708 reasoning assessments, covering diverse image sources including authentic clinical acquisitions, images with simulated degradations via physics-based reconstructions, and AI-generated images. To evaluate reasoning ability, we propose a multi-dimensional judging protocol that assesses model outputs along four complementary axes. We further conduct rigorous human-AI alignment validation by comparing LLM-based judgement with radiologists. Our evaluation of 14 state-of-the-art MLLMs demonstrates that models exhibit preliminary but unstable perceptual and reasoning skills, with insufficient accuracy for reliable clinical use. These findings highlight the need for targeted optimization of MLLMs in medical IQA. We hope that MedQ-Bench will catalyze further exploration and unlock the untapped potential of MLLMs for medical image quality evaluation.
Revisiting Efficient Semantic Segmentation: Learning Offsets for Better Spatial and Class Feature Alignment
Aug 12, 2025Semantic segmentation is fundamental to vision systems requiring pixel-level scene understanding, yet deploying it on resource-constrained devices demands efficient architectures. Although existing methods achieve real-time inference through lightweight designs, we reveal their inherent limitation: misalignment between class representations and image features caused by a per-pixel classification paradigm. With experimental analysis, we find that this paradigm results in a highly challenging assumption for efficient scenarios: Image pixel features should not vary for the same category in different images. To address this dilemma, we propose a coupled dual-branch offset learning paradigm that explicitly learns feature and class offsets to dynamically refine both class representations and spatial image features. Based on the proposed paradigm, we construct an efficient semantic segmentation network, OffSeg. Notably, the offset learning paradigm can be adopted to existing methods with no additional architectural changes. Extensive experiments on four datasets, including ADE20K, Cityscapes, COCO-Stuff-164K, and Pascal Context, demonstrate consistent improvements with negligible parameters. For instance, on the ADE20K dataset, our proposed offset learning paradigm improves SegFormer-B0, SegNeXt-T, and Mask2Former-Tiny by 2.7%, 1.9%, and 2.6% mIoU, respectively, with only 0.1-0.2M additional parameters required.
SM3Det: A Unified Model for Multi-Modal Remote Sensing Object Detection
Dec 30, 2024With the rapid advancement of remote sensing technology, high-resolution multi-modal imagery is now more widely accessible. Conventional Object detection models are trained on a single dataset, often restricted to a specific imaging modality and annotation format. However, such an approach overlooks the valuable shared knowledge across multi-modalities and limits the model's applicability in more versatile scenarios. This paper introduces a new task called Multi-Modal Datasets and Multi-Task Object Detection (M2Det) for remote sensing, designed to accurately detect horizontal or oriented objects from any sensor modality. This task poses challenges due to 1) the trade-offs involved in managing multi-modal modelling and 2) the complexities of multi-task optimization. To address these, we establish a benchmark dataset and propose a unified model, SM3Det (Single Model for Multi-Modal datasets and Multi-Task object Detection). SM3Det leverages a grid-level sparse MoE backbone to enable joint knowledge learning while preserving distinct feature representations for different modalities. Furthermore, it integrates a consistency and synchronization optimization strategy using dynamic learning rate adjustment, allowing it to effectively handle varying levels of learning difficulty across modalities and tasks. Extensive experiments demonstrate SM3Det's effectiveness and generalizability, consistently outperforming specialized models on individual datasets. The code is available at https://github.com/zcablii/SM3Det.
MaskCLIP++: A Mask-Based CLIP Fine-tuning Framework for Open-Vocabulary Image Segmentation
Dec 16, 2024



Open-vocabulary image segmentation has been advanced through the synergy between mask generators and vision-language models like Contrastive Language-Image Pre-training (CLIP). Previous approaches focus on generating masks while aligning mask features with text embeddings during training. In this paper, we observe that relying on generated low-quality masks can weaken the alignment of vision and language in regional representations. This motivates us to present a new fine-tuning framework, named MaskCLIP++, which uses ground-truth masks instead of generated masks to enhance the mask classification capability of CLIP. Due to the limited diversity of image segmentation datasets with mask annotations, we propose incorporating a consistency alignment constraint during fine-tuning, which alleviates categorical bias toward the fine-tuning dataset. After low-cost fine-tuning, combining with the mask generator in previous state-of-the-art mask-based open vocabulary segmentation methods, we achieve performance improvements of +1.7, +2.3, +2.1, +3.1, and +0.3 mIoU on the A-847, PC-459, A-150, PC-59, and PAS-20 datasets, respectively.
DenseVLM: A Retrieval and Decoupled Alignment Framework for Open-Vocabulary Dense Prediction
Dec 09, 2024



Pre-trained vision-language models (VLMs), such as CLIP, have demonstrated impressive zero-shot recognition capability, but still underperform in dense prediction tasks. Self-distillation recently is emerging as a promising approach for fine-tuning VLMs to better adapt to local regions without requiring extensive annotations. However, previous state-of-the-art approaches often suffer from significant `foreground bias', where models tend to wrongly identify background regions as foreground objects. To alleviate this issue, we propose DenseVLM, a framework designed to learn unbiased region-language alignment from powerful pre-trained VLM representations. By leveraging the pre-trained VLM to retrieve categories for unlabeled regions, DenseVLM effectively decouples the interference between foreground and background region features, ensuring that each region is accurately aligned with its corresponding category. We show that DenseVLM can be seamlessly integrated into open-vocabulary object detection and image segmentation tasks, leading to notable performance improvements. Furthermore, it exhibits promising zero-shot scalability when training on more extensive and diverse datasets.
PR-MIM: Delving Deeper into Partial Reconstruction in Masked Image Modeling
Nov 24, 2024Masked image modeling has achieved great success in learning representations but is limited by the huge computational costs. One cost-saving strategy makes the decoder reconstruct only a subset of masked tokens and throw the others, and we refer to this method as partial reconstruction. However, it also degrades the representation quality. Previous methods mitigate this issue by throwing tokens with minimal information using temporal redundancy inaccessible for static images or attention maps that incur extra costs and complexity. To address these limitations, we propose a progressive reconstruction strategy and a furthest sampling strategy to reconstruct those thrown tokens in an extremely lightweight way instead of completely abandoning them. This approach involves all masked tokens in supervision to ensure adequate pre-training, while maintaining the cost-reduction benefits of partial reconstruction. We validate the effectiveness of the proposed method across various existing frameworks. For example, when throwing 50% patches, we can achieve lossless performance of the ViT-B/16 while saving 28% FLOPs and 36% memory usage compared to standard MAE. Our source code will be made publicly available
Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero-Shot Semantic Segmentation
Jun 02, 2024



Pre-trained vision-language models, e.g., CLIP, have been successfully applied to zero-shot semantic segmentation. Existing CLIP-based approaches primarily utilize visual features from the last layer to align with text embeddings, while they neglect the crucial information in intermediate layers that contain rich object details. However, we find that directly aggregating the multi-level visual features weakens the zero-shot ability for novel classes. The large differences between the visual features from different layers make these features hard to align well with the text embeddings. We resolve this problem by introducing a series of independent decoders to align the multi-level visual features with the text embeddings in a cascaded way, forming a novel but simple framework named Cascade-CLIP. Our Cascade-CLIP is flexible and can be easily applied to existing zero-shot semantic segmentation methods. Experimental results show that our simple Cascade-CLIP achieves superior zero-shot performance on segmentation benchmarks, like COCO-Stuff, Pascal-VOC, and Pascal-Context. Our code is available at: https://github.com/HVision-NKU/Cascade-CLIP
A Decoupled Spatio-Temporal Framework for Skeleton-based Action Segmentation
Dec 10, 2023



Effectively modeling discriminative spatio-temporal information is essential for segmenting activities in long action sequences. However, we observe that existing methods are limited in weak spatio-temporal modeling capability due to two forms of decoupled modeling: (i) cascaded interaction couples spatial and temporal modeling, which over-smooths motion modeling over the long sequence, and (ii) joint-shared temporal modeling adopts shared weights to model each joint, ignoring the distinct motion patterns of different joints. We propose a Decoupled Spatio-Temporal Framework (DeST) to address the above issues. Firstly, we decouple the cascaded spatio-temporal interaction to avoid stacking multiple spatio-temporal blocks, while achieving sufficient spatio-temporal interaction. Specifically, DeST performs once unified spatial modeling and divides the spatial features into different groups of subfeatures, which then adaptively interact with temporal features from different layers. Since the different sub-features contain distinct spatial semantics, the model could learn the optimal interaction pattern at each layer. Meanwhile, inspired by the fact that different joints move at different speeds, we propose joint-decoupled temporal modeling, which employs independent trainable weights to capture distinctive temporal features of each joint. On four large-scale benchmarks of different scenes, DeST significantly outperforms current state-of-the-art methods with less computational complexity.
TeMO: Towards Text-Driven 3D Stylization for Multi-Object Meshes
Dec 07, 2023Recent progress in the text-driven 3D stylization of a single object has been considerably promoted by CLIP-based methods. However, the stylization of multi-object 3D scenes is still impeded in that the image-text pairs used for pre-training CLIP mostly consist of an object. Meanwhile, the local details of multiple objects may be susceptible to omission due to the existing supervision manner primarily relying on coarse-grained contrast of image-text pairs. To overcome these challenges, we present a novel framework, dubbed TeMO, to parse multi-object 3D scenes and edit their styles under the contrast supervision at multiple levels. We first propose a Decoupled Graph Attention (DGA) module to distinguishably reinforce the features of 3D surface points. Particularly, a cross-modal graph is constructed to align the object points accurately and noun phrases decoupled from the 3D mesh and textual description. Then, we develop a Cross-Grained Contrast (CGC) supervision system, where a fine-grained loss between the words in the textual description and the randomly rendered images are constructed to complement the coarse-grained loss. Extensive experiments show that our method can synthesize high-quality stylized content and outperform the existing methods over a wide range of multi-object 3D meshes. Our code and results will be made publicly available
End-to-End Streaming Video Temporal Action Segmentation with Reinforce Learning
Sep 27, 2023Temporal Action Segmentation (TAS) from video is a kind of frame recognition task for long video with multiple action classes. As an video understanding task for long videos, current methods typically combine multi-modality action recognition models with temporal models to convert feature sequences to label sequences. This approach can only be applied to offline scenarios, which severely limits the TAS application. Therefore, this paper proposes an end-to-end Streaming Video Temporal Action Segmentation with Reinforce Learning (SVTAS-RL). The end-to-end SVTAS which regard TAS as an action segment clustering task can expand the application scenarios of TAS; and RL is used to alleviate the problem of inconsistent optimization objective and direction. Through extensive experiments, the SVTAS-RL model achieves a competitive performance to the state-of-the-art model of TAS on multiple datasets, and shows greater advantages on the ultra-long video dataset EGTEA. This indicates that our method can replace all current TAS models end-to-end and SVTAS-RL is more suitable for long video TAS. Code is availabel at https://github.com/Thinksky5124/SVTAS.