 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Streaming Video Temporal Action Segmentation with Reinforce Learning
Sep 27, 2023Temporal Action Segmentation (TAS) from video is a kind of frame recognition task for long video with multiple action classes. As an video understanding task for long videos, current methods typically combine multi-modality action recognition models with temporal models to convert feature sequences to label sequences. This approach can only be applied to offline scenarios, which severely limits the TAS application. Therefore, this paper proposes an end-to-end Streaming Video Temporal Action Segmentation with Reinforce Learning (SVTAS-RL). The end-to-end SVTAS which regard TAS as an action segment clustering task can expand the application scenarios of TAS; and RL is used to alleviate the problem of inconsistent optimization objective and direction. Through extensive experiments, the SVTAS-RL model achieves a competitive performance to the state-of-the-art model of TAS on multiple datasets, and shows greater advantages on the ultra-long video dataset EGTEA. This indicates that our method can replace all current TAS models end-to-end and SVTAS-RL is more suitable for long video TAS. Code is availabel at https://github.com/Thinksky5124/SVTAS.
Streaming Video Temporal Action Segmentation In Real Time
Sep 28, 2022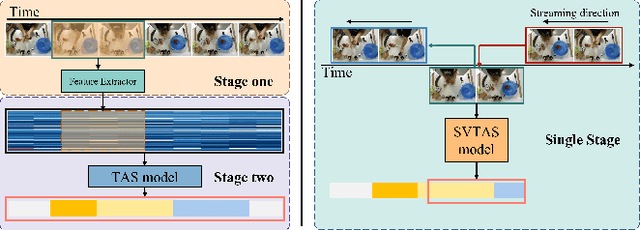
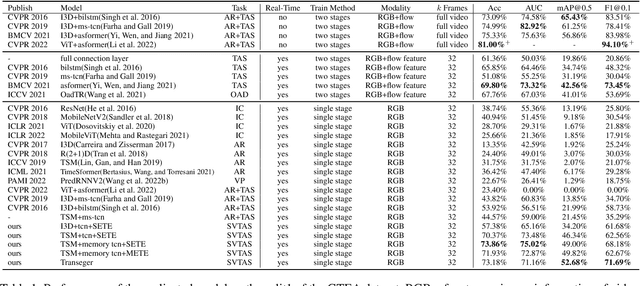
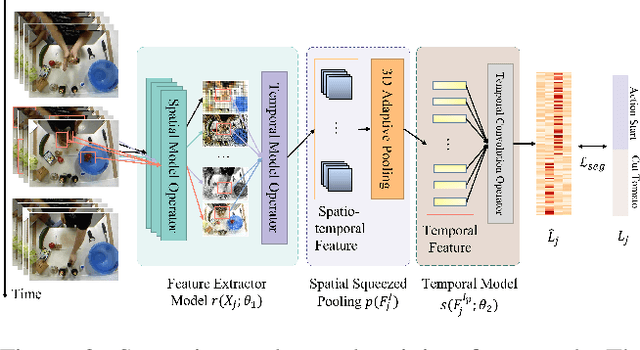
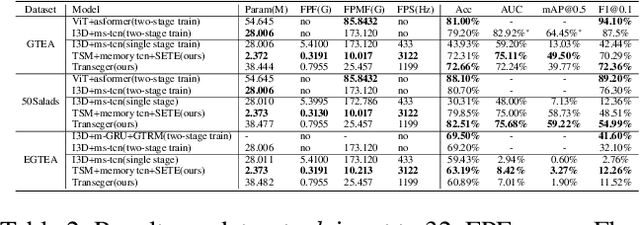
Temporal action segmentation (TAS) is a critical step toward long-term video understanding. Recent studies follow a pattern that builds models based on features instead of raw video picture information. However, we claim those models are trained complicatedly and limit application scenarios. It is hard for them to segment human actions of video in real time because they must work after the full video features are extracted. As the real-time action segmentation task is different from TAS task, we define it as streaming video real-time temporal action segmentation (SVTAS) task. In this paper, we propose a real-time end-to-end multi-modality model for SVTAS task. More specifically, under the circumstances that we cannot get any future information, we segment the current human action of streaming video chunk in real time. Furthermore, the model we propose combines the last steaming video chunk feature extracted by language model with the current image feature extracted by image model to improve the quantity of real-time temporal action segmentation. To the best of our knowledge, it is the first multi-modality real-time temporal action segmentation model. Under the same evaluation criteria as full video temporal action segmentation, our model segments human action in real time with less than 40% of state-of-the-art model computation and achieves 90% of the accuracy of the full video state-of-the-art model.