 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Video Temporal Action Segmentation In Real Time
Sep 28, 2022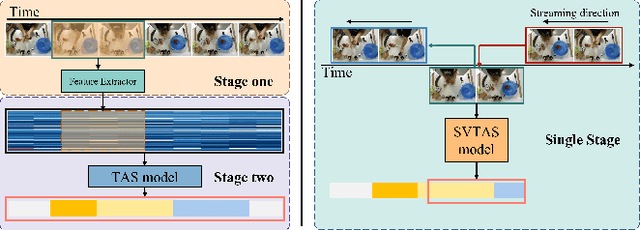
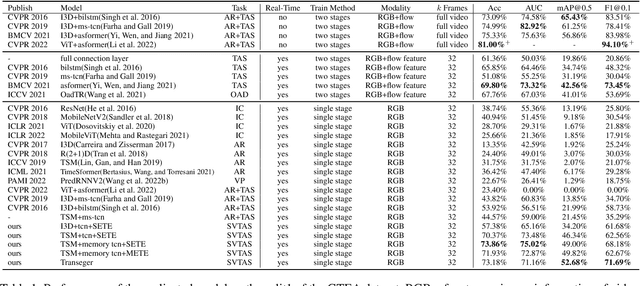
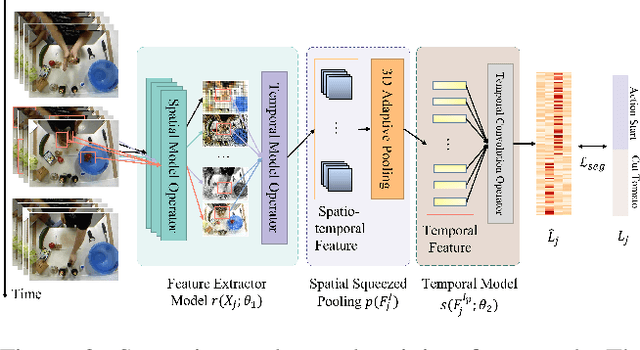
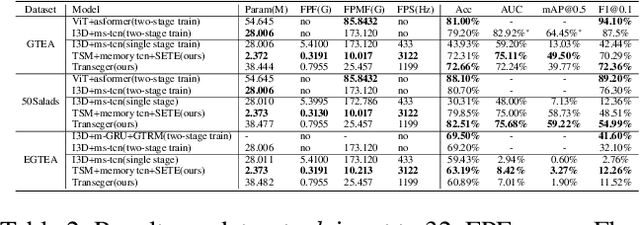
Temporal action segmentation (TAS) is a critical step toward long-term video understanding. Recent studies follow a pattern that builds models based on features instead of raw video picture information. However, we claim those models are trained complicatedly and limit application scenarios. It is hard for them to segment human actions of video in real time because they must work after the full video features are extracted. As the real-time action segmentation task is different from TAS task, we define it as streaming video real-time temporal action segmentation (SVTAS) task. In this paper, we propose a real-time end-to-end multi-modality model for SVTAS task. More specifically, under the circumstances that we cannot get any future information, we segment the current human action of streaming video chunk in real time. Furthermore, the model we propose combines the last steaming video chunk feature extracted by language model with the current image feature extracted by image model to improve the quantity of real-time temporal action segmentation. To the best of our knowledge, it is the first multi-modality real-time temporal action segmentation model. Under the same evaluation criteria as full video temporal action segmentation, our model segments human action in real time with less than 40% of state-of-the-art model computation and achieves 90% of the accuracy of the full video state-of-the-art model.
FSD-10: A Dataset for Competitive Sports Content Analysis
Feb 09, 2020

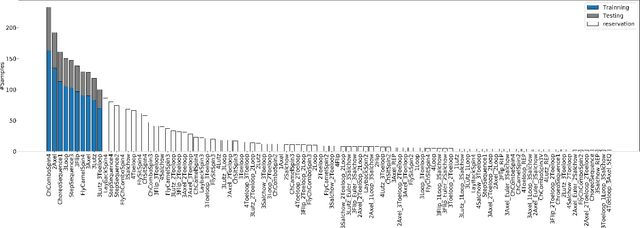
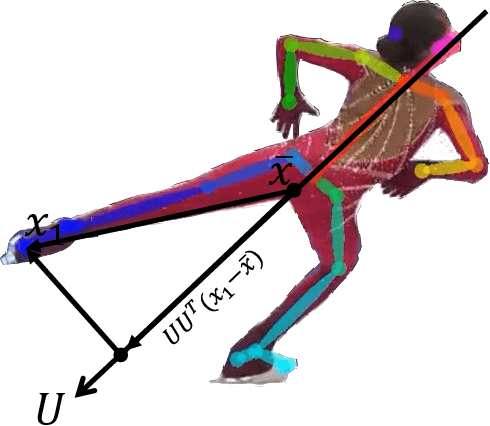
Action recognition is an important and challenging problem in video analysis. Although the past decade has witnessed progress in action recognition with the development of deep learning, such process has been slow in competitive sports content analysis. To promote the research on action recognition from competitive sports video clips, we introduce a Figure Skating Dataset (FSD-10) for finegrained sports content analysis. To this end, we collect 1484 clips from the worldwide figure skating championships in 2017-2018, which consist of 10 different actions in men/ladies programs. Each clip is at a rate of 30 frames per second with resolution 1080 $\times$ 720. These clips are then annotated by experts in type, grade of execution, skater info, .etc. To build a baseline for action recognition in figure skating, we evaluate state-of-the-art action recognition methods on FSD-10. Motivated by the idea that domain knowledge is of great concern in sports field, we propose a keyframe based temporal segment network (KTSN) for classification and achieve remarkable performance. Experimental results demonstrate that FSD-10 is an ideal dataset for benchmarking action recognition algorithms, as it requires to accurately extract action motions rather than action poses. We hope FSD-10, which is designed to have a large collection of finegrained actions, can serve as a new challenge to develop more robust and advanced action recognition models.