 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTennisExpert: Towards Expert-Level Analytical Sports Video Understanding
Mar 17, 2026Tennis is one of the most widely followed sports, generating extensive broadcast footage with strong potential for professional analysis, automated coaching, and real-time commentary. However, automatic tennis understanding remains underexplored due to two key challenges: (1) the lack of large-scale benchmarks with fine-grained annotations and expert-level commentary, and (2) the difficulty of building accurate yet efficient multimodal systems suitable for real-time deployment. To address these challenges, we introduce TennisVL, a large-scale tennis benchmark comprising over 200 professional matches (471.9 hours) and 40,000+ rally-level clips. Unlike existing commentary datasets that focus on descriptive play-by-play narration, TennisVL emphasizes expert analytical commentary capturing tactical reasoning, player decisions, and match momentum. Furthermore, we propose TennisExpert, a multimodal tennis understanding framework that integrates a video semantic parser with a memory-augmented model built on Qwen3-VL-8B. The parser extracts key match elements (e.g., scores, shot sequences, ball bounces, and player locations), while hierarchical memory modules capture both short- and long-term temporal context. Experiments show that TennisExpert consistently outperforms strong proprietary baselines, including GPT-5, Gemini, and Claude, and demonstrates improved ability to capture tactical context and match dynamics. Our dataset and code are publicly available at https://github.com/LZYAndy/TennisExpert.
HiMemVLN: Enhancing Reliability of Open-Source Zero-Shot Vision-and-Language Navigation with Hierarchical Memory System
Mar 16, 2026LLM-based agents have demonstrated impressive zero-shot performance in vision-language navigation (VLN) tasks. However, most zero-shot methods primarily rely on closed-source LLMs as navigators, which face challenges related to high token costs and potential data leakage risks. Recent efforts have attempted to address this by using open-source LLMs combined with a spatiotemporal CoT framework, but they still fall far short compared to closed-source models. In this work, we identify a critical issue, Navigation Amnesia, through a detailed analysis of the navigation process. This issue leads to navigation failures and amplifies the gap between open-source and closed-source methods. To address this, we propose HiMemVLN, which incorporates a Hierarchical Memory System into a multimodal large model to enhance visual perception recall and long-term localization, mitigating the amnesia issue and improving the agent's navigation performance. Extensive experiments in both simulated and real-world environments demonstrate that HiMemVLN achieves nearly twice the performance of the open-source state-of-the-art method. The code is available at https://github.com/lvkailin0118/HiMemVLN.
SSL-SSAW: Self-Supervised Learning with Sigmoid Self-Attention Weighting for Question-Based Sign Language Translation
Sep 17, 2025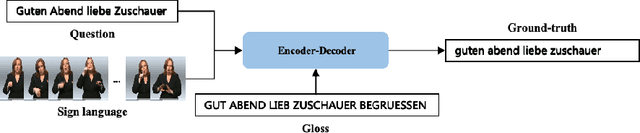
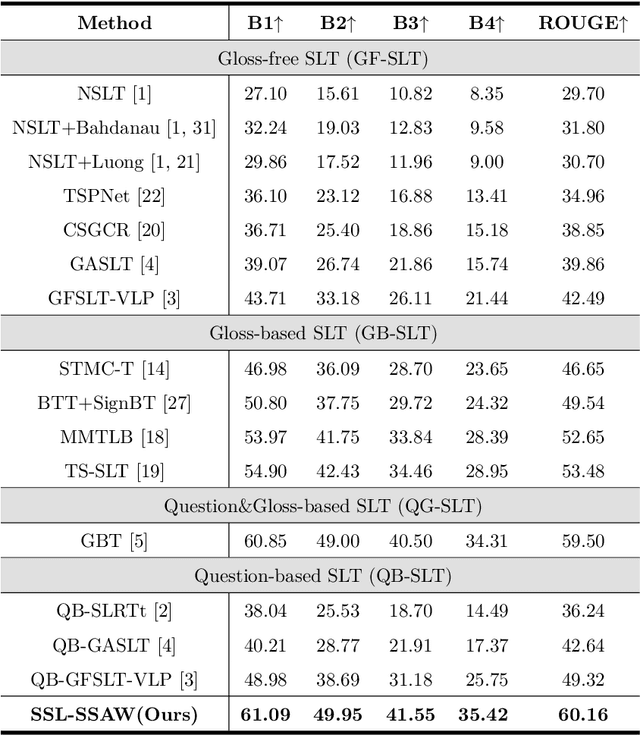
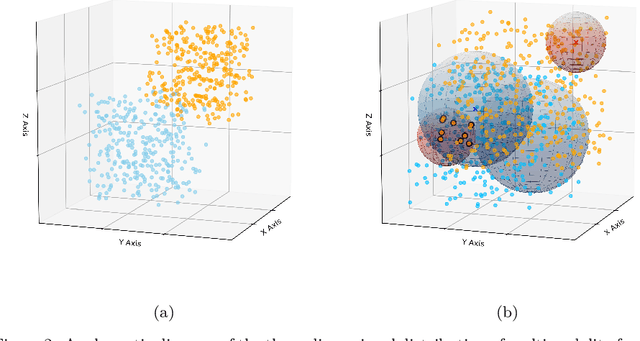
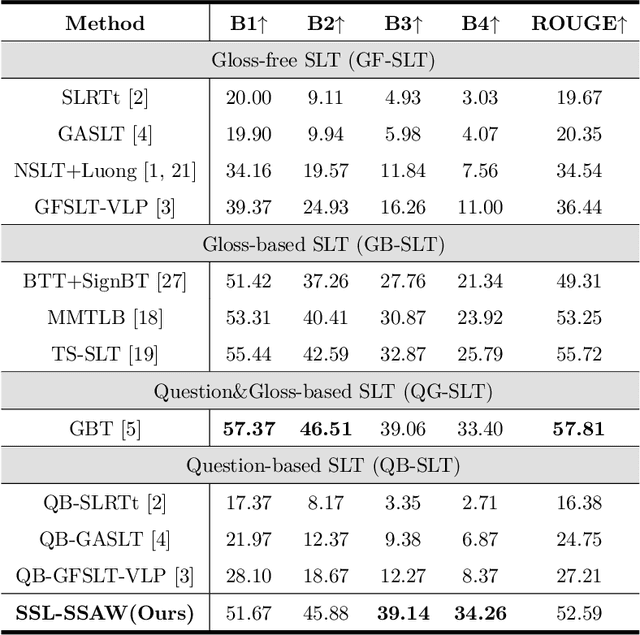
Sign Language Translation (SLT) bridges the communication gap between deaf people and hearing people, where dialogue provides crucial contextual cues to aid in translation. Building on this foundational concept, this paper proposes Question-based Sign Language Translation (QB-SLT), a novel task that explores the efficient integration of dialogue. Unlike gloss (sign language transcription) annotations, dialogue naturally occurs in communication and is easier to annotate. The key challenge lies in aligning multimodality features while leveraging the context of the question to improve translation. To address this issue, we propose a cross-modality Self-supervised Learning with Sigmoid Self-attention Weighting (SSL-SSAW) fusion method for sign language translation. Specifically, we employ contrastive learning to align multimodality features in QB-SLT, then introduce a Sigmoid Self-attention Weighting (SSAW) module for adaptive feature extraction from question and sign language sequences. Additionally, we leverage available question text through self-supervised learning to enhance representation and translation capabilities. We evaluated our approach on newly constructed CSL-Daily-QA and PHOENIX-2014T-QA datasets, where SSL-SSAW achieved SOTA performance. Notably, easily accessible question assistance can achieve or even surpass the performance of gloss assistance. Furthermore, visualization results demonstrate the effectiveness of incorporating dialogue in improving translation quality.
Adversarial Fair Multi-View Clustering
Aug 06, 2025Cluster analysis is a fundamental problem in data mining and machine learning. In recent years, multi-view clustering has attracted increasing attention due to its ability to integrate complementary information from multiple views. However, existing methods primarily focus on clustering performance, while fairness-a critical concern in human-centered applications-has been largely overlooked. Although recent studies have explored group fairness in multi-view clustering, most methods impose explicit regularization on cluster assignments, relying on the alignment between sensitive attributes and the underlying cluster structure. However, this assumption often fails in practice and can degrade clustering performance. In this paper, we propose an adversarial fair multi-view clustering (AFMVC) framework that integrates fairness learning into the representation learning process. Specifically, our method employs adversarial training to fundamentally remove sensitive attribute information from learned features, ensuring that the resulting cluster assignments are unaffected by it. Furthermore, we theoretically prove that aligning view-specific clustering assignments with a fairness-invariant consensus distribution via KL divergence preserves clustering consistency without significantly compromising fairness, thereby providing additional theoretical guarantees for our framework. Extensive experiments on data sets with fairness constraints demonstrate that AFMVC achieves superior fairness and competitive clustering performance compared to existing multi-view clustering and fairness-aware clustering methods.
Interpretable Clustering Ensemble
Jun 06, 2025Clustering ensemble has emerged as an important research topic in the field of machine learning. Although numerous methods have been proposed to improve clustering quality, most existing approaches overlook the need for interpretability in high-stakes applications. In domains such as medical diagnosis and financial risk assessment, algorithms must not only be accurate but also interpretable to ensure transparent and trustworthy decision-making. Therefore, to fill the gap of lack of interpretable algorithms in the field of clustering ensemble, we propose the first interpretable clustering ensemble algorithm in the literature. By treating base partitions as categorical variables, our method constructs a decision tree in the original feature space and use the statistical association test to guide the tree building process. Experimental results demonstrate that our algorithm achieves comparable performance to state-of-the-art (SOTA) clustering ensemble methods while maintaining an additional feature of interpretability. To the best of our knowledge, this is the first interpretable algorithm specifically designed for clustering ensemble, offering a new perspective for future research in interpretable clustering.
iLLaVA: An Image is Worth Fewer Than 1/3 Input Tokens in Large Multimodal Models
Dec 09, 2024



In this paper, we introduce iLLaVA, a simple method that can be seamlessly deployed upon current Large Vision-Language Models (LVLMs) to greatly increase the throughput with nearly lossless model performance, without a further requirement to train. iLLaVA achieves this by finding and gradually merging the redundant tokens with an accurate and fast algorithm, which can merge hundreds of tokens within only one step. While some previous methods have explored directly pruning or merging tokens in the inference stage to accelerate models, our method excels in both performance and throughput by two key designs. First, while most previous methods only try to save the computations of Large Language Models (LLMs), our method accelerates the forward pass of both image encoders and LLMs in LVLMs, which both occupy a significant part of time during inference. Second, our method recycles the beneficial information from the pruned tokens into existing tokens, which avoids directly dropping context tokens like previous methods to cause performance loss. iLLaVA can nearly 2$\times$ the throughput, and reduce the memory costs by half with only a 0.2\% - 0.5\% performance drop across models of different scales including 7B, 13B and 34B. On tasks across different domains including single-image, multi-images and videos, iLLaVA demonstrates strong generalizability with consistently promising efficiency. We finally offer abundant visualizations to show the merging processes of iLLaVA in each step, which show insights into the distribution of computing resources in LVLMs. Code is available at https://github.com/hulianyuyy/iLLaVA.
Conjunction Subspaces Test for Conformal and Selective Classification
Oct 16, 2024


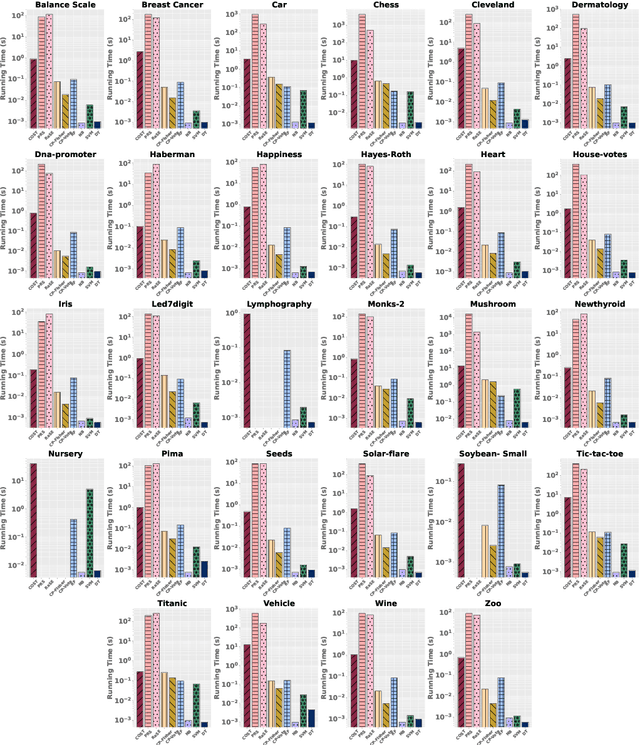
In this paper, we present a new classifier, which integrates significance testing results over different random subspaces to yield consensus p-values for quantifying the uncertainty of classification decision. The null hypothesis is that the test sample has no association with the target class on a randomly chosen subspace, and hence the classification problem can be formulated as a problem of testing for the conjunction of hypotheses. The proposed classifier can be easily deployed for the purpose of conformal prediction and selective classification with reject and refine options by simply thresholding the consensus p-values. The theoretical analysis on the generalization error bound of the proposed classifier is provided and empirical studies on real data sets are conducted as well to demonstrate its effectiveness.
Deep Correlated Prompting for Visual Recognition with Missing Modalities
Oct 10, 2024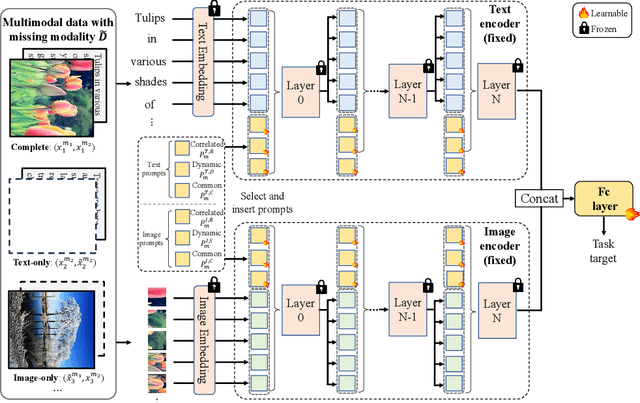
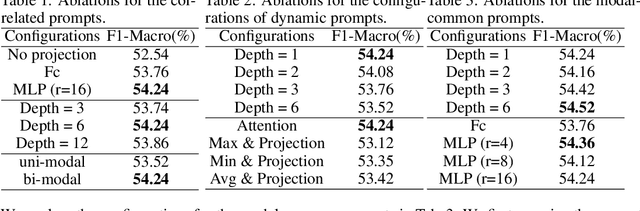
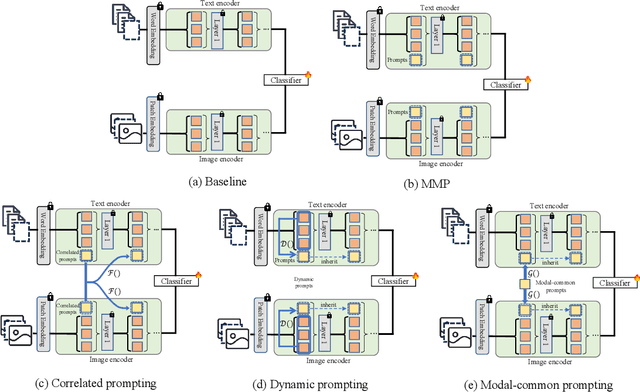
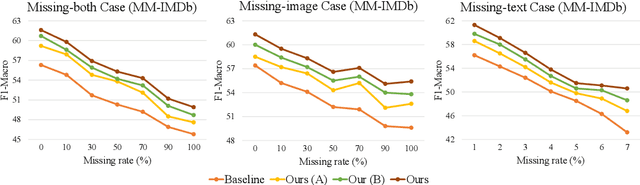
Large-scale multimodal models have shown excellent performance over a series of tasks powered by the large corpus of paired multimodal training data. Generally, they are always assumed to receive modality-complete inputs. However, this simple assumption may not always hold in the real world due to privacy constraints or collection difficulty, where models pretrained on modality-complete data easily demonstrate degraded performance on missing-modality cases. To handle this issue, we refer to prompt learning to adapt large pretrained multimodal models to handle missing-modality scenarios by regarding different missing cases as different types of input. Instead of only prepending independent prompts to the intermediate layers, we present to leverage the correlations between prompts and input features and excavate the relationships between different layers of prompts to carefully design the instructions. We also incorporate the complementary semantics of different modalities to guide the prompting design for each modality. Extensive experiments on three commonly-used datasets consistently demonstrate the superiority of our method compared to the previous approaches upon different missing scenarios. Plentiful ablations are further given to show the generalizability and reliability of our method upon different modality-missing ratios and types.
Pose-Guided Fine-Grained Sign Language Video Generation
Sep 25, 2024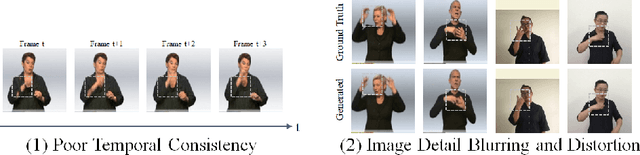

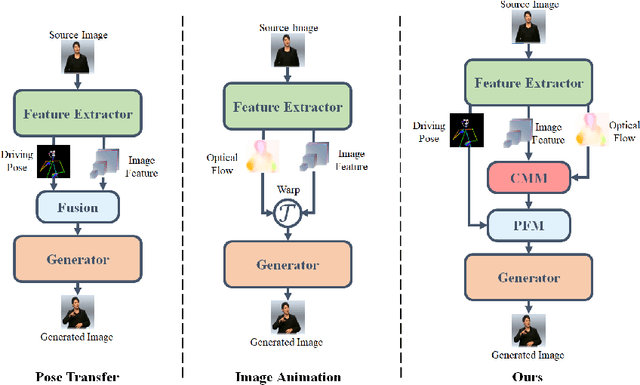
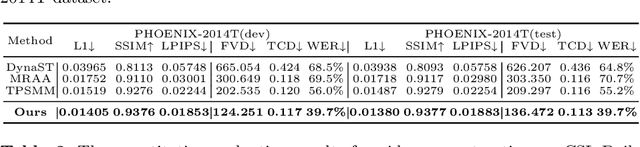
Sign language videos are an important medium for spreading and learning sign language. However, most existing human image synthesis methods produce sign language images with details that are distorted, blurred, or structurally incorrect. They also produce sign language video frames with poor temporal consistency, with anomalies such as flickering and abrupt detail changes between the previous and next frames. To address these limitations, we propose a novel Pose-Guided Motion Model (PGMM) for generating fine-grained and motion-consistent sign language videos. Firstly, we propose a new Coarse Motion Module (CMM), which completes the deformation of features by optical flow warping, thus transfering the motion of coarse-grained structures without changing the appearance; Secondly, we propose a new Pose Fusion Module (PFM), which guides the modal fusion of RGB and pose features, thus completing the fine-grained generation. Finally, we design a new metric, Temporal Consistency Difference (TCD) to quantitatively assess the degree of temporal consistency of a video by comparing the difference between the frames of the reconstructed video and the previous and next frames of the target video. Extensive qualitative and quantitative experiments show that our method outperforms state-of-the-art methods in most benchmark tests, with visible improvements in details and temporal consistency.
Interpretable Clustering: A Survey
Sep 01, 2024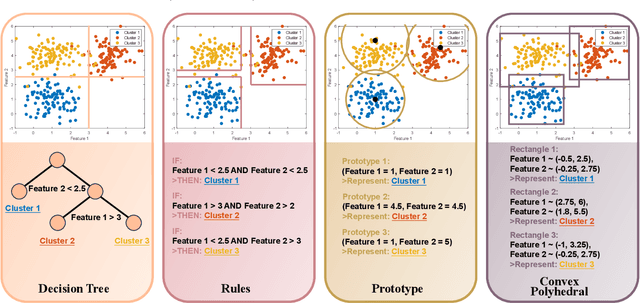

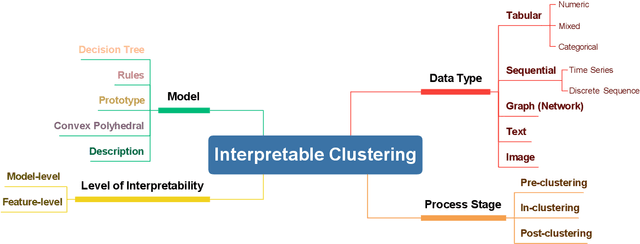

In recent years, much of the research on clustering algorithms has primarily focused on enhancing their accuracy and efficiency, frequently at the expense of interpretability. However, as these methods are increasingly being applied in high-stakes domains such as healthcare, finance, and autonomous systems, the need for transparent and interpretable clustering outcomes has become a critical concern. This is not only necessary for gaining user trust but also for satisfying the growing ethical and regulatory demands in these fields. Ensuring that decisions derived from clustering algorithms can be clearly understood and justified is now a fundamental requirement. To address this need, this paper provides a comprehensive and structured review of the current state of explainable clustering algorithms, identifying key criteria to distinguish between various methods. These insights can effectively assist researchers in making informed decisions about the most suitable explainable clustering methods for specific application contexts, while also promoting the development and adoption of clustering algorithms that are both efficient and transparent.