 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Fair Multi-View Clustering
Aug 06, 2025Cluster analysis is a fundamental problem in data mining and machine learning. In recent years, multi-view clustering has attracted increasing attention due to its ability to integrate complementary information from multiple views. However, existing methods primarily focus on clustering performance, while fairness-a critical concern in human-centered applications-has been largely overlooked. Although recent studies have explored group fairness in multi-view clustering, most methods impose explicit regularization on cluster assignments, relying on the alignment between sensitive attributes and the underlying cluster structure. However, this assumption often fails in practice and can degrade clustering performance. In this paper, we propose an adversarial fair multi-view clustering (AFMVC) framework that integrates fairness learning into the representation learning process. Specifically, our method employs adversarial training to fundamentally remove sensitive attribute information from learned features, ensuring that the resulting cluster assignments are unaffected by it. Furthermore, we theoretically prove that aligning view-specific clustering assignments with a fairness-invariant consensus distribution via KL divergence preserves clustering consistency without significantly compromising fairness, thereby providing additional theoretical guarantees for our framework. Extensive experiments on data sets with fairness constraints demonstrate that AFMVC achieves superior fairness and competitive clustering performance compared to existing multi-view clustering and fairness-aware clustering methods.
Interpretable Clustering Ensemble
Jun 06, 2025Clustering ensemble has emerged as an important research topic in the field of machine learning. Although numerous methods have been proposed to improve clustering quality, most existing approaches overlook the need for interpretability in high-stakes applications. In domains such as medical diagnosis and financial risk assessment, algorithms must not only be accurate but also interpretable to ensure transparent and trustworthy decision-making. Therefore, to fill the gap of lack of interpretable algorithms in the field of clustering ensemble, we propose the first interpretable clustering ensemble algorithm in the literature. By treating base partitions as categorical variables, our method constructs a decision tree in the original feature space and use the statistical association test to guide the tree building process. Experimental results demonstrate that our algorithm achieves comparable performance to state-of-the-art (SOTA) clustering ensemble methods while maintaining an additional feature of interpretability. To the best of our knowledge, this is the first interpretable algorithm specifically designed for clustering ensemble, offering a new perspective for future research in interpretable clustering.
Conjunction Subspaces Test for Conformal and Selective Classification
Oct 16, 2024


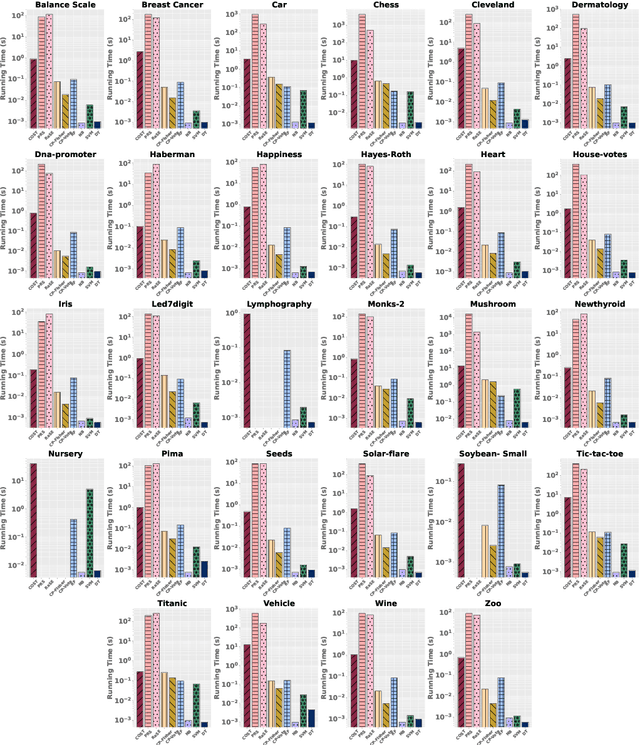
In this paper, we present a new classifier, which integrates significance testing results over different random subspaces to yield consensus p-values for quantifying the uncertainty of classification decision. The null hypothesis is that the test sample has no association with the target class on a randomly chosen subspace, and hence the classification problem can be formulated as a problem of testing for the conjunction of hypotheses. The proposed classifier can be easily deployed for the purpose of conformal prediction and selective classification with reject and refine options by simply thresholding the consensus p-values. The theoretical analysis on the generalization error bound of the proposed classifier is provided and empirical studies on real data sets are conducted as well to demonstrate its effectiveness.
Interpretable Clustering: A Survey
Sep 01, 2024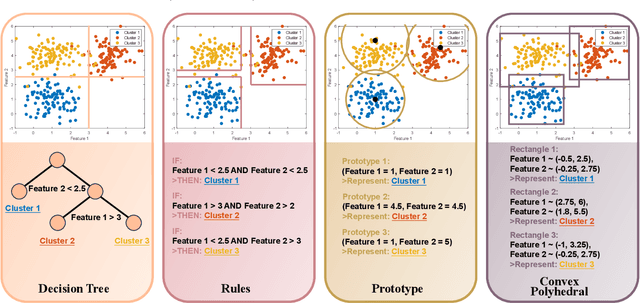

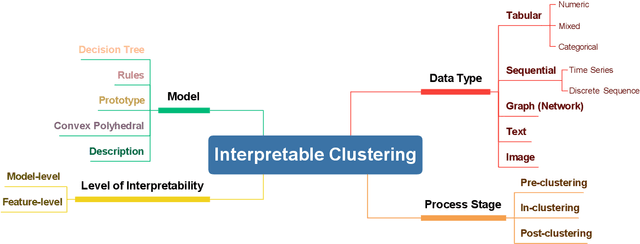

In recent years, much of the research on clustering algorithms has primarily focused on enhancing their accuracy and efficiency, frequently at the expense of interpretability. However, as these methods are increasingly being applied in high-stakes domains such as healthcare, finance, and autonomous systems, the need for transparent and interpretable clustering outcomes has become a critical concern. This is not only necessary for gaining user trust but also for satisfying the growing ethical and regulatory demands in these fields. Ensuring that decisions derived from clustering algorithms can be clearly understood and justified is now a fundamental requirement. To address this need, this paper provides a comprehensive and structured review of the current state of explainable clustering algorithms, identifying key criteria to distinguish between various methods. These insights can effectively assist researchers in making informed decisions about the most suitable explainable clustering methods for specific application contexts, while also promoting the development and adoption of clustering algorithms that are both efficient and transparent.