 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConjunction Subspaces Test for Conformal and Selective Classification
Oct 16, 2024


In this paper, we present a new classifier, which integrates significance testing results over different random subspaces to yield consensus p-values for quantifying the uncertainty of classification decision. The null hypothesis is that the test sample has no association with the target class on a randomly chosen subspace, and hence the classification problem can be formulated as a problem of testing for the conjunction of hypotheses. The proposed classifier can be easily deployed for the purpose of conformal prediction and selective classification with reject and refine options by simply thresholding the consensus p-values. The theoretical analysis on the generalization error bound of the proposed classifier is provided and empirical studies on real data sets are conducted as well to demonstrate its effectiveness.
Towards understanding evolution of science through language model series
Sep 15, 2024



We introduce AnnualBERT, a series of language models designed specifically to capture the temporal evolution of scientific text. Deviating from the prevailing paradigms of subword tokenizations and "one model to rule them all", AnnualBERT adopts whole words as tokens and is composed of a base RoBERTa model pretrained from scratch on the full-text of 1.7 million arXiv papers published until 2008 and a collection of progressively trained models on arXiv papers at an annual basis. We demonstrate the effectiveness of AnnualBERT models by showing that they not only have comparable performances in standard tasks but also achieve state-of-the-art performances on domain-specific NLP tasks as well as link prediction tasks in the arXiv citation network. We then utilize probing tasks to quantify the models' behavior in terms of representation learning and forgetting as time progresses. Our approach enables the pretrained models to not only improve performances on scientific text processing tasks but also to provide insights into the development of scientific discourse over time. The series of the models is available at https://huggingface.co/jd445/AnnualBERTs.
Interpretable Clustering: A Survey
Sep 01, 2024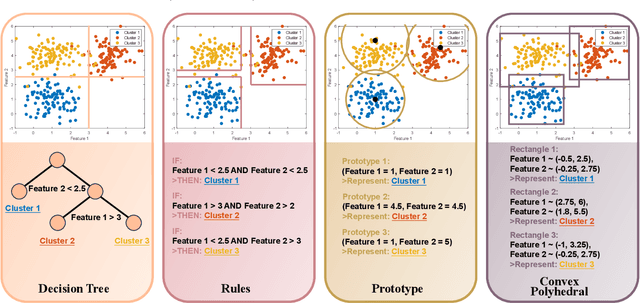

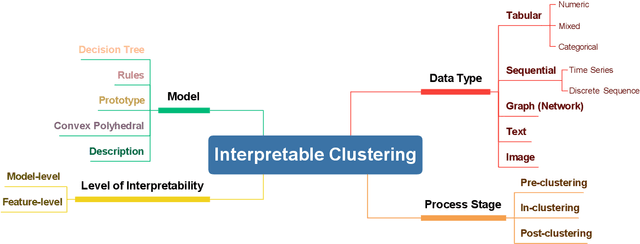

In recent years, much of the research on clustering algorithms has primarily focused on enhancing their accuracy and efficiency, frequently at the expense of interpretability. However, as these methods are increasingly being applied in high-stakes domains such as healthcare, finance, and autonomous systems, the need for transparent and interpretable clustering outcomes has become a critical concern. This is not only necessary for gaining user trust but also for satisfying the growing ethical and regulatory demands in these fields. Ensuring that decisions derived from clustering algorithms can be clearly understood and justified is now a fundamental requirement. To address this need, this paper provides a comprehensive and structured review of the current state of explainable clustering algorithms, identifying key criteria to distinguish between various methods. These insights can effectively assist researchers in making informed decisions about the most suitable explainable clustering methods for specific application contexts, while also promoting the development and adoption of clustering algorithms that are both efficient and transparent.
Hamming Encoder: Mining Discriminative k-mers for Discrete Sequence Classification
Oct 20, 2023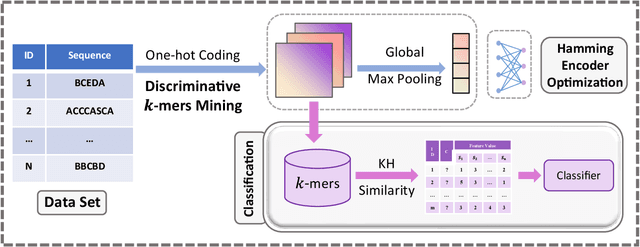



Sequence classification has numerous applications in various fields. Despite extensive studies in the last decades, many challenges still exist, particularly in pattern-based methods. Existing pattern-based methods measure the discriminative power of each feature individually during the mining process, leading to the result of missing some combinations of features with discriminative power. Furthermore, it is difficult to ensure the overall discriminative performance after converting sequences into feature vectors. To address these challenges, we propose a novel approach called Hamming Encoder, which utilizes a binarized 1D-convolutional neural network (1DCNN) architecture to mine discriminative k-mer sets. In particular, we adopt a Hamming distance-based similarity measure to ensure consistency in the feature mining and classification procedure. Our method involves training an interpretable CNN encoder for sequential data and performing a gradient-based search for discriminative k-mer combinations. Experiments show that the Hamming Encoder method proposed in this paper outperforms existing state-of-the-art methods in terms of classification accuracy.
Interpretable Sequence Clustering
Sep 03, 2023



Categorical sequence clustering plays a crucial role in various fields, but the lack of interpretability in cluster assignments poses significant challenges. Sequences inherently lack explicit features, and existing sequence clustering algorithms heavily rely on complex representations, making it difficult to explain their results. To address this issue, we propose a method called Interpretable Sequence Clustering Tree (ISCT), which combines sequential patterns with a concise and interpretable tree structure. ISCT leverages k-1 patterns to generate k leaf nodes, corresponding to k clusters, which provides an intuitive explanation on how each cluster is formed. More precisely, ISCT first projects sequences into random subspaces and then utilizes the k-means algorithm to obtain high-quality initial cluster assignments. Subsequently, it constructs a pattern-based decision tree using a boosting-based construction strategy in which sequences are re-projected and re-clustered at each node before mining the top-1 discriminative splitting pattern. Experimental results on 14 real-world data sets demonstrate that our proposed method provides an interpretable tree structure while delivering fast and accurate cluster assignments.
A testing-based approach to assess the clusterability of categorical data
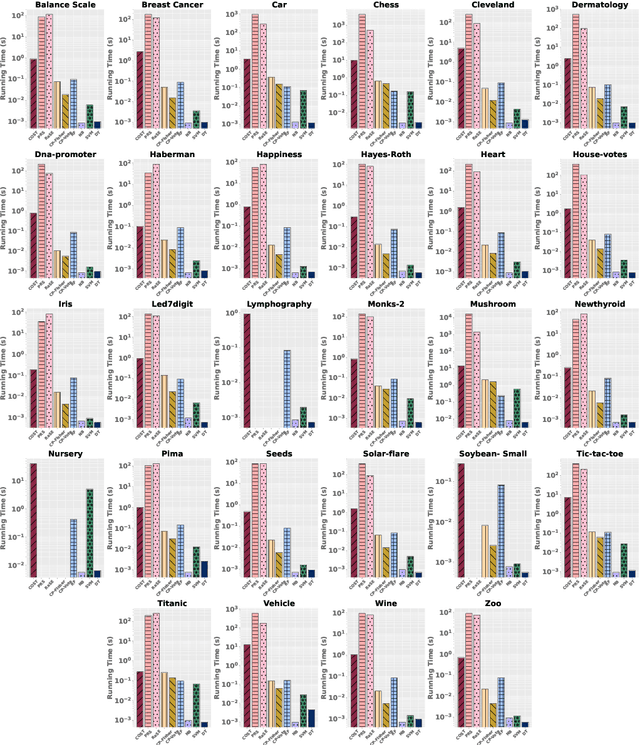
Jul 14, 2023The objective of clusterability evaluation is to check whether a clustering structure exists within the data set. As a crucial yet often-overlooked issue in cluster analysis, it is essential to conduct such a test before applying any clustering algorithm. If a data set is unclusterable, any subsequent clustering analysis would not yield valid results. Despite its importance, the majority of existing studies focus on numerical data, leaving the clusterability evaluation issue for categorical data as an open problem. Here we present TestCat, a testing-based approach to assess the clusterability of categorical data in terms of an analytical $p$-value. The key idea underlying TestCat is that clusterable categorical data possess many strongly correlated attribute pairs and hence the sum of chi-squared statistics of all attribute pairs is employed as the test statistic for $p$-value calculation. We apply our method to a set of benchmark categorical data sets, showing that TestCat outperforms those solutions based on existing clusterability evaluation methods for numeric data. To the best of our knowledge, our work provides the first way to effectively recognize the clusterability of categorical data in a statistically sound manner.