 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot too long do read: Evaluating LLM-generated extreme scientific summaries
Dec 29, 2025High-quality scientific extreme summary (TLDR) facilitates effective science communication. How do large language models (LLMs) perform in generating them? How are LLM-generated summaries different from those written by human experts? However, the lack of a comprehensive, high-quality scientific TLDR dataset hinders both the development and evaluation of LLMs' summarization ability. To address these, we propose a novel dataset, BiomedTLDR, containing a large sample of researcher-authored summaries from scientific papers, which leverages the common practice of including authors' comments alongside bibliography items. We then test popular open-weight LLMs for generating TLDRs based on abstracts. Our analysis reveals that, although some of them successfully produce humanoid summaries, LLMs generally exhibit a greater affinity for the original text's lexical choices and rhetorical structures, hence tend to be more extractive rather than abstractive in general, compared to humans. Our code and datasets are available at https://github.com/netknowledge/LLM_summarization (Lyu and Ke, 2025).
Towards understanding evolution of science through language model series
Sep 15, 2024



We introduce AnnualBERT, a series of language models designed specifically to capture the temporal evolution of scientific text. Deviating from the prevailing paradigms of subword tokenizations and "one model to rule them all", AnnualBERT adopts whole words as tokens and is composed of a base RoBERTa model pretrained from scratch on the full-text of 1.7 million arXiv papers published until 2008 and a collection of progressively trained models on arXiv papers at an annual basis. We demonstrate the effectiveness of AnnualBERT models by showing that they not only have comparable performances in standard tasks but also achieve state-of-the-art performances on domain-specific NLP tasks as well as link prediction tasks in the arXiv citation network. We then utilize probing tasks to quantify the models' behavior in terms of representation learning and forgetting as time progresses. Our approach enables the pretrained models to not only improve performances on scientific text processing tasks but also to provide insights into the development of scientific discourse over time. The series of the models is available at https://huggingface.co/jd445/AnnualBERTs.
Graph Neural Network Based VC Investment Success Prediction
May 25, 2021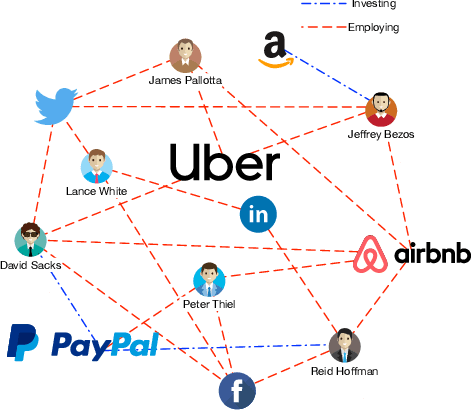
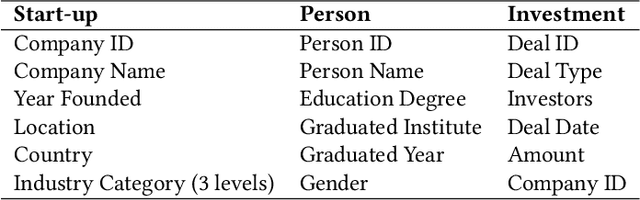
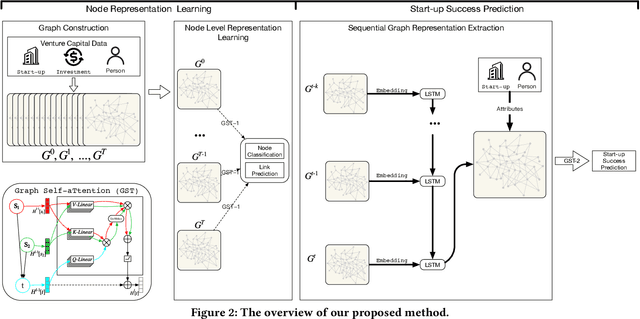
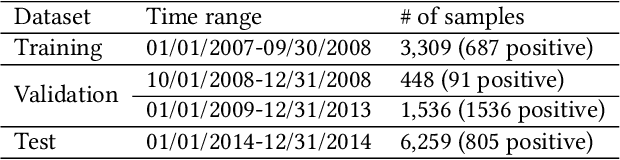
Predicting the start-ups that will eventually succeed is essentially important for the venture capital business and worldwide policy makers, especially at an early stage such that rewards can possibly be exponential. Though various empirical studies and data-driven modeling work have been done, the predictive power of the complex networks of stakeholders including venture capital investors, start-ups, and start-ups' managing members has not been thoroughly explored. We design an incremental representation learning mechanism and a sequential learning model, utilizing the network structure together with the rich attributes of the nodes. In general, our method achieves the state-of-the-art prediction performance on a comprehensive dataset of global venture capital investments and surpasses human investors by large margins. Specifically, it excels at predicting the outcomes for start-ups in industries such as healthcare and IT. Meanwhile, we shed light on impacts on start-up success from observable factors including gender, education, and networking, which can be of value for practitioners as well as policy makers when they screen ventures of high growth potentials.