 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Did the President Visit Last Week? Detecting Celebrity Trips from News Articles
Jul 17, 2023

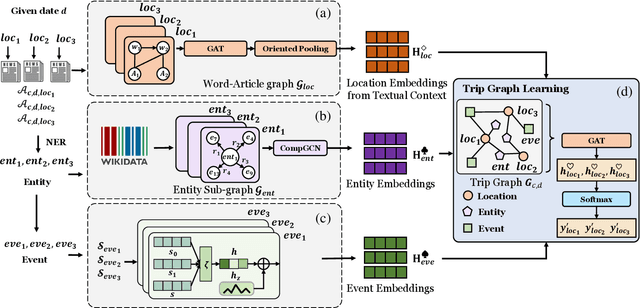

Celebrities' whereabouts are of pervasive importance. For instance, where politicians go, how often they visit, and who they meet, come with profound geopolitical and economic implications. Although news articles contain travel information of celebrities, it is not possible to perform large-scale and network-wise analysis due to the lack of automatic itinerary detection tools. To design such tools, we have to overcome difficulties from the heterogeneity among news articles: 1)One single article can be noisy, with irrelevant people and locations, especially when the articles are long. 2)Though it may be helpful if we consider multiple articles together to determine a particular trip, the key semantics are still scattered across different articles intertwined with various noises, making it hard to aggregate them effectively. 3)Over 20% of the articles refer to the celebrities' trips indirectly, instead of using the exact celebrity names or location names, leading to large portions of trips escaping regular detecting algorithms. We model text content across articles related to each candidate location as a graph to better associate essential information and cancel out the noises. Besides, we design a special pooling layer based on attention mechanism and node similarity, reducing irrelevant information from longer articles. To make up the missing information resulted from indirect mentions, we construct knowledge sub-graphs for named entities (person, organization, facility, etc.). Specifically, we dynamically update embeddings of event entities like the G7 summit from news descriptions since the properties (date and location) of the event change each time, which is not captured by the pre-trained event representations. The proposed CeleTrip jointly trains these modules, which outperforms all baseline models and achieves 82.53% in the F1 metric.
For the Underrepresented in Gender Bias Research: Chinese Name Gender Prediction with Heterogeneous Graph Attention Network
Feb 01, 2023Achieving gender equality is an important pillar for humankind's sustainable future. Pioneering data-driven gender bias research is based on large-scale public records such as scientific papers, patents, and company registrations, covering female researchers, inventors and entrepreneurs, and so on. Since gender information is often missing in relevant datasets, studies rely on tools to infer genders from names. However, available open-sourced Chinese gender-guessing tools are not yet suitable for scientific purposes, which may be partially responsible for female Chinese being underrepresented in mainstream gender bias research and affect their universality. Specifically, these tools focus on character-level information while overlooking the fact that the combinations of Chinese characters in multi-character names, as well as the components and pronunciations of characters, convey important messages. As a first effort, we design a Chinese Heterogeneous Graph Attention (CHGAT) model to capture the heterogeneity in component relationships and incorporate the pronunciations of characters. Our model largely surpasses current tools and also outperforms the state-of-the-art algorithm. Last but not least, the most popular Chinese name-gender dataset is single-character based with far less female coverage from an unreliable source, naturally hindering relevant studies. We open-source a more balanced multi-character dataset from an official source together with our code, hoping to help future research promoting gender equality.
Graph Neural Network Based VC Investment Success Prediction
May 25, 2021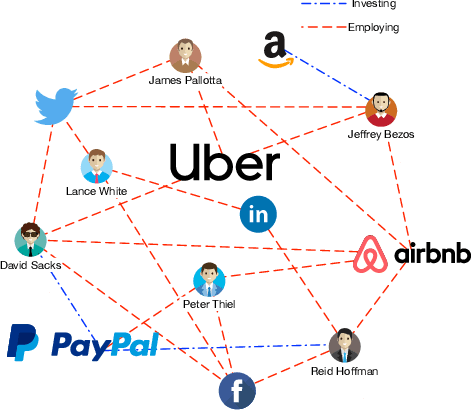
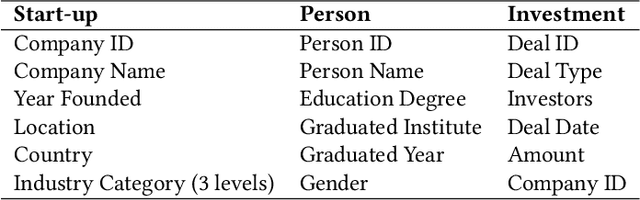
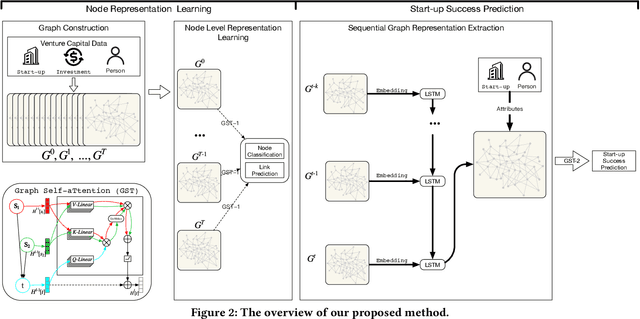
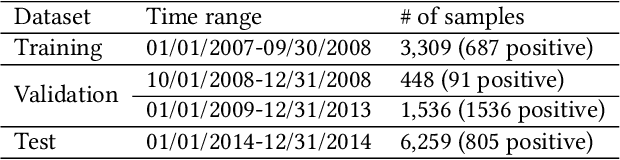
Predicting the start-ups that will eventually succeed is essentially important for the venture capital business and worldwide policy makers, especially at an early stage such that rewards can possibly be exponential. Though various empirical studies and data-driven modeling work have been done, the predictive power of the complex networks of stakeholders including venture capital investors, start-ups, and start-ups' managing members has not been thoroughly explored. We design an incremental representation learning mechanism and a sequential learning model, utilizing the network structure together with the rich attributes of the nodes. In general, our method achieves the state-of-the-art prediction performance on a comprehensive dataset of global venture capital investments and surpasses human investors by large margins. Specifically, it excels at predicting the outcomes for start-ups in industries such as healthcare and IT. Meanwhile, we shed light on impacts on start-up success from observable factors including gender, education, and networking, which can be of value for practitioners as well as policy makers when they screen ventures of high growth potentials.