 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUPLEX: Dual GAT for Complex Embedding of Directed Graphs
Jun 08, 2024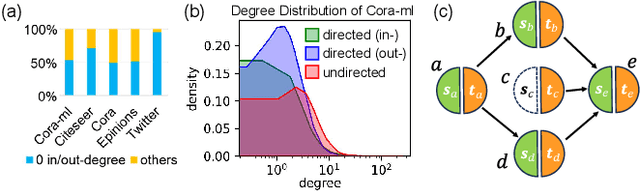
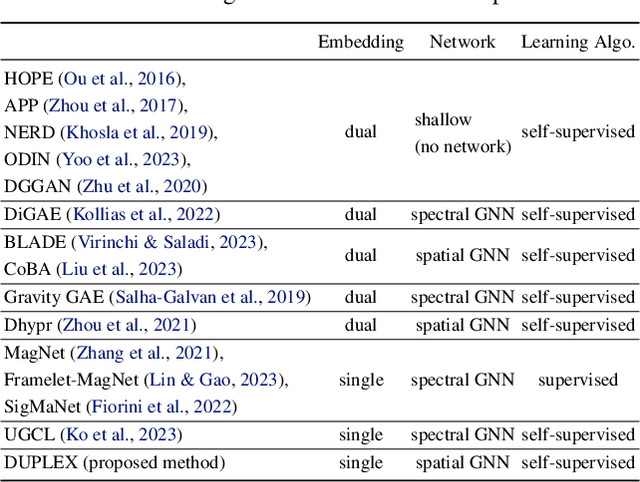
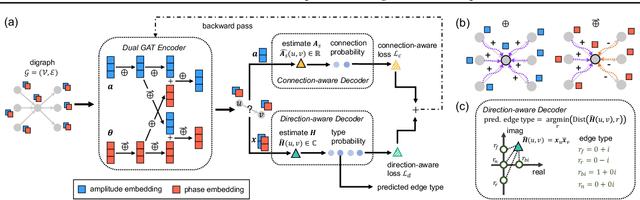
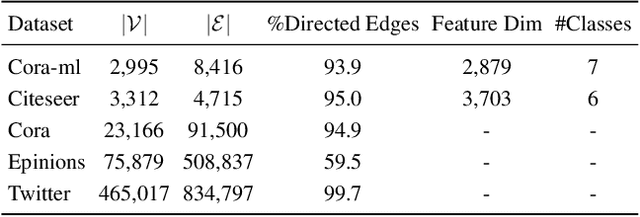
Current directed graph embedding methods build upon undirected techniques but often inadequately capture directed edge information, leading to challenges such as: (1) Suboptimal representations for nodes with low in/out-degrees, due to the insufficient neighbor interactions; (2) Limited inductive ability for representing new nodes post-training; (3) Narrow generalizability, as training is overly coupled with specific tasks. In response, we propose DUPLEX, an inductive framework for complex embeddings of directed graphs. It (1) leverages Hermitian adjacency matrix decomposition for comprehensive neighbor integration, (2) employs a dual GAT encoder for directional neighbor modeling, and (3) features two parameter-free decoders to decouple training from particular tasks. DUPLEX outperforms state-of-the-art models, especially for nodes with sparse connectivity, and demonstrates robust inductive capability and adaptability across various tasks. The code is available at https://github.com/alipay/DUPLEX.
Where Did the President Visit Last Week? Detecting Celebrity Trips from News Articles
Jul 17, 2023

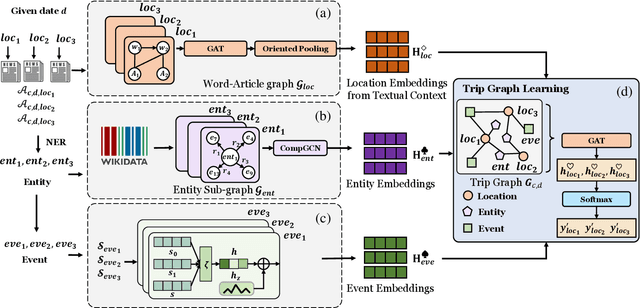

Celebrities' whereabouts are of pervasive importance. For instance, where politicians go, how often they visit, and who they meet, come with profound geopolitical and economic implications. Although news articles contain travel information of celebrities, it is not possible to perform large-scale and network-wise analysis due to the lack of automatic itinerary detection tools. To design such tools, we have to overcome difficulties from the heterogeneity among news articles: 1)One single article can be noisy, with irrelevant people and locations, especially when the articles are long. 2)Though it may be helpful if we consider multiple articles together to determine a particular trip, the key semantics are still scattered across different articles intertwined with various noises, making it hard to aggregate them effectively. 3)Over 20% of the articles refer to the celebrities' trips indirectly, instead of using the exact celebrity names or location names, leading to large portions of trips escaping regular detecting algorithms. We model text content across articles related to each candidate location as a graph to better associate essential information and cancel out the noises. Besides, we design a special pooling layer based on attention mechanism and node similarity, reducing irrelevant information from longer articles. To make up the missing information resulted from indirect mentions, we construct knowledge sub-graphs for named entities (person, organization, facility, etc.). Specifically, we dynamically update embeddings of event entities like the G7 summit from news descriptions since the properties (date and location) of the event change each time, which is not captured by the pre-trained event representations. The proposed CeleTrip jointly trains these modules, which outperforms all baseline models and achieves 82.53% in the F1 metric.