 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Noise Suppression and Discriminative Mutual Interaction for Robust Audio-Visual Segmentation
Mar 15, 2026The ability to capture and segment sounding objects in dynamic visual scenes is crucial for the development of Audio-Visual Segmentation (AVS) tasks. While significant progress has been made in this area, the interaction between audio and visual modalities still requires further exploration. In this work, we aim to answer the following questions: How can a model effectively suppress audio noise while enhancing relevant audio information? How can we achieve discriminative interaction between the audio and visual modalities? To this end, we propose SDAVS, equipped with the Selective Noise-Resilient Processor (SNRP) module and the Discriminative Audio-Visual Mutual Fusion (DAMF) strategy. The proposed SNRP mitigates audio noise interference by selectively emphasizing relevant auditory cues, while DAMF ensures more consistent audio-visual representations. Experimental results demonstrate that our proposed method achieves state-of-the-art performance on benchmark AVS datasets, especially in multi-source and complex scenes. \textit{The code and model are available at https://github.com/happylife-pk/SDAVS}.
A Transformer variant for multi-step forecasting of water level and hydrometeorological sensitivity analysis based on explainable artificial intelligence technology
May 22, 2024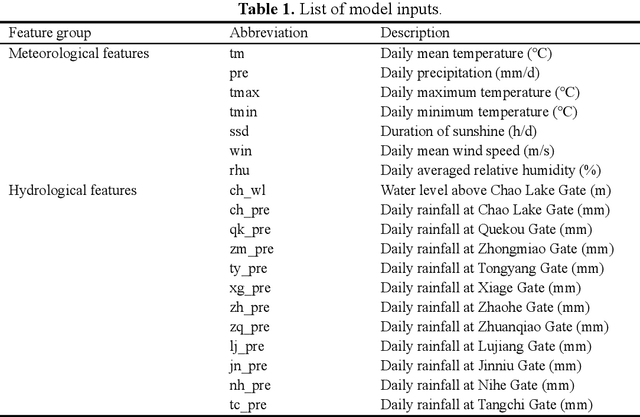
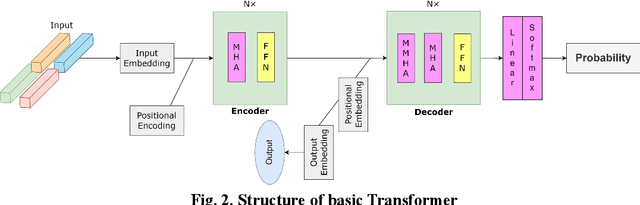

Understanding the combined influences of meteorological and hydrological factors on water level and flood events is essential, particularly in today's changing climate environments. Transformer, as one kind of the cutting-edge deep learning methods, offers an effective approach to model intricate nonlinear processes, enables the extraction of key features and water level predictions. EXplainable Artificial Intelligence (XAI) methods play important roles in enhancing the understandings of how different factors impact water level. In this study, we propose a Transformer variant by integrating sparse attention mechanism and introducing nonlinear output layer for the decoder module. The variant model is utilized for multi-step forecasting of water level, by considering meteorological and hydrological factors simultaneously. It is shown that the variant model outperforms traditional Transformer across different lead times with respect to various evaluation metrics. The sensitivity analyses based on XAI technology demonstrate the significant influence of meteorological factors on water level evolution, in which temperature is shown to be the most dominant meteorological factor. Therefore, incorporating both meteorological and hydrological factors is necessary for reliable hydrological prediction and flood prevention. In the meantime, XAI technology provides insights into certain predictions, which is beneficial for understanding the prediction results and evaluating the reasonability.
Where Did the President Visit Last Week? Detecting Celebrity Trips from News Articles
Jul 17, 2023

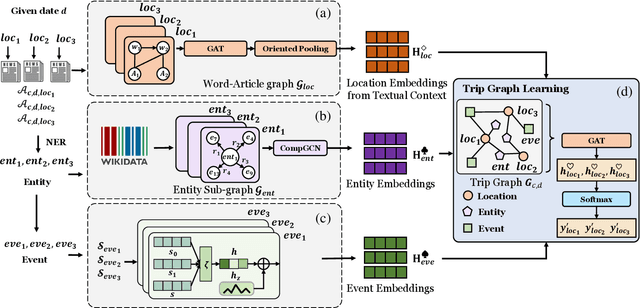

Celebrities' whereabouts are of pervasive importance. For instance, where politicians go, how often they visit, and who they meet, come with profound geopolitical and economic implications. Although news articles contain travel information of celebrities, it is not possible to perform large-scale and network-wise analysis due to the lack of automatic itinerary detection tools. To design such tools, we have to overcome difficulties from the heterogeneity among news articles: 1)One single article can be noisy, with irrelevant people and locations, especially when the articles are long. 2)Though it may be helpful if we consider multiple articles together to determine a particular trip, the key semantics are still scattered across different articles intertwined with various noises, making it hard to aggregate them effectively. 3)Over 20% of the articles refer to the celebrities' trips indirectly, instead of using the exact celebrity names or location names, leading to large portions of trips escaping regular detecting algorithms. We model text content across articles related to each candidate location as a graph to better associate essential information and cancel out the noises. Besides, we design a special pooling layer based on attention mechanism and node similarity, reducing irrelevant information from longer articles. To make up the missing information resulted from indirect mentions, we construct knowledge sub-graphs for named entities (person, organization, facility, etc.). Specifically, we dynamically update embeddings of event entities like the G7 summit from news descriptions since the properties (date and location) of the event change each time, which is not captured by the pre-trained event representations. The proposed CeleTrip jointly trains these modules, which outperforms all baseline models and achieves 82.53% in the F1 metric.
Boundary Unlearning
Mar 21, 2023



The practical needs of the ``right to be forgotten'' and poisoned data removal call for efficient \textit{machine unlearning} techniques, which enable machine learning models to unlearn, or to forget a fraction of training data and its lineage. Recent studies on machine unlearning for deep neural networks (DNNs) attempt to destroy the influence of the forgetting data by scrubbing the model parameters. However, it is prohibitively expensive due to the large dimension of the parameter space. In this paper, we refocus our attention from the parameter space to the decision space of the DNN model, and propose Boundary Unlearning, a rapid yet effective way to unlearn an entire class from a trained DNN model. The key idea is to shift the decision boundary of the original DNN model to imitate the decision behavior of the model retrained from scratch. We develop two novel boundary shift methods, namely Boundary Shrink and Boundary Expanding, both of which can rapidly achieve the utility and privacy guarantees. We extensively evaluate Boundary Unlearning on CIFAR-10 and Vggface2 datasets, and the results show that Boundary Unlearning can effectively forget the forgetting class on image classification and face recognition tasks, with an expected speed-up of $17\times$ and $19\times$, respectively, compared with retraining from the scratch.
For the Underrepresented in Gender Bias Research: Chinese Name Gender Prediction with Heterogeneous Graph Attention Network
Feb 01, 2023Achieving gender equality is an important pillar for humankind's sustainable future. Pioneering data-driven gender bias research is based on large-scale public records such as scientific papers, patents, and company registrations, covering female researchers, inventors and entrepreneurs, and so on. Since gender information is often missing in relevant datasets, studies rely on tools to infer genders from names. However, available open-sourced Chinese gender-guessing tools are not yet suitable for scientific purposes, which may be partially responsible for female Chinese being underrepresented in mainstream gender bias research and affect their universality. Specifically, these tools focus on character-level information while overlooking the fact that the combinations of Chinese characters in multi-character names, as well as the components and pronunciations of characters, convey important messages. As a first effort, we design a Chinese Heterogeneous Graph Attention (CHGAT) model to capture the heterogeneity in component relationships and incorporate the pronunciations of characters. Our model largely surpasses current tools and also outperforms the state-of-the-art algorithm. Last but not least, the most popular Chinese name-gender dataset is single-character based with far less female coverage from an unreliable source, naturally hindering relevant studies. We open-source a more balanced multi-character dataset from an official source together with our code, hoping to help future research promoting gender equality.
Logistic-ELM: A Novel Fault Diagnosis Method for Rolling Bearings
Apr 23, 2022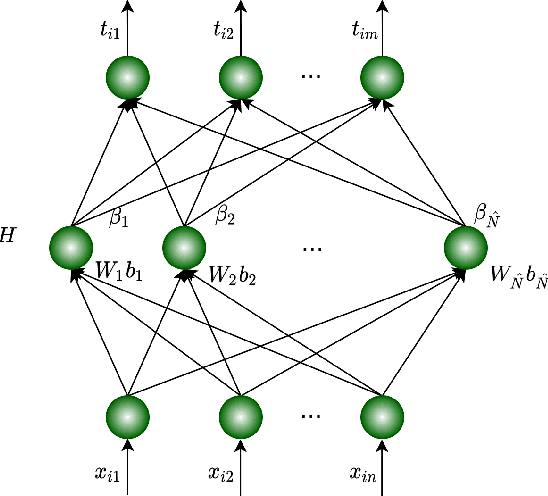
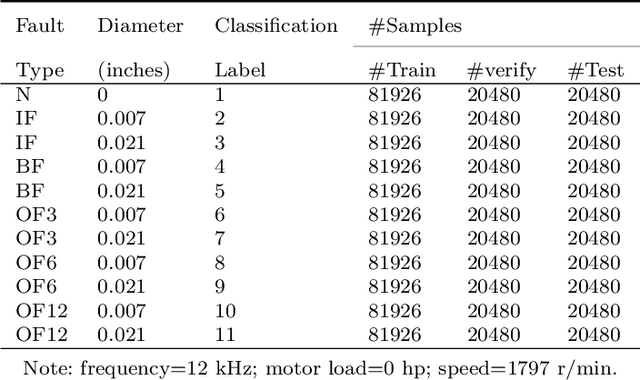
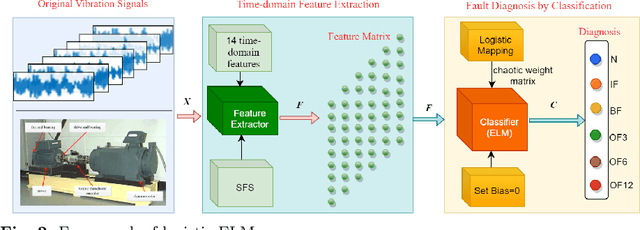

The fault diagnosis of rolling bearings is a critical technique to realize predictive maintenance for mechanical condition monitoring. In real industrial systems, the main challenges for the fault diagnosis of rolling bearings pertain to the accuracy and real-time requirements. Most existing methods focus on ensuring the accuracy, and the real-time requirement is often neglected. In this paper, considering both requirements, we propose a novel fast fault diagnosis method for rolling bearings, based on extreme learning machine (ELM) and logistic mapping, named logistic-ELM. First, we identify 14 kinds of time-domain features from the original vibration signals according to mechanical vibration principles and adopt the sequential forward selection (SFS) strategy to select optimal features from them to ensure the basic predictive accuracy and efficiency. Next, we propose the logistic-ELM for fast fault classification, where the biases in ELM are omitted and the random input weights are replaced by the chaotic logistic mapping sequence which involves a higher uncorrelation to obtain more accurate results with fewer hidden neurons. We conduct extensive experiments on the rolling bearing vibration signal dataset of the Case Western Reserve University (CWRU) Bearing Data Centre. The experimental results show that the proposed approach outperforms existing SOTA comparison methods in terms of the predictive accuracy, and the highest accuracy is 100% in seven separate sub data environments. The relevant code is publicly available at https://github.com/TAN-OpenLab/logistic-ELM.