 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Token Pruning for Historical Screenshots in GUI Visual Agents: Semantic, Spatial, and Temporal Perspectives
Mar 27, 2026In recent years, GUI visual agents built upon Multimodal Large Language Models (MLLMs) have demonstrated strong potential in navigation tasks. However, high-resolution GUI screenshots produce a large number of visual tokens, making the direct preservation of complete historical information computationally expensive. In this paper, we conduct an empirical study on token pruning for historical screenshots in GUI scenarios and distill three practical insights that are crucial for designing effective pruning strategies. First, we observe that GUI screenshots exhibit a distinctive foreground-background semantic composition. To probe this property, we apply a simple edge-based separation to partition screenshots into foreground and background regions. Surprisingly, we find that, contrary to the common assumption that background areas have little semantic value, they effectively capture interface-state transitions, thereby providing auxiliary cues for GUI reasoning. Second, compared with carefully designed pruning strategies, random pruning possesses an inherent advantage in preserving spatial structure, enabling better performance under the same computational budget. Finally, we observe that GUI Agents exhibit a recency effect similar to human cognition: by allocating larger token budgets to more recent screenshots and heavily compressing distant ones, we can significantly reduce computational cost while maintaining nearly unchanged performance. These findings offer new insights and practical guidance for the design of efficient GUI visual agents.
X2Edit: Revisiting Arbitrary-Instruction Image Editing through Self-Constructed Data and Task-Aware Representation Learning
Aug 11, 2025Existing open-source datasets for arbitrary-instruction image editing remain suboptimal, while a plug-and-play editing module compatible with community-prevalent generative models is notably absent. In this paper, we first introduce the X2Edit Dataset, a comprehensive dataset covering 14 diverse editing tasks, including subject-driven generation. We utilize the industry-leading unified image generation models and expert models to construct the data. Meanwhile, we design reasonable editing instructions with the VLM and implement various scoring mechanisms to filter the data. As a result, we construct 3.7 million high-quality data with balanced categories. Second, to better integrate seamlessly with community image generation models, we design task-aware MoE-LoRA training based on FLUX.1, with only 8\% of the parameters of the full model. To further improve the final performance, we utilize the internal representations of the diffusion model and define positive/negative samples based on image editing types to introduce contrastive learning. Extensive experiments demonstrate that the model's editing performance is competitive among many excellent models. Additionally, the constructed dataset exhibits substantial advantages over existing open-source datasets. The open-source code, checkpoints, and datasets for X2Edit can be found at the following link: https://github.com/OPPO-Mente-Lab/X2Edit.
Detail++: Training-Free Detail Enhancer for Text-to-Image Diffusion Models
Jul 23, 2025Recent advances in text-to-image (T2I) generation have led to impressive visual results. However, these models still face significant challenges when handling complex prompt, particularly those involving multiple subjects with distinct attributes. Inspired by the human drawing process, which first outlines the composition and then incrementally adds details, we propose Detail++, a training-free framework that introduces a novel Progressive Detail Injection (PDI) strategy to address this limitation. Specifically, we decompose a complex prompt into a sequence of simplified sub-prompts, guiding the generation process in stages. This staged generation leverages the inherent layout-controlling capacity of self-attention to first ensure global composition, followed by precise refinement. To achieve accurate binding between attributes and corresponding subjects, we exploit cross-attention mechanisms and further introduce a Centroid Alignment Loss at test time to reduce binding noise and enhance attribute consistency. Extensive experiments on T2I-CompBench and a newly constructed style composition benchmark demonstrate that Detail++ significantly outperforms existing methods, particularly in scenarios involving multiple objects and complex stylistic conditions.
GRE Suite: Geo-localization Inference via Fine-Tuned Vision-Language Models and Enhanced Reasoning Chains
May 24, 2025Recent advances in Visual Language Models (VLMs) have demonstrated exceptional performance in visual reasoning tasks. However, geo-localization presents unique challenges, requiring the extraction of multigranular visual cues from images and their integration with external world knowledge for systematic reasoning. Current approaches to geo-localization tasks often lack robust reasoning mechanisms and explainability, limiting their effectiveness. To address these limitations, we propose the Geo Reason Enhancement (GRE) Suite, a novel framework that augments VLMs with structured reasoning chains for accurate and interpretable location inference. The GRE Suite is systematically developed across three key dimensions: dataset, model, and benchmark. First, we introduce GRE30K, a high-quality geo-localization reasoning dataset designed to facilitate fine-grained visual and contextual analysis. Next, we present the GRE model, which employs a multi-stage reasoning strategy to progressively infer scene attributes, local details, and semantic features, thereby narrowing down potential geographic regions with enhanced precision. Finally, we construct the Geo Reason Evaluation Benchmark (GREval-Bench), a comprehensive evaluation framework that assesses VLMs across diverse urban, natural, and landmark scenes to measure both coarse-grained (e.g., country, continent) and fine-grained (e.g., city, street) localization performance. Experimental results demonstrate that GRE significantly outperforms existing methods across all granularities of geo-localization tasks, underscoring the efficacy of reasoning-augmented VLMs in complex geographic inference. Code and data will be released at https://github.com/Thorin215/GRE.
Blind Spot Navigation: Evolutionary Discovery of Sensitive Semantic Concepts for LVLMs
May 21, 2025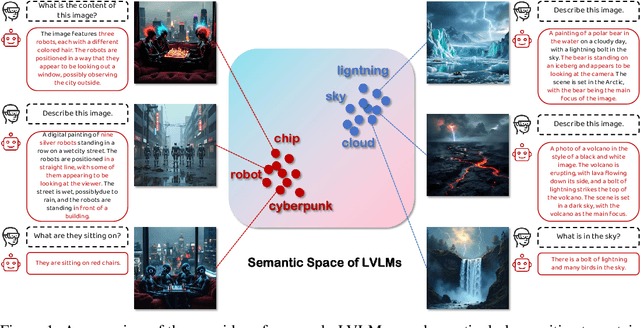
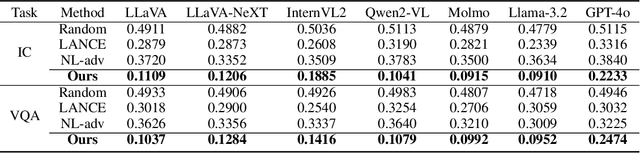
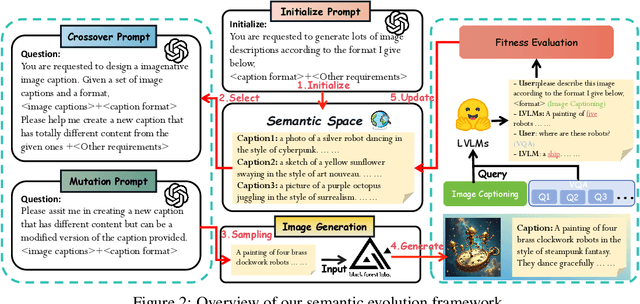
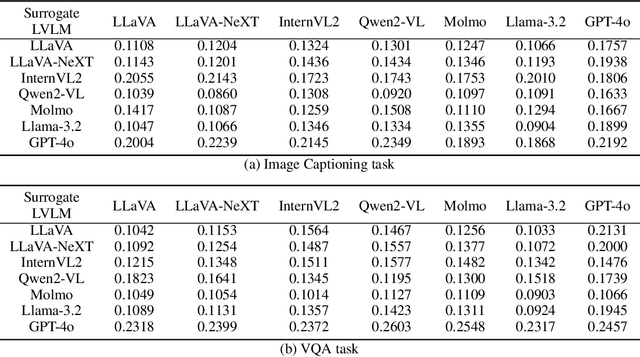
Adversarial attacks aim to generate malicious inputs that mislead deep models, but beyond causing model failure, they cannot provide certain interpretable information such as ``\textit{What content in inputs make models more likely to fail?}'' However, this information is crucial for researchers to specifically improve model robustness. Recent research suggests that models may be particularly sensitive to certain semantics in visual inputs (such as ``wet,'' ``foggy''), making them prone to errors. Inspired by this, in this paper we conducted the first exploration on large vision-language models (LVLMs) and found that LVLMs indeed are susceptible to hallucinations and various errors when facing specific semantic concepts in images. To efficiently search for these sensitive concepts, we integrated large language models (LLMs) and text-to-image (T2I) models to propose a novel semantic evolution framework. Randomly initialized semantic concepts undergo LLM-based crossover and mutation operations to form image descriptions, which are then converted by T2I models into visual inputs for LVLMs. The task-specific performance of LVLMs on each input is quantified as fitness scores for the involved semantics and serves as reward signals to further guide LLMs in exploring concepts that induce LVLMs. Extensive experiments on seven mainstream LVLMs and two multimodal tasks demonstrate the effectiveness of our method. Additionally, we provide interesting findings about the sensitive semantics of LVLMs, aiming to inspire further in-depth research.
Training-Free Watermarking for Autoregressive Image Generation
May 20, 2025



Invisible image watermarking can protect image ownership and prevent malicious misuse of visual generative models. However, existing generative watermarking methods are mainly designed for diffusion models while watermarking for autoregressive image generation models remains largely underexplored. We propose IndexMark, a training-free watermarking framework for autoregressive image generation models. IndexMark is inspired by the redundancy property of the codebook: replacing autoregressively generated indices with similar indices produces negligible visual differences. The core component in IndexMark is a simple yet effective match-then-replace method, which carefully selects watermark tokens from the codebook based on token similarity, and promotes the use of watermark tokens through token replacement, thereby embedding the watermark without affecting the image quality. Watermark verification is achieved by calculating the proportion of watermark tokens in generated images, with precision further improved by an Index Encoder. Furthermore, we introduce an auxiliary validation scheme to enhance robustness against cropping attacks. Experiments demonstrate that IndexMark achieves state-of-the-art performance in terms of image quality and verification accuracy, and exhibits robustness against various perturbations, including cropping, noises, Gaussian blur, random erasing, color jittering, and JPEG compression.
SCA: Highly Efficient Semantic-Consistent Unrestricted Adversarial Attack
Oct 03, 2024



Unrestricted adversarial attacks typically manipulate the semantic content of an image (e.g., color or texture) to create adversarial examples that are both effective and photorealistic. Recent works have utilized the diffusion inversion process to map images into a latent space, where high-level semantics are manipulated by introducing perturbations. However, they often results in substantial semantic distortions in the denoised output and suffers from low efficiency. In this study, we propose a novel framework called Semantic-Consistent Unrestricted Adversarial Attacks (SCA), which employs an inversion method to extract edit-friendly noise maps and utilizes Multimodal Large Language Model (MLLM) to provide semantic guidance throughout the process. Under the condition of rich semantic information provided by MLLM, we perform the DDPM denoising process of each step using a series of edit-friendly noise maps, and leverage DPM Solver++ to accelerate this process, enabling efficient sampling with semantic consistency. Compared to existing methods, our framework enables the efficient generation of adversarial examples that exhibit minimal discernible semantic changes. Consequently, we for the first time introduce Semantic-Consistent Adversarial Examples (SCAE). Extensive experiments and visualizations have demonstrated the high efficiency of SCA, particularly in being on average 12 times faster than the state-of-the-art attacks. Our code can be found at https://github.com/Pan-Zihao/SCA}{https://github.com/Pan-Zihao/SCA.
It Ain't That Bad: Understanding the Mysterious Performance Drop in OOD Generalization for Generative Transformer Models
Aug 16, 2023
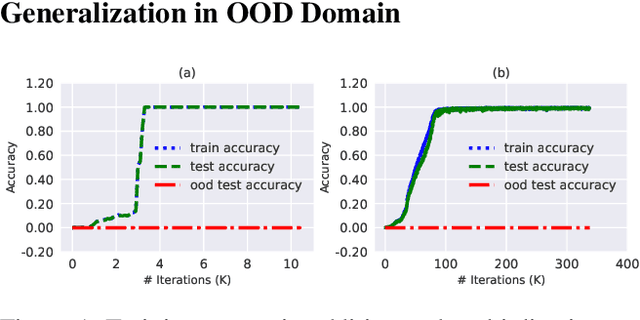
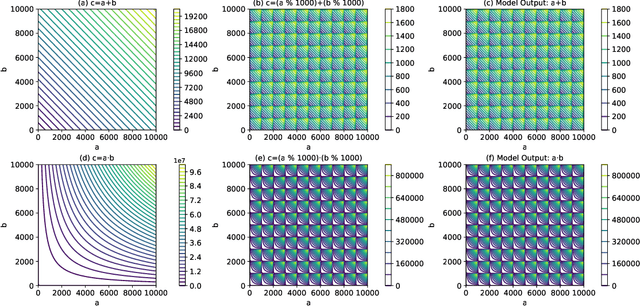
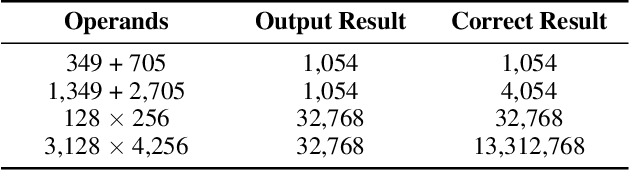
Generative Transformer-based models have achieved remarkable proficiency on solving diverse problems. However, their generalization ability is not fully understood and not always satisfying. Researchers take basic mathematical tasks like n-digit addition or multiplication as important perspectives for investigating their generalization behaviors. Curiously, it is observed that when training on n-digit operations (e.g., additions) in which both input operands are n-digit in length, models generalize successfully on unseen n-digit inputs (in-distribution (ID) generalization), but fail miserably and mysteriously on longer, unseen cases (out-of-distribution (OOD) generalization). Studies try to bridge this gap with workarounds such as modifying position embedding, fine-tuning, and priming with more extensive or instructive data. However, without addressing the essential mechanism, there is hardly any guarantee regarding the robustness of these solutions. We bring this unexplained performance drop into attention and ask whether it is purely from random errors. Here we turn to the mechanistic line of research which has notable successes in model interpretability. We discover that the strong ID generalization stems from structured representations, while behind the unsatisfying OOD performance, the models still exhibit clear learned algebraic structures. Specifically, these models map unseen OOD inputs to outputs with equivalence relations in the ID domain. These highlight the potential of the models to carry useful information for improved generalization.
For the Underrepresented in Gender Bias Research: Chinese Name Gender Prediction with Heterogeneous Graph Attention Network
Feb 01, 2023Achieving gender equality is an important pillar for humankind's sustainable future. Pioneering data-driven gender bias research is based on large-scale public records such as scientific papers, patents, and company registrations, covering female researchers, inventors and entrepreneurs, and so on. Since gender information is often missing in relevant datasets, studies rely on tools to infer genders from names. However, available open-sourced Chinese gender-guessing tools are not yet suitable for scientific purposes, which may be partially responsible for female Chinese being underrepresented in mainstream gender bias research and affect their universality. Specifically, these tools focus on character-level information while overlooking the fact that the combinations of Chinese characters in multi-character names, as well as the components and pronunciations of characters, convey important messages. As a first effort, we design a Chinese Heterogeneous Graph Attention (CHGAT) model to capture the heterogeneity in component relationships and incorporate the pronunciations of characters. Our model largely surpasses current tools and also outperforms the state-of-the-art algorithm. Last but not least, the most popular Chinese name-gender dataset is single-character based with far less female coverage from an unreliable source, naturally hindering relevant studies. We open-source a more balanced multi-character dataset from an official source together with our code, hoping to help future research promoting gender equality.