 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNSEEN: A Cross-Stack LLM Unlearning Defense against AR-LLM Social Engineering Attacks
Apr 25, 2026Emerging AR-LLM-based Social Engineering attack (e.g., SEAR) is at the edge of posing great threats to real-world social life. In such AR-LLM-SE attack, the attacker can leverage AR (Augmented Reality) glass to capture the image and vocal information of the target, using the LLM to identify the target and generate the social profile, using the LLM agents to apply social engineering strategies for conversation suggestion to win the target trust and perform phishing afterwards. Current defensive approaches, such as role-based access control or data flow tracking, are not directly applicable to the convergent AR-LLM ecosystem (considering embedded AR device and opaque LLM inference), leaving an emerging and potent social engineering threat that existing privacy paradigms are ill-equipped to address. This necessitates a shift beyond solely human-centric measures like legislation and user education toward enforceable vendor policies and platform-level restrictions. Realizing this vision, however, faces significant technical challenges: securing resource-constrained AR-embedded devices, implementing fine-grained access control within opaque LLM inferences, and governing adaptive interactive agents. To address these challenges, we present UNSEEN, a coordinated cross-stack defense that combines an AR ACL (Access Control Layer) for identity-gated sensing, F-RMU-based LLM unlearning for sensitive profile suppression, and runtime agent guardrails for adaptive interaction control. We evaluate UNSEEN in an IRB-approved user study with 60 participants and a dataset of 360 annotated conversations across realistic social scenarios.
Membership Inference Attack against Long-Context Large Language Models
Nov 18, 2024Recent advances in Large Language Models (LLMs) have enabled them to overcome their context window limitations, and demonstrate exceptional retrieval and reasoning capacities on longer context. Quesion-answering systems augmented with Long-Context Language Models (LCLMs) can automatically search massive external data and incorporate it into their contexts, enabling faithful predictions and reducing issues such as hallucinations and knowledge staleness. Existing studies targeting LCLMs mainly concentrate on addressing the so-called lost-in-the-middle problem or improving the inference effiencicy, leaving their privacy risks largely unexplored. In this paper, we aim to bridge this gap and argue that integrating all information into the long context makes it a repository of sensitive information, which often contains private data such as medical records or personal identities. We further investigate the membership privacy within LCLMs external context, with the aim of determining whether a given document or sequence is included in the LCLMs context. Our basic idea is that if a document lies in the context, it will exhibit a low generation loss or a high degree of semantic similarity to the contents generated by LCLMs. We for the first time propose six membership inference attack (MIA) strategies tailored for LCLMs and conduct extensive experiments on various popular models. Empirical results demonstrate that our attacks can accurately infer membership status in most cases, e.g., 90.66% attack F1-score on Multi-document QA datasets with LongChat-7b-v1.5-32k, highlighting significant risks of membership leakage within LCLMs input contexts. Furthermore, we examine the underlying reasons why LCLMs are susceptible to revealing such membership information.
Seeing Is Believing: Black-Box Membership Inference Attacks Against Retrieval Augmented Generation
Jun 27, 2024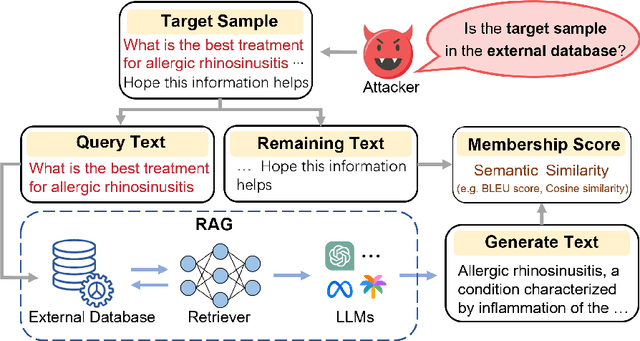
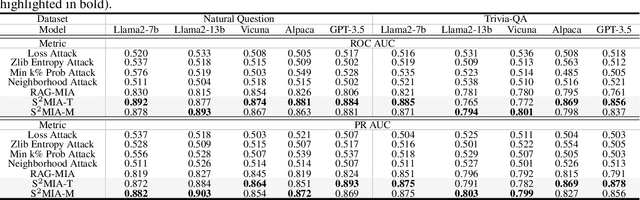
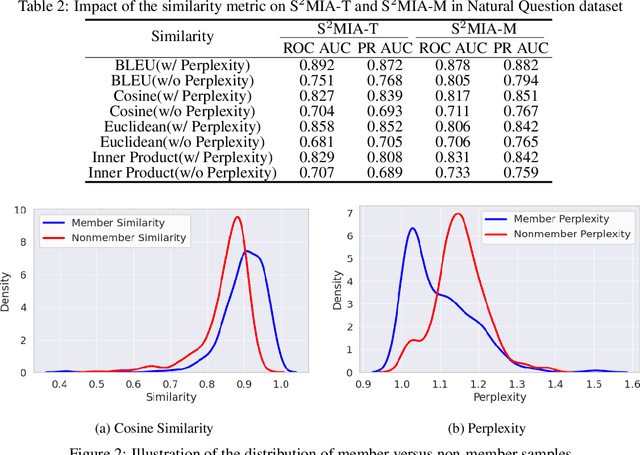
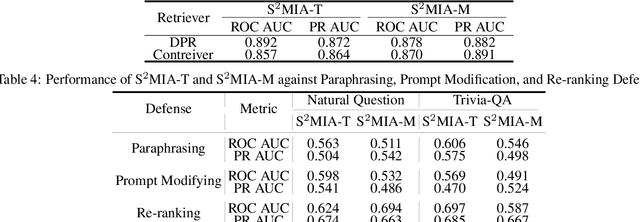
Retrieval-Augmented Generation (RAG) is a state-of-the-art technique that enhances Large Language Models (LLMs) by retrieving relevant knowledge from an external, non-parametric database. This approach aims to mitigate common LLM issues such as hallucinations and outdated knowledge. Although existing research has demonstrated security and privacy vulnerabilities within RAG systems, making them susceptible to attacks like jailbreaks and prompt injections, the security of the RAG system's external databases remains largely underexplored. In this paper, we employ Membership Inference Attacks (MIA) to determine whether a sample is part of the knowledge database of a RAG system, using only black-box API access. Our core hypothesis posits that if a sample is a member, it will exhibit significant similarity to the text generated by the RAG system. To test this, we compute the cosine similarity and the model's perplexity to establish a membership score, thereby building robust features. We then introduce two novel attack strategies: a Threshold-based Attack and a Machine Learning-based Attack, designed to accurately identify membership. Experimental validation of our methods has achieved a ROC AUC of 82%.
Boundary Unlearning
Mar 21, 2023



The practical needs of the ``right to be forgotten'' and poisoned data removal call for efficient \textit{machine unlearning} techniques, which enable machine learning models to unlearn, or to forget a fraction of training data and its lineage. Recent studies on machine unlearning for deep neural networks (DNNs) attempt to destroy the influence of the forgetting data by scrubbing the model parameters. However, it is prohibitively expensive due to the large dimension of the parameter space. In this paper, we refocus our attention from the parameter space to the decision space of the DNN model, and propose Boundary Unlearning, a rapid yet effective way to unlearn an entire class from a trained DNN model. The key idea is to shift the decision boundary of the original DNN model to imitate the decision behavior of the model retrained from scratch. We develop two novel boundary shift methods, namely Boundary Shrink and Boundary Expanding, both of which can rapidly achieve the utility and privacy guarantees. We extensively evaluate Boundary Unlearning on CIFAR-10 and Vggface2 datasets, and the results show that Boundary Unlearning can effectively forget the forgetting class on image classification and face recognition tasks, with an expected speed-up of $17\times$ and $19\times$, respectively, compared with retraining from the scratch.
Federated Unlearning
Dec 27, 2020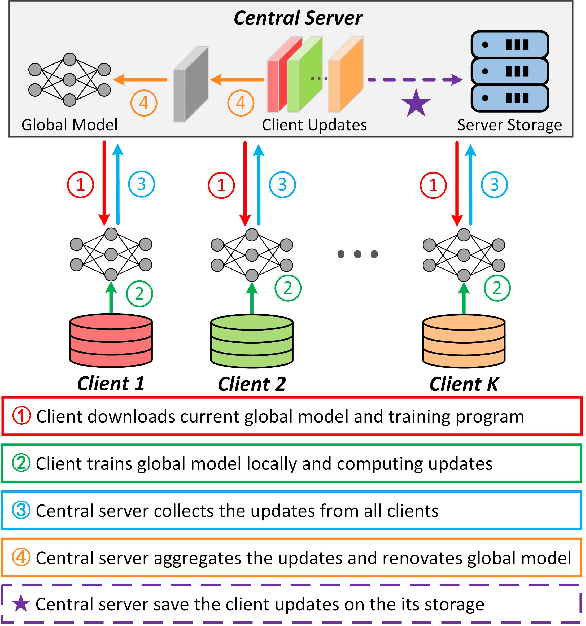
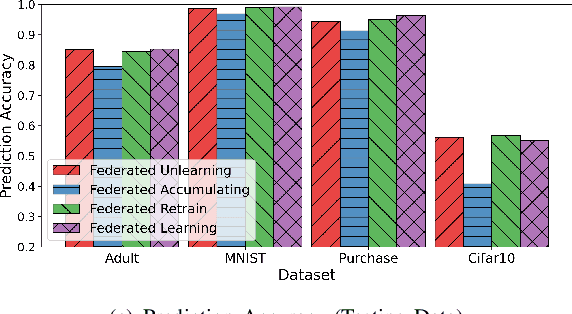
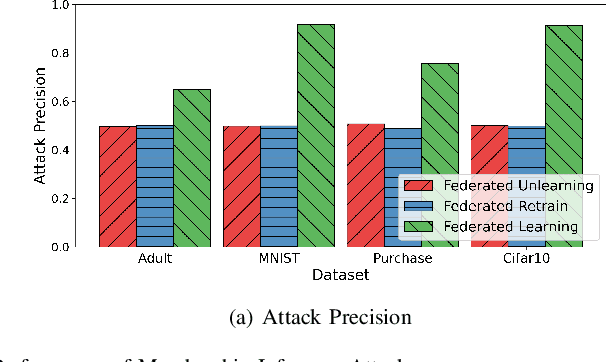
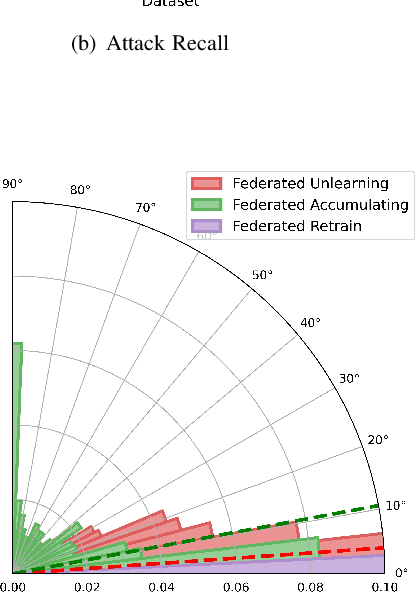
Data removal from machine learning models has been paid more attentions due to the demands of the "right to be forgotten" and countering data poisoning attacks. In this paper, we frame the problem of federated unlearning, a post-process operation of the federated learning models to remove the influence of the specified training sample(s). We present FedEraser, the first federated unlearning methodology that can eliminate the influences of a federated client's data on the global model while significantly reducing the time consumption used for constructing the unlearned model. The core idea of FedEraser is to trade the central server's storage for unlearned model's construction time. In particular, FedEraser reconstructs the unlearned model by leveraging the historical parameter updates of federated clients that have been retained at the central server during the training process of FL. A novel calibration method is further developed to calibrate the retained client updates, which can provide a significant speed-up to the reconstruction of the unlearned model. Experiments on four realistic datasets demonstrate the effectiveness of FedEraser, with an expected speed-up of $4\times$ compared with retraining from the scratch.