 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Unlearning
Paper and Code
Dec 27, 2020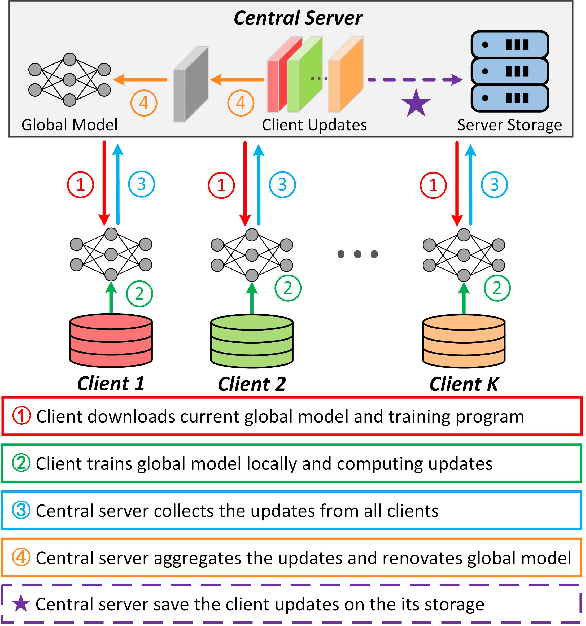
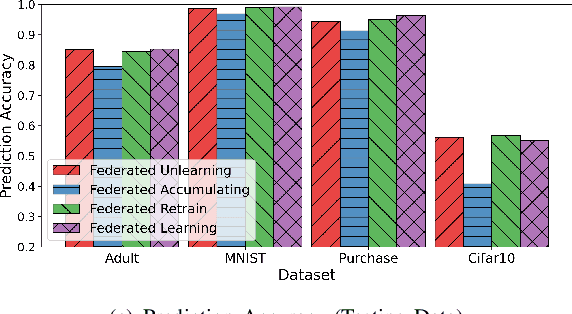
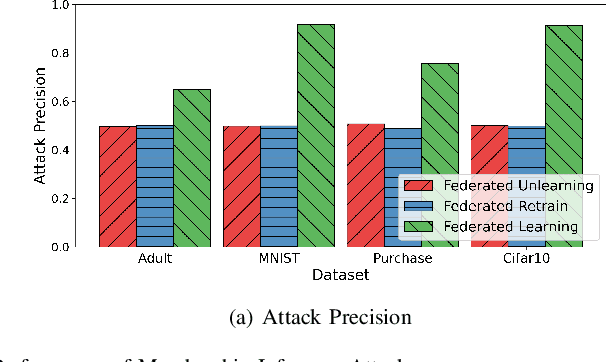
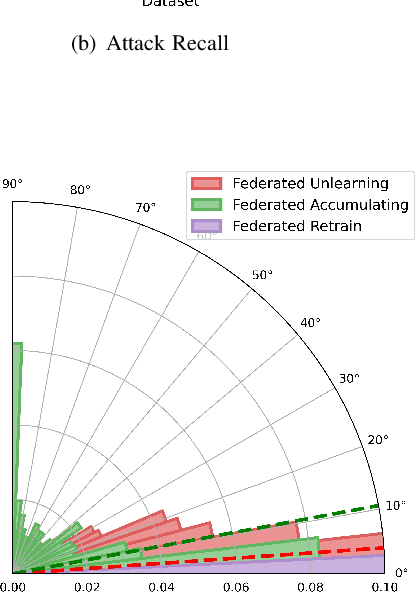
Data removal from machine learning models has been paid more attentions due to the demands of the "right to be forgotten" and countering data poisoning attacks. In this paper, we frame the problem of federated unlearning, a post-process operation of the federated learning models to remove the influence of the specified training sample(s). We present FedEraser, the first federated unlearning methodology that can eliminate the influences of a federated client's data on the global model while significantly reducing the time consumption used for constructing the unlearned model. The core idea of FedEraser is to trade the central server's storage for unlearned model's construction time. In particular, FedEraser reconstructs the unlearned model by leveraging the historical parameter updates of federated clients that have been retained at the central server during the training process of FL. A novel calibration method is further developed to calibrate the retained client updates, which can provide a significant speed-up to the reconstruction of the unlearned model. Experiments on four realistic datasets demonstrate the effectiveness of FedEraser, with an expected speed-up of $4\times$ compared with retraining from the scratch.