 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Compression and Artifact Correction for Streaming Underwater Imaging Sonar
Nov 17, 2025Real-time imaging sonar has become an important tool for underwater monitoring in environments where optical sensing is unreliable. Its broader use is constrained by two coupled challenges: highly limited uplink bandwidth and severe sonar-specific artifacts (speckle, motion blur, reverberation, acoustic shadows) that affect up to 98% of frames. We present SCOPE, a self-supervised framework that jointly performs compression and artifact correction without clean-noise pairs or synthetic assumptions. SCOPE combines (i) Adaptive Codebook Compression (ACC), which learns frequency-encoded latent representations tailored to sonar, with (ii) Frequency-Aware Multiscale Segmentation (FAMS), which decomposes frames into low-frequency structure and sparse high-frequency dynamics while suppressing rapidly fluctuating artifacts. A hedging training strategy further guides frequency-aware learning using low-pass proxy pairs generated without labels. Evaluated on months of in-situ ARIS sonar data, SCOPE achieves a structural similarity index (SSIM) of 0.77, representing a 40% improvement over prior self-supervised denoising baselines, at bitrates down to <= 0.0118 bpp. It reduces uplink bandwidth by more than 80% while improving downstream detection. The system runs in real time, with 3.1 ms encoding on an embedded GPU and 97 ms full multi-layer decoding on the server end. SCOPE has been deployed for months in three Pacific Northwest rivers to support real-time salmon enumeration and environmental monitoring in the wild. Results demonstrate that learning frequency-structured latents enables practical, low-bitrate sonar streaming with preserved signal details under real-world deployment conditions.
Federated Unlearning
Dec 27, 2020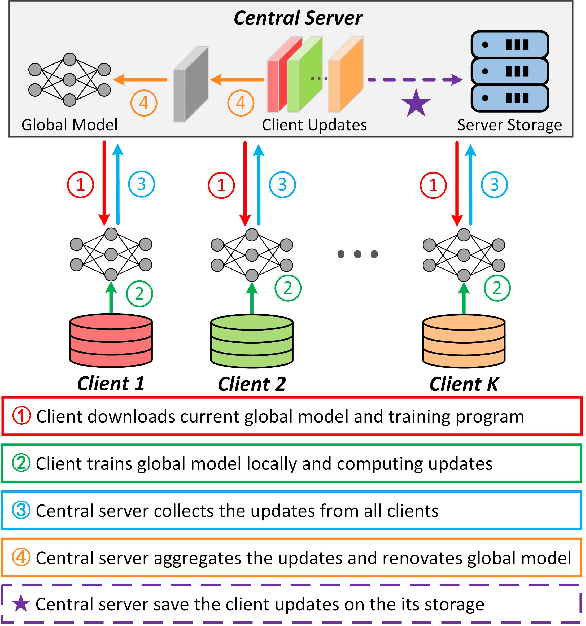
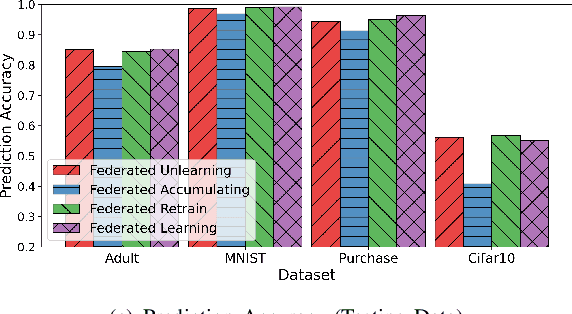
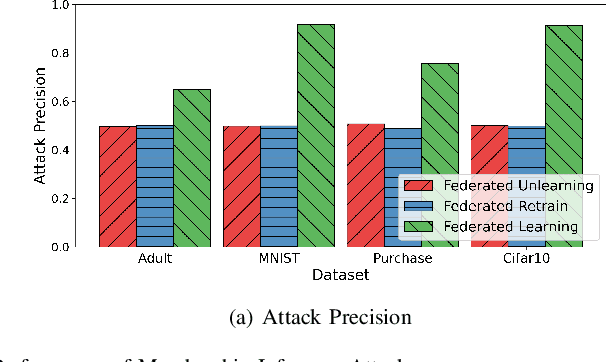
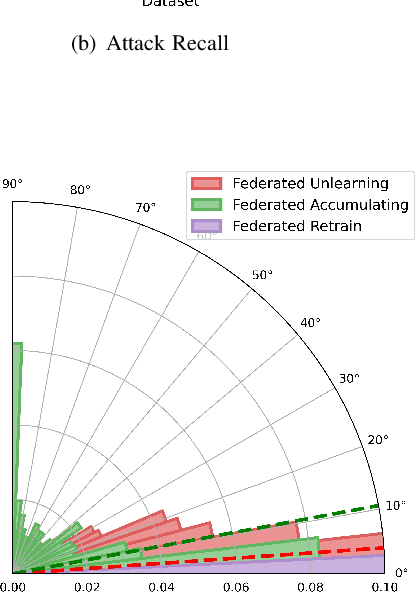
Data removal from machine learning models has been paid more attentions due to the demands of the "right to be forgotten" and countering data poisoning attacks. In this paper, we frame the problem of federated unlearning, a post-process operation of the federated learning models to remove the influence of the specified training sample(s). We present FedEraser, the first federated unlearning methodology that can eliminate the influences of a federated client's data on the global model while significantly reducing the time consumption used for constructing the unlearned model. The core idea of FedEraser is to trade the central server's storage for unlearned model's construction time. In particular, FedEraser reconstructs the unlearned model by leveraging the historical parameter updates of federated clients that have been retained at the central server during the training process of FL. A novel calibration method is further developed to calibrate the retained client updates, which can provide a significant speed-up to the reconstruction of the unlearned model. Experiments on four realistic datasets demonstrate the effectiveness of FedEraser, with an expected speed-up of $4\times$ compared with retraining from the scratch.