 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Decoding the Hook: A Multimodal LLM Framework for Analyzing the Hooking Period of Video Ads
Feb 25, 2026Video-based ads are a vital medium for brands to engage consumers, with social media platforms leveraging user data to optimize ad delivery and boost engagement. A crucial but under-explored aspect is the 'hooking period', the first three seconds that capture viewer attention and influence engagement metrics. Analyzing this brief window is challenging due to the multimodal nature of video content, which blends visual, auditory, and textual elements. Traditional methods often miss the nuanced interplay of these components, requiring advanced frameworks for thorough evaluation. This study presents a framework using transformer-based multimodal large language models (MLLMs) to analyze the hooking period of video ads. It tests two frame sampling strategies, uniform random sampling and key frame selection, to ensure balanced and representative acoustic feature extraction, capturing the full range of design elements. The hooking video is processed by state-of-the-art MLLMs to generate descriptive analyses of the ad's initial impact, which are distilled into coherent topics using BERTopic for high-level abstraction. The framework also integrates features such as audio attributes and aggregated ad targeting information, enriching the feature set for further analysis. Empirical validation on large-scale real-world data from social media platforms demonstrates the efficacy of our framework, revealing correlations between hooking period features and key performance metrics like conversion per investment. The results highlight the practical applicability and predictive power of the approach, offering valuable insights for optimizing video ad strategies. This study advances video ad analysis by providing a scalable methodology for understanding and enhancing the initial moments of video advertisements.
The Gaining Paths to Investment Success: Information-Driven LLM Graph Reasoning for Venture Capital Prediction
Dec 29, 2025Most venture capital (VC) investments fail, while a few deliver outsized returns. Accurately predicting startup success requires synthesizing complex relational evidence, including company disclosures, investor track records, and investment network structures, through explicit reasoning to form coherent, interpretable investment theses. Traditional machine learning and graph neural networks both lack this reasoning capability. Large language models (LLMs) offer strong reasoning but face a modality mismatch with graphs. Recent graph-LLM methods target in-graph tasks where answers lie within the graph, whereas VC prediction is off-graph: the target exists outside the network. The core challenge is selecting graph paths that maximize predictor performance on an external objective while enabling step-by-step reasoning. We present MIRAGE-VC, a multi-perspective retrieval-augmented generation framework that addresses two obstacles: path explosion (thousands of candidate paths overwhelm LLM context) and heterogeneous evidence fusion (different startups need different analytical emphasis). Our information-gain-driven path retriever iteratively selects high-value neighbors, distilling investment networks into compact chains for explicit reasoning. A multi-agent architecture integrates three evidence streams via a learnable gating mechanism based on company attributes. Under strict anti-leakage controls, MIRAGE-VC achieves +5.0% F1 and +16.6% PrecisionAt5, and sheds light on other off-graph prediction tasks such as recommendation and risk assessment. Code: https://anonymous.4open.science/r/MIRAGE-VC-323F.
LLM Agents as VC investors: Predicting Startup Success via RolePlay-Based Collective Simulation
Dec 27, 2025Due to the high value and high failure rate of startups, predicting their success has become a critical challenge across interdisciplinary research. Existing approaches typically model success prediction from the perspective of a single decision-maker, overlooking the collective dynamics of investor groups that dominate real-world venture capital (VC) decisions. In this paper, we propose SimVC-CAS, a novel collective agent system that simulates VC decision-making as a multi-agent interaction process. By designing role-playing agents and a GNN-based supervised interaction module, we reformulate startup financing prediction as a group decision-making task, capturing both enterprise fundamentals and the behavioral dynamics of potential investor networks. Each agent embodies an investor with unique traits and preferences, enabling heterogeneous evaluation and realistic information exchange through a graph-structured co-investment network. Using real-world data from PitchBook and under strict data leakage controls, we show that SimVC-CAS significantly improves predictive accuracy while providing interpretable, multiperspective reasoning, for example, approximately 25% relative improvement with respect to average precision@10. SimVC-CAS also sheds light on other complex group decision scenarios.
Hold Onto That Thought: Assessing KV Cache Compression On Reasoning
Dec 12, 2025Large language models (LLMs) have demonstrated remarkable performance on long-context tasks, but are often bottlenecked by memory constraints. Namely, the KV cache, which is used to significantly speed up attention computations, grows linearly with context length. A suite of compression algorithms has been introduced to alleviate cache growth by evicting unimportant tokens. However, several popular strategies are targeted towards the prefill phase, i.e., processing long prompt context, and their performance is rarely assessed on reasoning tasks requiring long decoding. In particular, short but complex prompts, such as those in benchmarks like GSM8K and MATH500, often benefit from multi-step reasoning and self-reflection, resulting in thinking sequences thousands of tokens long. In this work, we benchmark the performance of several popular compression strategies on long-reasoning tasks. For the non-reasoning Llama-3.1-8B-Instruct, we determine that no singular strategy fits all, and that performance is heavily influenced by dataset type. However, we discover that H2O and our decoding-enabled variant of SnapKV are dominant strategies for reasoning models, indicating the utility of heavy-hitter tracking for reasoning traces. We also find that eviction strategies at low budgets can produce longer reasoning traces, revealing a tradeoff between cache size and inference costs.
TreeHop: Generate and Filter Next Query Embeddings Efficiently for Multi-hop Question Answering
Apr 30, 2025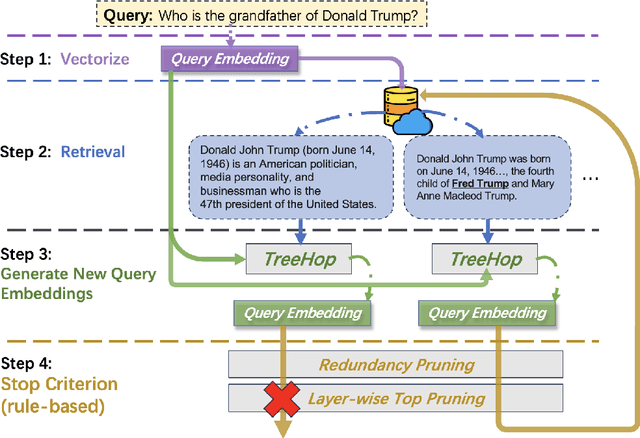

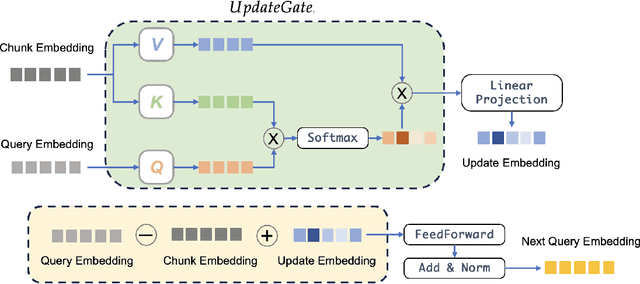

Retrieval-augmented generation (RAG) systems face significant challenges in multi-hop question answering (MHQA), where complex queries require synthesizing information across multiple document chunks. Existing approaches typically rely on iterative LLM-based query rewriting and routing, resulting in high computational costs due to repeated LLM invocations and multi-stage processes. To address these limitations, we propose TreeHop, an embedding-level framework without the need for LLMs in query refinement. TreeHop dynamically updates query embeddings by fusing semantic information from prior queries and retrieved documents, enabling iterative retrieval through embedding-space operations alone. This method replaces the traditional "Retrieve-Rewrite-Vectorize-Retrieve" cycle with a streamlined "Retrieve-Embed-Retrieve" loop, significantly reducing computational overhead. Moreover, a rule-based stop criterion is introduced to further prune redundant retrievals, balancing efficiency and recall rate. Experimental results show that TreeHop rivals advanced RAG methods across three open-domain MHQA datasets, achieving comparable performance with only 5\%-0.4\% of the model parameter size and reducing the query latency by approximately 99\% compared to concurrent approaches. This makes TreeHop a faster and more cost-effective solution for deployment in a range of knowledge-intensive applications. For reproducibility purposes, codes and data are available here: https://github.com/allen-li1231/TreeHop-RAG.
One-Point Sampling for Distributed Bandit Convex Optimization with Time-Varying Constraints
Apr 24, 2025This paper considers the distributed bandit convex optimization problem with time-varying constraints. In this problem, the global loss function is the average of all the local convex loss functions, which are unknown beforehand. Each agent iteratively makes its own decision subject to time-varying inequality constraints which can be violated but are fulfilled in the long run. For a uniformly jointly strongly connected time-varying directed graph, a distributed bandit online primal-dual projection algorithm with one-point sampling is proposed. We show that sublinear dynamic network regret and network cumulative constraint violation are achieved if the path-length of the benchmark also increases in a sublinear manner. In addition, an $\mathcal{O}({T^{3/4 + g}})$ static network regret bound and an $\mathcal{O}( {{T^{1 - {g}/2}}} )$ network cumulative constraint violation bound are established, where $T$ is the total number of iterations and $g \in ( {0,1/4} )$ is a trade-off parameter. Moreover, a reduced static network regret bound $\mathcal{O}( {{T^{2/3 + 4g /3}}} )$ is established for strongly convex local loss functions. Finally, a numerical example is presented to validate the theoretical results.
Enhancing Investment Analysis: Optimizing AI-Agent Collaboration in Financial Research
Nov 07, 2024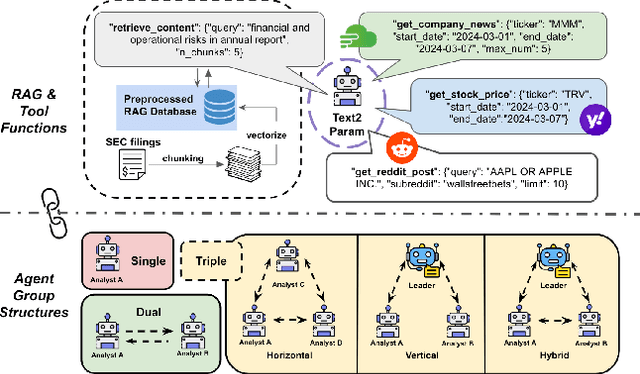
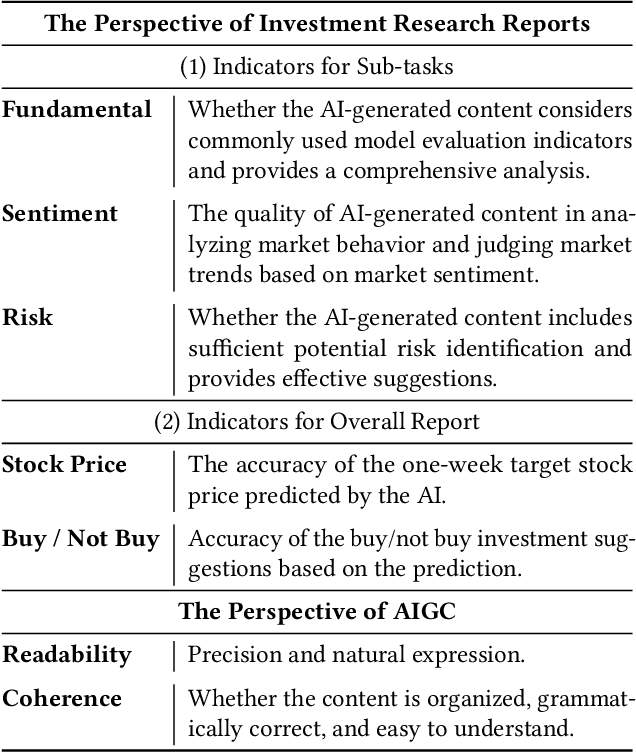
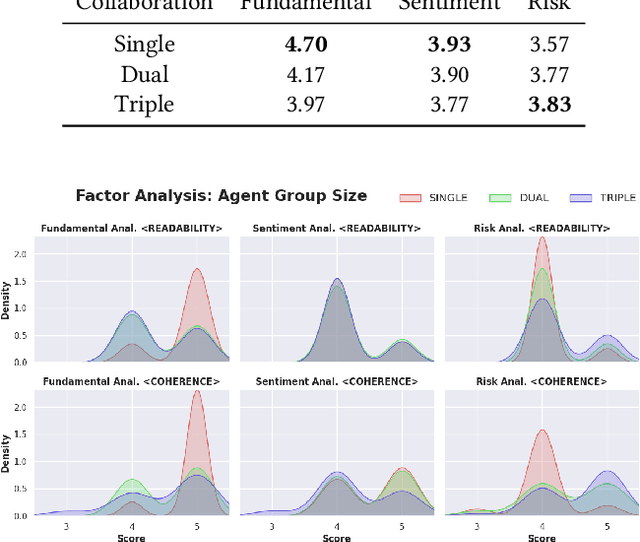
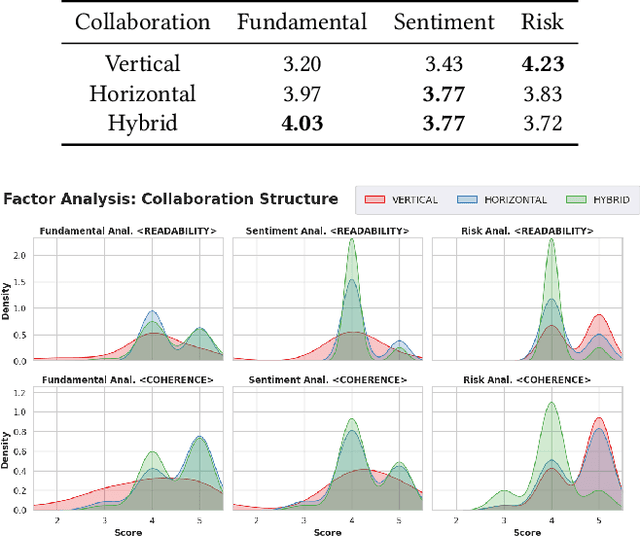
In recent years, the application of generative artificial intelligence (GenAI) in financial analysis and investment decision-making has gained significant attention. However, most existing approaches rely on single-agent systems, which fail to fully utilize the collaborative potential of multiple AI agents. In this paper, we propose a novel multi-agent collaboration system designed to enhance decision-making in financial investment research. The system incorporates agent groups with both configurable group sizes and collaboration structures to leverage the strengths of each agent group type. By utilizing a sub-optimal combination strategy, the system dynamically adapts to varying market conditions and investment scenarios, optimizing performance across different tasks. We focus on three sub-tasks: fundamentals, market sentiment, and risk analysis, by analyzing the 2023 SEC 10-K forms of 30 companies listed on the Dow Jones Index. Our findings reveal significant performance variations based on the configurations of AI agents for different tasks. The results demonstrate that our multi-agent collaboration system outperforms traditional single-agent models, offering improved accuracy, efficiency, and adaptability in complex financial environments. This study highlights the potential of multi-agent systems in transforming financial analysis and investment decision-making by integrating diverse analytical perspectives.
From Automation to Augmentation: Large Language Models Elevating Essay Scoring Landscape
Jan 12, 2024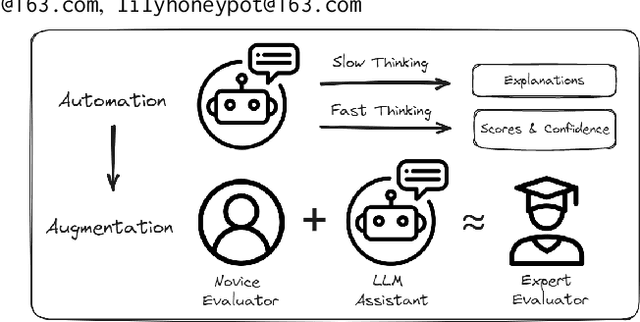
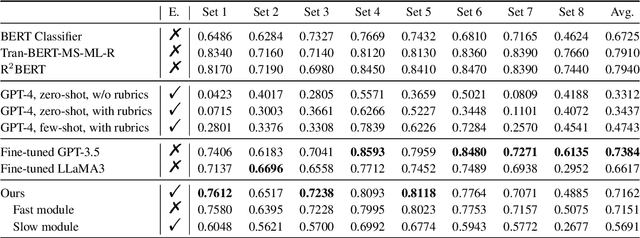

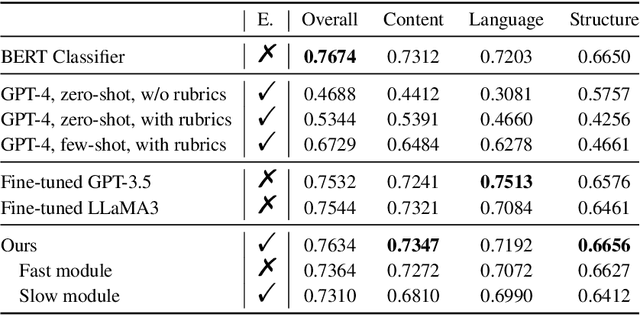
Receiving immediate and personalized feedback is crucial for second-language learners, and Automated Essay Scoring (AES) systems are a vital resource when human instructors are unavailable. This study investigates the effectiveness of Large Language Models (LLMs), specifically GPT-4 and fine-tuned GPT-3.5, as tools for AES. Our comprehensive set of experiments, conducted on both public and private datasets, highlights the remarkable advantages of LLM-based AES systems. They include superior accuracy, consistency, generalizability, and interpretability, with fine-tuned GPT-3.5 surpassing traditional grading models. Additionally, we undertake LLM-assisted human evaluation experiments involving both novice and expert graders. One pivotal discovery is that LLMs not only automate the grading process but also enhance the performance of human graders. Novice graders when provided with feedback generated by LLMs, achieve a level of accuracy on par with experts, while experts become more efficient and maintain greater consistency in their assessments. These results underscore the potential of LLMs in educational technology, paving the way for effective collaboration between humans and AI, ultimately leading to transformative learning experiences through AI-generated feedback.
Multimodal Data Augmentation for Image Captioning using Diffusion Models
May 03, 2023
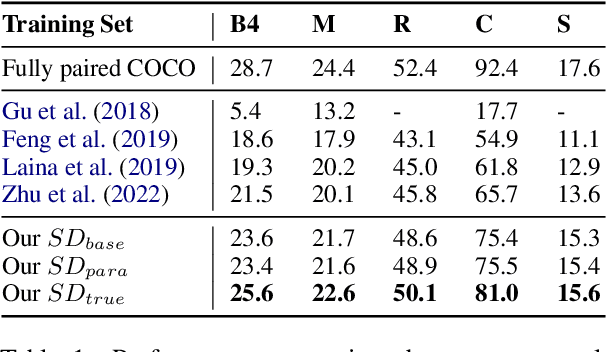
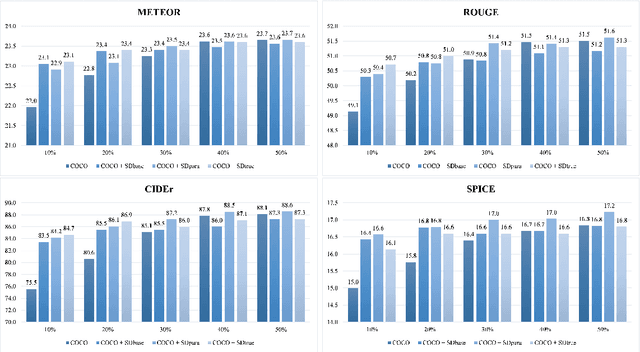
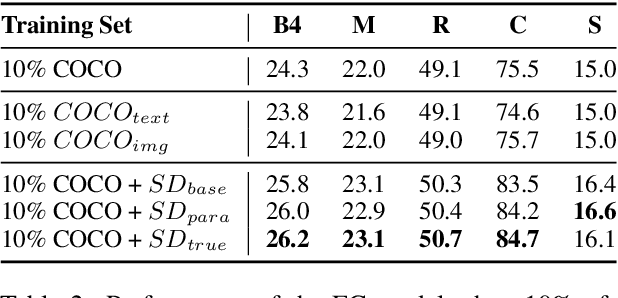
Image captioning, an important vision-language task, often requires a tremendous number of finely labeled image-caption pairs for learning the underlying alignment between images and texts. In this paper, we proposed a multimodal data augmentation method, leveraging a recent text-to-image model called Stable Diffusion, to expand the training set via high-quality generation of image-caption pairs. Extensive experiments on the MS COCO dataset demonstrate the advantages of our approach over several benchmark methods, and particularly a significant boost when having fewer training instances. In addition, models trained on our augmented datasets also outperform prior unpaired image captioning methods by a large margin. Finally, further improvement regarding the training efficiency and effectiveness can be obtained after intentionally filtering the generated data based on quality assessment.