 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Human Mobility via Self-supervised Disentanglement Learning
Nov 17, 2022Deep neural networks have recently achieved considerable improvements in learning human behavioral patterns and individual preferences from massive spatial-temporal trajectories data. However, most of the existing research concentrates on fusing different semantics underlying sequential trajectories for mobility pattern learning which, in turn, yields a narrow perspective on comprehending human intrinsic motions. In addition, the inherent sparsity and under-explored heterogeneous collaborative items pertaining to human check-ins hinder the potential exploitation of human diverse periodic regularities as well as common interests. Motivated by recent advances in disentanglement learning, in this study we propose a novel disentangled solution called SSDL for tackling the next POI prediction problem. SSDL primarily seeks to disentangle the potential time-invariant and time-varying factors into different latent spaces from massive trajectories data, providing an interpretable view to understand the intricate semantics underlying human diverse mobility representations. To address the data sparsity issue, we present two realistic trajectory augmentation approaches to enhance the understanding of both the human intrinsic periodicity and constantly-changing intents. In addition, we devise a POI-centric graph structure to explore heterogeneous collaborative signals underlying historical check-ins. Extensive experiments conducted on four real-world datasets demonstrate that our proposed SSDL significantly outperforms the state-of-the-art approaches -- for example, it yields up to 8.57% improvements on ACC@1.
CCGL: Contrastive Cascade Graph Learning
Jul 27, 2021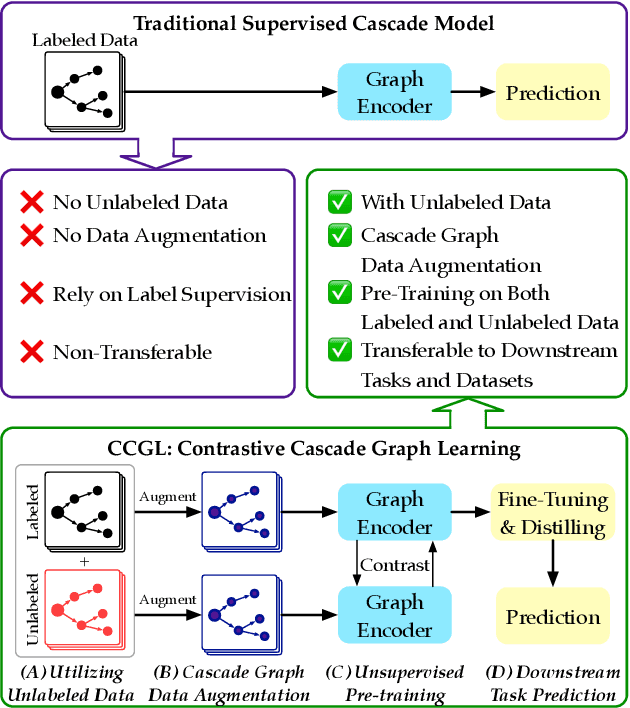
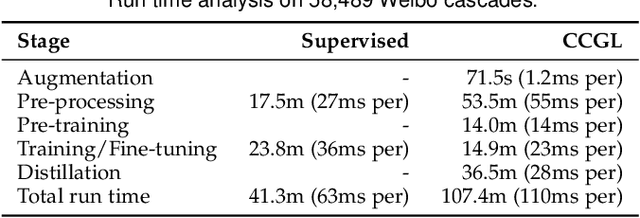
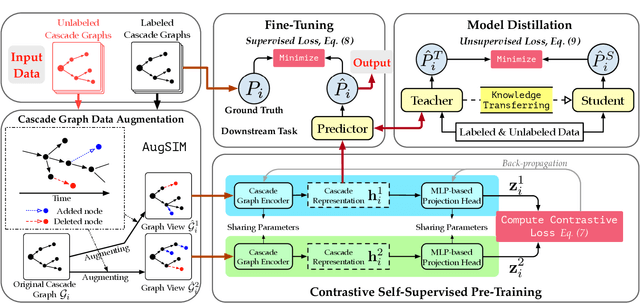
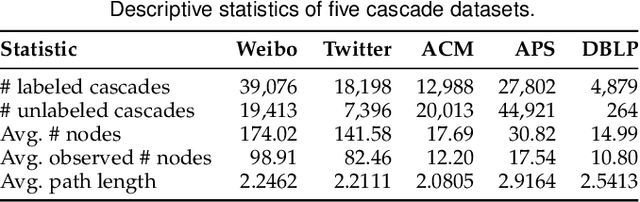
Supervised learning, while prevalent for information cascade modeling, often requires abundant labeled data in training, and the trained model is not easy to generalize across tasks and datasets. Semi-supervised learning facilitates unlabeled data for cascade understanding in pre-training. It often learns fine-grained feature-level representations, which can easily result in overfitting for downstream tasks. Recently, contrastive self-supervised learning is designed to alleviate these two fundamental issues in linguistic and visual tasks. However, its direct applicability for cascade modeling, especially graph cascade related tasks, remains underexplored. In this work, we present Contrastive Cascade Graph Learning (CCGL), a novel framework for cascade graph representation learning in a contrastive, self-supervised, and task-agnostic way. In particular, CCGL first designs an effective data augmentation strategy to capture variation and uncertainty. Second, it learns a generic model for graph cascade tasks via self-supervised contrastive pre-training using both unlabeled and labeled data. Third, CCGL learns a task-specific cascade model via fine-tuning using labeled data. Finally, to make the model transferable across datasets and cascade applications, CCGL further enhances the model via distillation using a teacher-student architecture. We demonstrate that CCGL significantly outperforms its supervised and semi-supervised counterpartsfor several downstream tasks.
A Survey of Information Cascade Analysis: Models, Predictions and Recent Advances
May 25, 2020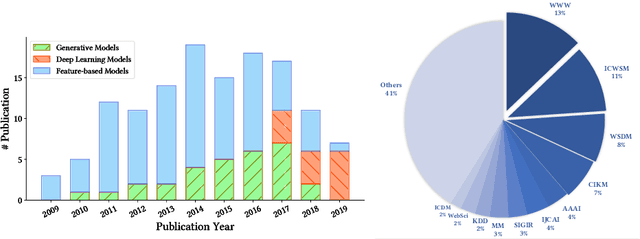
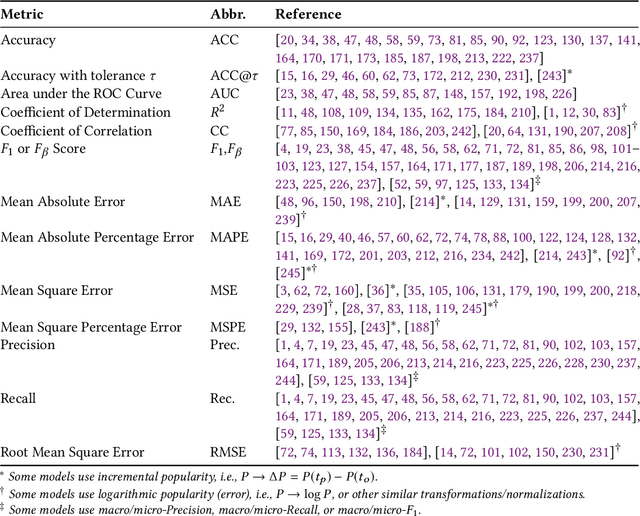
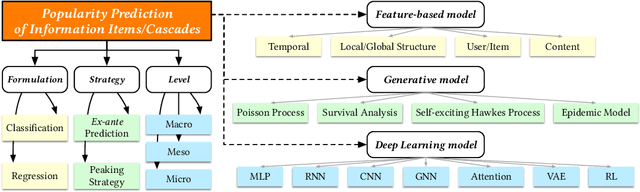

The deluge of digital information in our daily life -- from user-generated content such as microblogs and scientific papers, to online business such as viral marketing and advertising -- offers unprecedented opportunities to explore and exploit the trajectories and structures of the evolution of information cascades. Abundant research efforts, both academic and industrial, have aimed to reach a better understanding of the mechanisms driving the spread of information and quantifying the outcome of information diffusion. This article presents a comprehensive review and categorization of information popularity prediction methods, from feature engineering and stochastic processes, through graph representation, to deep learning-based approaches. Specifically, we first formally define different types of information cascades and summarize the perspectives of existing studies. We then present a taxonomy that categorizes existing works into the aforementioned three main groups as well as the main subclasses in each group, and we systematically review cutting-edge research work. Finally, we summarize the pros and cons of existing research efforts and outline the open challenges and opportunities in this field.
A Heterogeneous Dynamical Graph Neural Networks Approach to Quantify Scientific Impact
Mar 26, 2020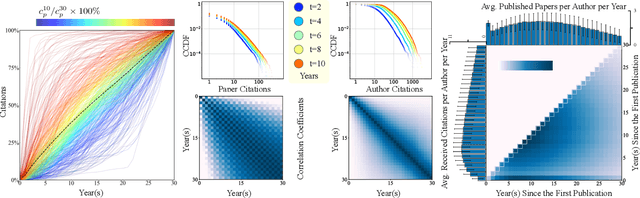
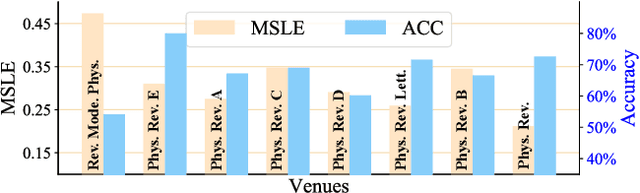
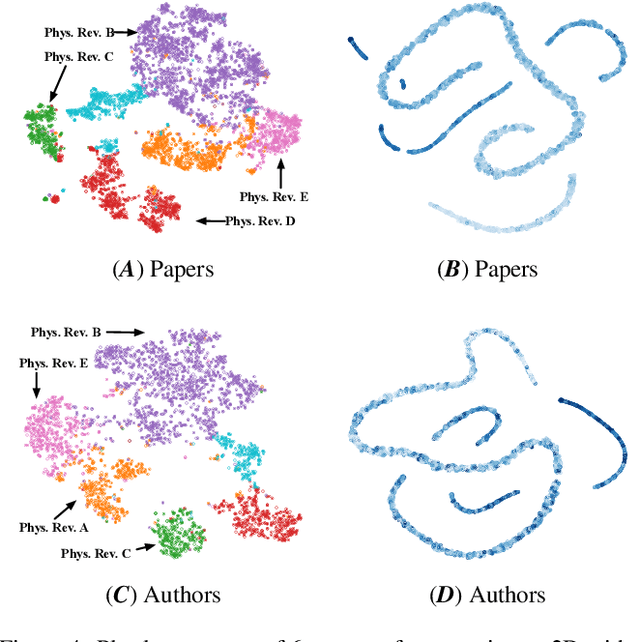
Quantifying and predicting the long-term impact of scientific writings or individual scholars has important implications for many policy decisions, such as funding proposal evaluation and identifying emerging research fields. In this work, we propose an approach based on Heterogeneous Dynamical Graph Neural Network (HDGNN) to explicitly model and predict the cumulative impact of papers and authors. HDGNN extends heterogeneous GNNs by incorporating temporally evolving characteristics and capturing both structural properties of attributed graph and the growing sequence of citation behavior. HDGNN is significantly different from previous models in its capability of modeling the node impact in a dynamic manner while taking into account the complex relations among nodes. Experiments conducted on a real citation dataset demonstrate its superior performance of predicting the impact of both papers and authors.