 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShedding the Facades, Connecting the Domains: Detecting Shifting Multimodal Hate Video with Test-Time Adaptation
Jan 28, 2026Hate Video Detection (HVD) is crucial for online ecosystems. Existing methods assume identical distributions between training (source) and inference (target) data. However, hateful content often evolves into irregular and ambiguous forms to evade censorship, resulting in substantial semantic drift and rendering previously trained models ineffective. Test-Time Adaptation (TTA) offers a solution by adapting models during inference to narrow the cross-domain gap, while conventional TTA methods target mild distribution shifts and struggle with the severe semantic drift in HVD. To tackle these challenges, we propose SCANNER, the first TTA framework tailored for HVD. Motivated by the insight that, despite the evolving nature of hateful manifestations, their underlying cores remain largely invariant (i.e., targeting is still based on characteristics like gender, race, etc), we leverage these stable cores as a bridge to connect the source and target domains. Specifically, SCANNER initially reveals the stable cores from the ambiguous layout in evolving hateful content via a principled centroid-guided alignment mechanism. To alleviate the impact of outlier-like samples that are weakly correlated with centroids during the alignment process, SCANNER enhances the prior by incorporating a sample-level adaptive centroid alignment strategy, promoting more stable adaptation. Furthermore, to mitigate semantic collapse from overly uniform outputs within clusters, SCANNER introduces an intra-cluster diversity regularization that encourages the cluster-wise semantic richness. Experiments show that SCANNER outperforms all baselines, with an average gain of 4.69% in Macro-F1 over the best.
From Shallow Humor to Metaphor: Towards Label-Free Harmful Meme Detection via LMM Agent Self-Improvement
Dec 25, 2025The proliferation of harmful memes on online media poses significant risks to public health and stability. Existing detection methods heavily rely on large-scale labeled data for training, which necessitates substantial manual annotation efforts and limits their adaptability to the continually evolving nature of harmful content. To address these challenges, we present ALARM, the first lAbeL-free hARmful Meme detection framework powered by Large Multimodal Model (LMM) agent self-improvement. The core innovation of ALARM lies in exploiting the expressive information from "shallow" memes to iteratively enhance its ability to tackle more complex and subtle ones. ALARM consists of a novel Confidence-based Explicit Meme Identification mechanism that isolates the explicit memes from the original dataset and assigns them pseudo-labels. Besides, a new Pairwise Learning Guided Agent Self-Improvement paradigm is introduced, where the explicit memes are reorganized into contrastive pairs (positive vs. negative) to refine a learner LMM agent. This agent autonomously derives high-level detection cues from these pairs, which in turn empower the agent itself to handle complex and challenging memes effectively. Experiments on three diverse datasets demonstrate the superior performance and strong adaptability of ALARM to newly evolved memes. Notably, our method even outperforms label-driven methods. These results highlight the potential of label-free frameworks as a scalable and promising solution for adapting to novel forms and topics of harmful memes in dynamic online environments.
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
DiffVQA: Video Quality Assessment Using Diffusion Feature Extractor
May 06, 2025Video Quality Assessment (VQA) aims to evaluate video quality based on perceptual distortions and human preferences. Despite the promising performance of existing methods using Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), they often struggle to align closely with human perceptions, particularly in diverse real-world scenarios. This challenge is exacerbated by the limited scale and diversity of available datasets. To address this limitation, we introduce a novel VQA framework, DiffVQA, which harnesses the robust generalization capabilities of diffusion models pre-trained on extensive datasets. Our framework adapts these models to reconstruct identical input frames through a control module. The adapted diffusion model is then used to extract semantic and distortion features from a resizing branch and a cropping branch, respectively. To enhance the model's ability to handle long-term temporal dynamics, a parallel Mamba module is introduced, which extracts temporal coherence augmented features that are merged with the diffusion features to predict the final score. Experiments across multiple datasets demonstrate DiffVQA's superior performance on intra-dataset evaluations and its exceptional generalization across datasets. These results confirm that leveraging a diffusion model as a feature extractor can offer enhanced VQA performance compared to CNN and ViT backbones.
Invertible Koopman neural operator for data-driven modeling of partial differential equations
Mar 25, 2025



Koopman operator theory is a popular candidate for data-driven modeling because it provides a global linearization representation for nonlinear dynamical systems. However, existing Koopman operator-based methods suffer from shortcomings in constructing the well-behaved observable function and its inverse and are inefficient enough when dealing with partial differential equations (PDEs). To address these issues, this paper proposes the Invertible Koopman Neural Operator (IKNO), a novel data-driven modeling approach inspired by the Koopman operator theory and neural operator. IKNO leverages an Invertible Neural Network to parameterize observable function and its inverse simultaneously under the same learnable parameters, explicitly guaranteeing the reconstruction relation, thus eliminating the dependency on the reconstruction loss, which is an essential improvement over the original Koopman Neural Operator (KNO). The structured linear matrix inspired by the Koopman operator theory is parameterized to learn the evolution of observables' low-frequency modes in the frequency space rather than directly in the observable space, sustaining IKNO is resolution-invariant like other neural operators. Moreover, with preprocessing such as interpolation and dimension expansion, IKNO can be extended to operator learning tasks defined on non-Cartesian domains. We fully support the above claims based on rich numerical and real-world examples and demonstrate the effectiveness of IKNO and superiority over other neural operators.
Snapmoji: Instant Generation of Animatable Dual-Stylized Avatars
Mar 15, 2025



The increasing popularity of personalized avatar systems, such as Snapchat Bitmojis and Apple Memojis, highlights the growing demand for digital self-representation. Despite their widespread use, existing avatar platforms face significant limitations, including restricted expressivity due to predefined assets, tedious customization processes, or inefficient rendering requirements. Addressing these shortcomings, we introduce Snapmoji, an avatar generation system that instantly creates animatable, dual-stylized avatars from a selfie. We propose Gaussian Domain Adaptation (GDA), which is pre-trained on large-scale Gaussian models using 3D data from sources such as Objaverse and fine-tuned with 2D style transfer tasks, endowing it with a rich 3D prior. This enables Snapmoji to transform a selfie into a primary stylized avatar, like the Bitmoji style, and apply a secondary style, such as Plastic Toy or Alien, all while preserving the user's identity and the primary style's integrity. Our system is capable of producing 3D Gaussian avatars that support dynamic animation, including accurate facial expression transfer. Designed for efficiency, Snapmoji achieves selfie-to-avatar conversion in just 0.9 seconds and supports real-time interactions on mobile devices at 30 to 40 frames per second. Extensive testing confirms that Snapmoji outperforms existing methods in versatility and speed, making it a convenient tool for automatic avatar creation in various styles.
Secure Resource Allocation via Constrained Deep Reinforcement Learning
Jan 20, 2025The proliferation of Internet of Things (IoT) devices and the advent of 6G technologies have introduced computationally intensive tasks that often surpass the processing capabilities of user devices. Efficient and secure resource allocation in serverless multi-cloud edge computing environments is essential for supporting these demands and advancing distributed computing. However, existing solutions frequently struggle with the complexity of multi-cloud infrastructures, robust security integration, and effective application of traditional deep reinforcement learning (DRL) techniques under system constraints. To address these challenges, we present SARMTO, a novel framework that integrates an action-constrained DRL model. SARMTO dynamically balances resource allocation, task offloading, security, and performance by utilizing a Markov decision process formulation, an adaptive security mechanism, and sophisticated optimization techniques. Extensive simulations across varying scenarios, including different task loads, data sizes, and MEC capacities, show that SARMTO consistently outperforms five baseline approaches, achieving up to a 40% reduction in system costs and a 41.5% improvement in energy efficiency over state-of-the-art methods. These enhancements highlight SARMTO's potential to revolutionize resource management in intricate distributed computing environments, opening the door to more efficient and secure IoT and edge computing applications.
MBA-RAG: a Bandit Approach for Adaptive Retrieval-Augmented Generation through Question Complexity
Dec 03, 2024



Retrieval Augmented Generation (RAG) has proven to be highly effective in boosting the generative performance of language model in knowledge-intensive tasks. However, existing RAG framework either indiscriminately perform retrieval or rely on rigid single-class classifiers to select retrieval methods, leading to inefficiencies and suboptimal performance across queries of varying complexity. To address these challenges, we propose a reinforcement learning-based framework that dynamically selects the most suitable retrieval strategy based on query complexity. % our solution Our approach leverages a multi-armed bandit algorithm, which treats each retrieval method as a distinct ``arm'' and adapts the selection process by balancing exploration and exploitation. Additionally, we introduce a dynamic reward function that balances accuracy and efficiency, penalizing methods that require more retrieval steps, even if they lead to a correct result. Our method achieves new state of the art results on multiple single-hop and multi-hop datasets while reducing retrieval costs. Our code are available at https://github.com/FUTUREEEEEE/MBA .
Enhancing Cross-Document Event Coreference Resolution by Discourse Structure and Semantic Information
Jun 23, 2024



Existing cross-document event coreference resolution models, which either compute mention similarity directly or enhance mention representation by extracting event arguments (such as location, time, agent, and patient), lacking the ability to utilize document-level information. As a result, they struggle to capture long-distance dependencies. This shortcoming leads to their underwhelming performance in determining coreference for the events where their argument information relies on long-distance dependencies. In light of these limitations, we propose the construction of document-level Rhetorical Structure Theory (RST) trees and cross-document Lexical Chains to model the structural and semantic information of documents. Subsequently, cross-document heterogeneous graphs are constructed and GAT is utilized to learn the representations of events. Finally, a pair scorer calculates the similarity between each pair of events and co-referred events can be recognized using standard clustering algorithm. Additionally, as the existing cross-document event coreference datasets are limited to English, we have developed a large-scale Chinese cross-document event coreference dataset to fill this gap, which comprises 53,066 event mentions and 4,476 clusters. After applying our model on the English and Chinese datasets respectively, it outperforms all baselines by large margins.
Harvesting Events from Multiple Sources: Towards a Cross-Document Event Extraction Paradigm
Jun 23, 2024


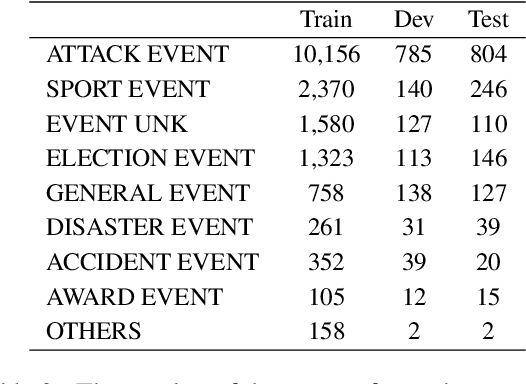
Document-level event extraction aims to extract structured event information from unstructured text. However, a single document often contains limited event information and the roles of different event arguments may be biased due to the influence of the information source. This paper addresses the limitations of traditional document-level event extraction by proposing the task of cross-document event extraction (CDEE) to integrate event information from multiple documents and provide a comprehensive perspective on events. We construct a novel cross-document event extraction dataset, namely CLES, which contains 20,059 documents and 37,688 mention-level events, where over 70% of them are cross-document. To build a benchmark, we propose a CDEE pipeline that includes 5 steps, namely event extraction, coreference resolution, entity normalization, role normalization and entity-role resolution. Our CDEE pipeline achieves about 72% F1 in end-to-end cross-document event extraction, suggesting the challenge of this task. Our work builds a new line of information extraction research and will attract new research attention.