 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-Inspired Morphological Descriptor for Soft Continuum Robots
Aug 01, 2025This paper presents a topology-inspired morphological descriptor for soft continuum robots by combining a pseudo-rigid-body (PRB) model with Morse theory to achieve a quantitative characterization of robot morphologies. By counting critical points of directional projections, the proposed descriptor enables a discrete representation of multimodal configurations and facilitates morphological classification. Furthermore, we apply the descriptor to morphology control by formulating the target configuration as an optimization problem to compute actuation parameters that generate equilibrium shapes with desired topological features. The proposed framework provides a unified methodology for quantitative morphology description, classification, and control of soft continuum robots, with the potential to enhance their precision and adaptability in medical applications such as minimally invasive surgery and endovascular interventions.
Snapmoji: Instant Generation of Animatable Dual-Stylized Avatars
Mar 15, 2025



The increasing popularity of personalized avatar systems, such as Snapchat Bitmojis and Apple Memojis, highlights the growing demand for digital self-representation. Despite their widespread use, existing avatar platforms face significant limitations, including restricted expressivity due to predefined assets, tedious customization processes, or inefficient rendering requirements. Addressing these shortcomings, we introduce Snapmoji, an avatar generation system that instantly creates animatable, dual-stylized avatars from a selfie. We propose Gaussian Domain Adaptation (GDA), which is pre-trained on large-scale Gaussian models using 3D data from sources such as Objaverse and fine-tuned with 2D style transfer tasks, endowing it with a rich 3D prior. This enables Snapmoji to transform a selfie into a primary stylized avatar, like the Bitmoji style, and apply a secondary style, such as Plastic Toy or Alien, all while preserving the user's identity and the primary style's integrity. Our system is capable of producing 3D Gaussian avatars that support dynamic animation, including accurate facial expression transfer. Designed for efficiency, Snapmoji achieves selfie-to-avatar conversion in just 0.9 seconds and supports real-time interactions on mobile devices at 30 to 40 frames per second. Extensive testing confirms that Snapmoji outperforms existing methods in versatility and speed, making it a convenient tool for automatic avatar creation in various styles.
SplatFace: Gaussian Splat Face Reconstruction Leveraging an Optimizable Surface
Mar 29, 2024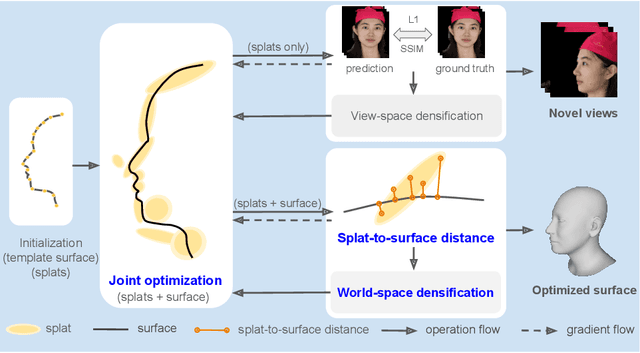
We present SplatFace, a novel Gaussian splatting framework designed for 3D human face reconstruction without reliance on accurate pre-determined geometry. Our method is designed to simultaneously deliver both high-quality novel view rendering and accurate 3D mesh reconstructions. We incorporate a generic 3D Morphable Model (3DMM) to provide a surface geometric structure, making it possible to reconstruct faces with a limited set of input images. We introduce a joint optimization strategy that refines both the Gaussians and the morphable surface through a synergistic non-rigid alignment process. A novel distance metric, splat-to-surface, is proposed to improve alignment by considering both the Gaussian position and covariance. The surface information is also utilized to incorporate a world-space densification process, resulting in superior reconstruction quality. Our experimental analysis demonstrates that the proposed method is competitive with both other Gaussian splatting techniques in novel view synthesis and other 3D reconstruction methods in producing 3D face meshes with high geometric precision.
Disjoint Pose and Shape for 3D Face Reconstruction
Aug 26, 2023



Existing methods for 3D face reconstruction from a few casually captured images employ deep learning based models along with a 3D Morphable Model(3DMM) as face geometry prior. Structure From Motion(SFM), followed by Multi-View Stereo (MVS), on the other hand, uses dozens of high-resolution images to reconstruct accurate 3D faces.However, it produces noisy and stretched-out results with only two views available. In this paper, taking inspiration from both these methods, we propose an end-to-end pipeline that disjointly solves for pose and shape to make the optimization stable and accurate. We use a face shape prior to estimate face pose and use stereo matching followed by a 3DMM to solve for the shape. The proposed method achieves end-to-end topological consistency, enables iterative face pose refinement procedure, and show remarkable improvement on both quantitative and qualitative results over existing state-of-the-art methods.
PeerGAN: Generative Adversarial Networks with a Competing Peer Discriminator
Jan 19, 2021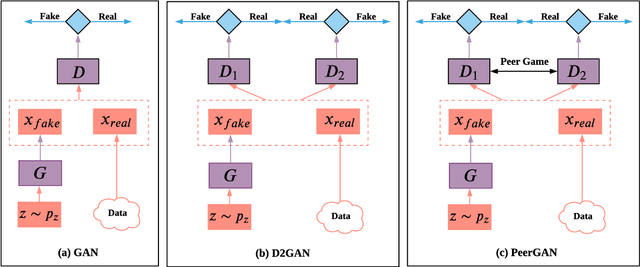

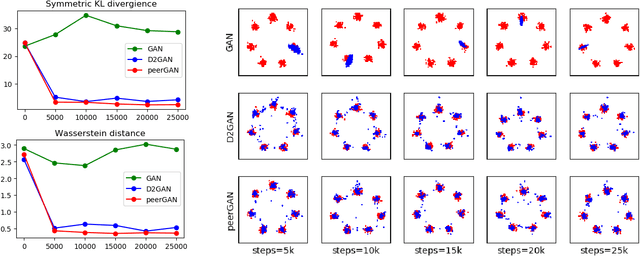

In this paper, we introduce PeerGAN, a generative adversarial network (GAN) solution to improve the stability of the generated samples and to mitigate mode collapse. Built upon the Vanilla GAN's two-player game between the discriminator $D_1$ and the generator $G$, we introduce a peer discriminator $D_2$ to the min-max game. Similar to previous work using two discriminators, the first role of both $D_1$, $D_2$ is to distinguish between generated samples and real ones, while the generator tries to generate high-quality samples that are able to fool both discriminators. Different from existing methods, we introduce another game between $D_1$ and $D_2$ to discourage their agreement and therefore increase the level of diversity of the generated samples. This property helps avoid early mode collapse by preventing $D_1$ and $D_2$ from converging too fast. We provide theoretical analysis for the equilibrium of the min-max game formed among $G, D_1, D_2$. We offer convergence behavior of PeerGAN as well as stability of the min-max game. It's worth mentioning that PeerGAN operates in the unsupervised setting, and the additional game between $D_1$ and $D_2$ does not need any label supervision. Experiments results on a synthetic dataset and on real-world image datasets (MNIST, Fashion MNIST, CIFAR-10, STL-10, CelebA, VGG) demonstrate that PeerGAN outperforms competitive baseline work in generating diverse and high-quality samples, while only introduces negligible computation cost.