 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMilliVid: Hierarchical Latents for Long-Range Consistency in Video Generation
Jun 08, 2026Video generative models have become increasingly powerful, but long-range consistency remains challenging to achieve because even a few dozen frames require impractically long transformer sequence lengths. We show that this issue can be mitigated by generating video using coarse-to-fine rollout within a multi-scale token space. Our approach is simple: first, we pre-train an autoencoder that compresses each frame into a hierarchy of tokens, with levels ranging from the typical latent resolution to only a handful of tokens per frame. The coarsest levels capture the most consequential information, such as scene layout and semantics, while finer levels add high-frequency appearance and texture. Then, we train a video diffusion model to generate these tokens using coarse-to-fine rollout. By carefully controlling the level of detail at which frames are generated and used as context during each rollout step, we are able to preserve long-range consistency in geometry and object permanence while spending less compute on the long-range consistency of less perceptually relevant details. We validate this approach using a custom dataset of long Minecraft videos, where it produces substantially more consistent rollouts compared to existing baselines.
Turning Video Models into Generalist Robot Policies
May 27, 2026Video generative models have emerged as a promising robotics backbone, capable of generating videos that depict the completion of complex tasks across embodiments and environments. Recent work proposes robot foundation models that jointly predict future observations and actions by finetuning video models with action-labeled data. In this paper, we test the limits of an alternative approach: leave the video planner as-is while training an embodiment-specific inverse dynamics model (IDM). This decoupling offers several natural benefits: the video planner remains embodiment-agnostic, different video models can be interchanged easily without re-training the IDM, and the IDM can be independently trained with readily available self-play data. We present a closed-loop, video-to-action policy that combines an action-free video world model with a carefully-designed IDM based on the robot embodiment Jacobian. We demonstrate that our IDM design is both data-efficient and scalable to high-dimensional action spaces. Our policy, which we coin the Video-to-Embodied Robot Action Model (VERA), achieves strong performance across simulated and real-world benchmarks, including zero-shot Panda arm manipulation and 16-DoF Allegro-hand dexterous cube re-orientation. The same video planner can be used across multiple embodiments by pairing it with different embodiment-specific IDMs. Our results show that decoupled video planning plus faithful video-to-action translation is a viable alternative route towards zero-shot, cross-embodiment, and generalizable robot control. More results are available on our project website: https://vera.csail.mit.edu.
Meschers: Geometry Processing of Impossible Objects
May 14, 2026Impossible objects, geometric constructions that humans can perceive but that cannot exist in real life, have been a topic of intrigue in visual arts, perception, and graphics, yet no satisfying computer representation of such objects exists. Previous work embeds impossible objects in 3D, cutting them or twisting/bending them in the depth axis. Cutting an impossible object changes its local geometry at the cut, which can hamper downstream graphics applications, such as smoothing, while bending makes it difficult to relight the object. Both of these can invalidate geometry operations, such as distance computation. As an alternative, we introduce Meschers, meshes capable of representing impossible constructions akin to those found in M.C. Escher's woodcuts. Our representation has a theoretical foundation in discrete exterior calculus and supports the use-cases above, as we demonstrate in a number of example applications. Moreover, because we can do discrete geometry processing on our representation, we can inverse-render impossible objects. We also compare our representation to cut and bend representations of impossible objects.
Scaling View Synthesis Transformers
Feb 24, 2026Geometry-free view synthesis transformers have recently achieved state-of-the-art performance in Novel View Synthesis (NVS), outperforming traditional approaches that rely on explicit geometry modeling. Yet the factors governing their scaling with compute remain unclear. We present a systematic study of scaling laws for view synthesis transformers and derive design principles for training compute-optimal NVS models. Contrary to prior findings, we show that encoder-decoder architectures can be compute-optimal; we trace earlier negative results to suboptimal architectural choices and comparisons across unequal training compute budgets. Across several compute levels, we demonstrate that our encoder-decoder architecture, which we call the Scalable View Synthesis Model (SVSM), scales as effectively as decoder-only models, achieves a superior performance-compute Pareto frontier, and surpasses the previous state-of-the-art on real-world NVS benchmarks with substantially reduced training compute.
* Project page: https://www.evn.kim/research/svsm
Large Video Planner Enables Generalizable Robot Control
Dec 17, 2025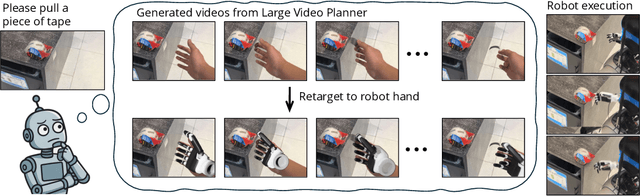
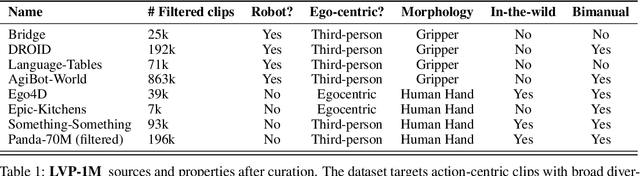

General-purpose robots require decision-making models that generalize across diverse tasks and environments. Recent works build robot foundation models by extending multimodal large language models (MLLMs) with action outputs, creating vision-language-action (VLA) systems. These efforts are motivated by the intuition that MLLMs' large-scale language and image pretraining can be effectively transferred to the action output modality. In this work, we explore an alternative paradigm of using large-scale video pretraining as a primary modality for building robot foundation models. Unlike static images and language, videos capture spatio-temporal sequences of states and actions in the physical world that are naturally aligned with robotic behavior. We curate an internet-scale video dataset of human activities and task demonstrations, and train, for the first time at a foundation-model scale, an open video model for generative robotics planning. The model produces zero-shot video plans for novel scenes and tasks, which we post-process to extract executable robot actions. We evaluate task-level generalization through third-party selected tasks in the wild and real-robot experiments, demonstrating successful physical execution. Together, these results show robust instruction following, strong generalization, and real-world feasibility. We release both the model and dataset to support open, reproducible video-based robot learning. Our website is available at https://www.boyuan.space/large-video-planner/.
Selective Underfitting in Diffusion Models
Oct 01, 2025Diffusion models have emerged as the principal paradigm for generative modeling across various domains. During training, they learn the score function, which in turn is used to generate samples at inference. They raise a basic yet unsolved question: which score do they actually learn? In principle, a diffusion model that matches the empirical score in the entire data space would simply reproduce the training data, failing to generate novel samples. Recent work addresses this question by arguing that diffusion models underfit the empirical score due to training-time inductive biases. In this work, we refine this perspective, introducing the notion of selective underfitting: instead of underfitting the score everywhere, better diffusion models more accurately approximate the score in certain regions of input space, while underfitting it in others. We characterize these regions and design empirical interventions to validate our perspective. Our results establish that selective underfitting is essential for understanding diffusion models, yielding new, testable insights into their generalization and generative performance.
Locality in Image Diffusion Models Emerges from Data Statistics
Sep 11, 2025



Among generative models, diffusion models are uniquely intriguing due to the existence of a closed-form optimal minimizer of their training objective, often referred to as the optimal denoiser. However, diffusion using this optimal denoiser merely reproduces images in the training set and hence fails to capture the behavior of deep diffusion models. Recent work has attempted to characterize this gap between the optimal denoiser and deep diffusion models, proposing analytical, training-free models that can generate images that resemble those generated by a trained UNet. The best-performing method hypothesizes that shift equivariance and locality inductive biases of convolutional neural networks are the cause of the performance gap, hence incorporating these assumptions into its analytical model. In this work, we present evidence that the locality in deep diffusion models emerges as a statistical property of the image dataset, not due to the inductive bias of convolutional neural networks. Specifically, we demonstrate that an optimal parametric linear denoiser exhibits similar locality properties to the deep neural denoisers. We further show, both theoretically and experimentally, that this locality arises directly from the pixel correlations present in natural image datasets. Finally, we use these insights to craft an analytical denoiser that better matches scores predicted by a deep diffusion model than the prior expert-crafted alternative.
Snapmoji: Instant Generation of Animatable Dual-Stylized Avatars
Mar 15, 2025



The increasing popularity of personalized avatar systems, such as Snapchat Bitmojis and Apple Memojis, highlights the growing demand for digital self-representation. Despite their widespread use, existing avatar platforms face significant limitations, including restricted expressivity due to predefined assets, tedious customization processes, or inefficient rendering requirements. Addressing these shortcomings, we introduce Snapmoji, an avatar generation system that instantly creates animatable, dual-stylized avatars from a selfie. We propose Gaussian Domain Adaptation (GDA), which is pre-trained on large-scale Gaussian models using 3D data from sources such as Objaverse and fine-tuned with 2D style transfer tasks, endowing it with a rich 3D prior. This enables Snapmoji to transform a selfie into a primary stylized avatar, like the Bitmoji style, and apply a secondary style, such as Plastic Toy or Alien, all while preserving the user's identity and the primary style's integrity. Our system is capable of producing 3D Gaussian avatars that support dynamic animation, including accurate facial expression transfer. Designed for efficiency, Snapmoji achieves selfie-to-avatar conversion in just 0.9 seconds and supports real-time interactions on mobile devices at 30 to 40 frames per second. Extensive testing confirms that Snapmoji outperforms existing methods in versatility and speed, making it a convenient tool for automatic avatar creation in various styles.
History-Guided Video Diffusion
Feb 10, 2025
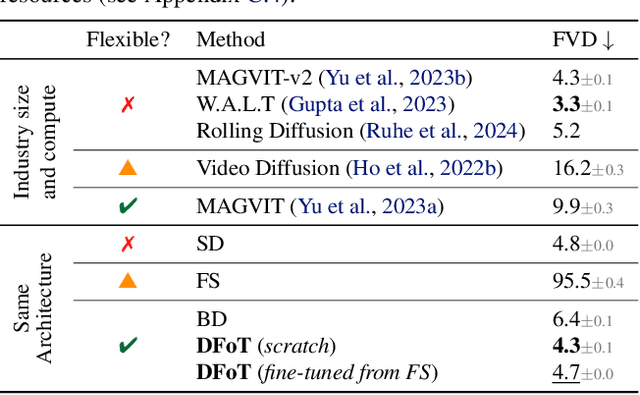
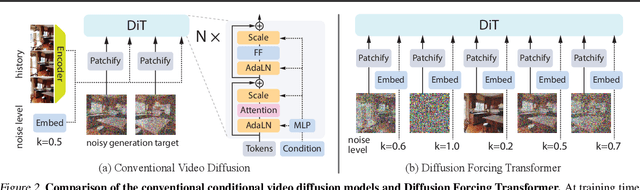
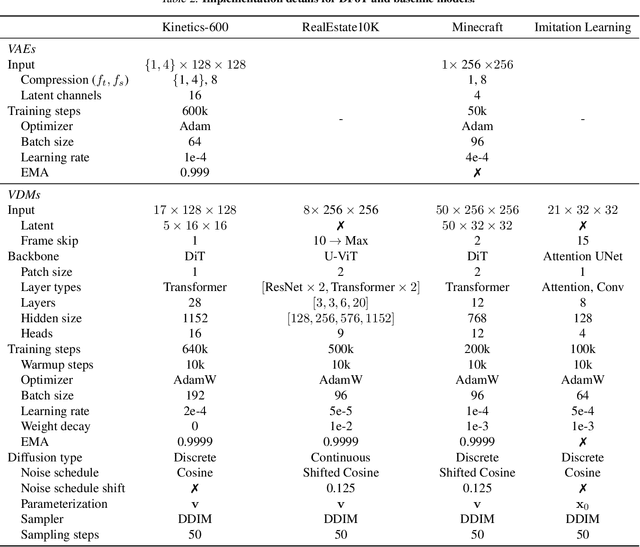
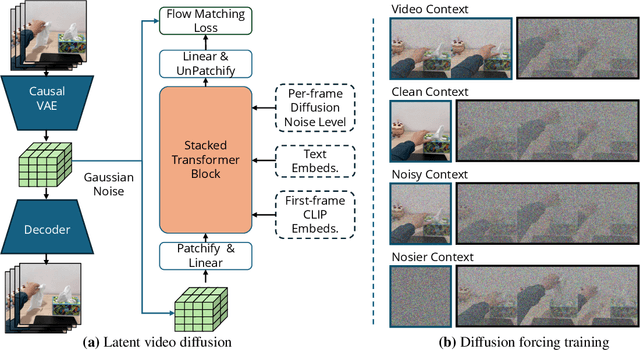
Classifier-free guidance (CFG) is a key technique for improving conditional generation in diffusion models, enabling more accurate control while enhancing sample quality. It is natural to extend this technique to video diffusion, which generates video conditioned on a variable number of context frames, collectively referred to as history. However, we find two key challenges to guiding with variable-length history: architectures that only support fixed-size conditioning, and the empirical observation that CFG-style history dropout performs poorly. To address this, we propose the Diffusion Forcing Transformer (DFoT), a video diffusion architecture and theoretically grounded training objective that jointly enable conditioning on a flexible number of history frames. We then introduce History Guidance, a family of guidance methods uniquely enabled by DFoT. We show that its simplest form, vanilla history guidance, already significantly improves video generation quality and temporal consistency. A more advanced method, history guidance across time and frequency further enhances motion dynamics, enables compositional generalization to out-of-distribution history, and can stably roll out extremely long videos. Website: https://boyuan.space/history-guidance
Unifying 3D Representation and Control of Diverse Robots with a Single Camera
Jul 11, 2024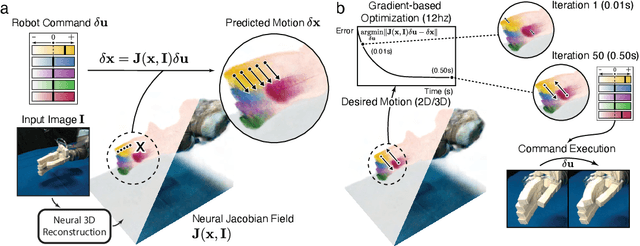
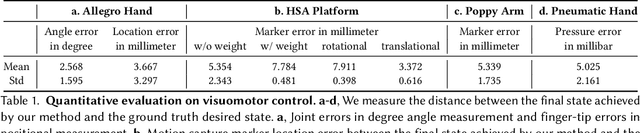
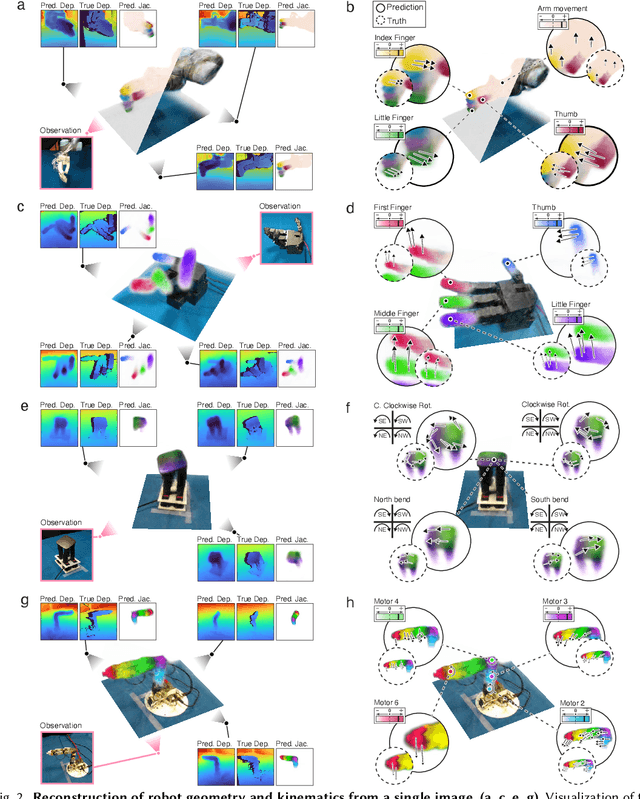

Mirroring the complex structures and diverse functions of natural organisms is a long-standing challenge in robotics. Modern fabrication techniques have dramatically expanded feasible hardware, yet deploying these systems requires control software to translate desired motions into actuator commands. While conventional robots can easily be modeled as rigid links connected via joints, it remains an open challenge to model and control bio-inspired robots that are often multi-material or soft, lack sensing capabilities, and may change their material properties with use. Here, we introduce Neural Jacobian Fields, an architecture that autonomously learns to model and control robots from vision alone. Our approach makes no assumptions about the robot's materials, actuation, or sensing, requires only a single camera for control, and learns to control the robot without expert intervention by observing the execution of random commands. We demonstrate our method on a diverse set of robot manipulators, varying in actuation, materials, fabrication, and cost. Our approach achieves accurate closed-loop control and recovers the causal dynamic structure of each robot. By enabling robot control with a generic camera as the only sensor, we anticipate our work will dramatically broaden the design space of robotic systems and serve as a starting point for lowering the barrier to robotic automation.